by
Noritaka Sekiyama
(Amazon Web Services (AWS))
,
Venkatesh Aravamudan
(Amazon Web Services (AWS))
,
Neela Kulkarni
(AWS)
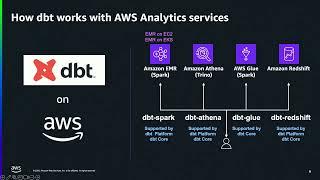
As organizations increasingly adopt modern data stacks, the combination of dbt and AWS Analytics services emerged as a powerful pairing for analytics engineering at scale. This session will explore proven strategies and hard-learned lessons for optimizing this technology stack to use dbt-athena, dbt-redshift, and dbt-glue to deliver reliable, performant data transformations. We will also cover case studies, best practices, and modern lakehouse scenarios with Apache Iceberg and Amazon S3 Tables.