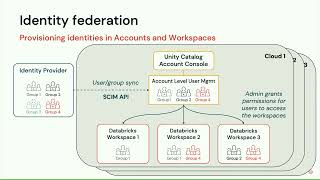
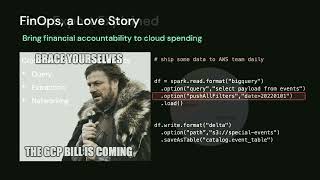
Data Engineers love data and business users need outcomes. How do we cross the chasm? While there is no dearth of data in today’s world, managing and analyzing large datasets can be daunting. Additionally, data may lose its value over time. It needs to be analyzed and acted upon quickly, to accelerate decision-making, and help realize business outcomes faster.
Take a deep dive into the future of the data economy and learn how to drive 50 times faster time to value. Hear from United Airlines how they leveraged Gathr to process massive volumes of complex digital interactions and operational data, to create breakthroughs in operations and customer experience, in real time.
The session will feature a live-demo, showcasing how enterprises from across domains leverage Gathr’s machine learning powered zero-code applications for ingestion, ETL, ML, XOps, Cloud Cost Control, Business Process Automation, and more – to accelerate their journey from data to outcomes, like never before.
Talk by: Sameer Bhide and Sarang Bapat
Here’s more to explore:
LLM Compact Guide: https://dbricks.co/43WuQyb
Big Book of MLOps: https://dbricks.co/3r0Pqiz
Connect with us: Website: https://databricks.com
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/databricks
Instagram: https://www.instagram.com/databricksinc
Facebook: https://www.facebook.com/databricksin