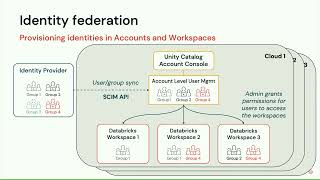
The biggest critical factor to success in a cloud transformation is people. As such, having a change management process in place to manage the impact of the transformation and user enablement is foundational to any large program. In this session, we will dive into how TD bank democratizes data, mobilizes a community of over 2000 analytics users and the tactics we used to successfully enable new use cases on Cloud. The session will focus on the following:
To democratize data: - Centralize a data platform that is accessible to all employees and allow for easy data sharing - Implement privacy and security to protect data and use data ethically - Compliance and governance for using data in responsible and compliant way - Simplification of processes and procedures to reduce redundancy and faster adoption
To mobilize end users: - Increase data literacy: provide training and resources for employees to increase their abilities and skills - Foster a culture of collaboration and openness: cross-functional teams to collaborate and share ideas - Encourage exploration of innovative ideas that impact the organization's values and customers technical enablement and adoption tactics we've used at TD Bank:
- Hands-on training for over 1300+ analytics users with emphasis on learn by doing, to relate to real-life situations
- Online tutorials and documentations to be used as self-paced study
- Workshops and office hours on specific topics to empower business users
- Coaching to work with teams on a specific use case/complex issue and provide recommendations for a faster, cost effective solutions
- Offer certification and encourage continuous education for employees to keep up to date with latest
- Feedback loop: get user feedback on training and user experience to improve future trainings
Talk by: Ellie Hajarian
Here’s more to explore: State of Data + AI Report: https://dbricks.co/44i2HBp The Data Team's Guide to the Databricks Lakehouse Platform: https://dbricks.co/46nuDpI
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc