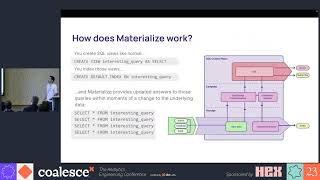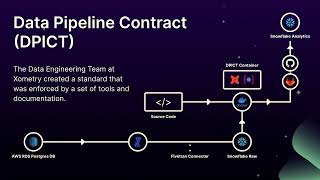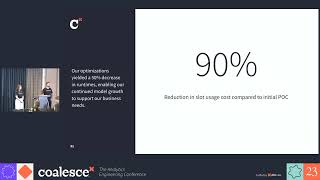
Behind any good DataOps within a Modern Data Stack (MDS) architecture is a solid DevOps design! This is particularly pressing when building an MDS solution at scale, as reliability, quality and availability of data requires a very high degree of process automation while remaining fast, agile and resilient to change when addressing business needs.
While DevOps in Data Engineering is nothing new - for a broad-spectrum solution that includes data warehouse, BI, etc seemed either a bit out of reach due to overall complexity and cost - or simply overlooked due to perceived issues around scaling often attributed to the challenges of automation in CI/CD processes. However, this has been fast changing with tools such as dbt having super cool features which allow a very high degree of autonomy in the CI/CD processes with relative ease, with flexible and cutting edge features around pre-commits, Slim CI, etc.
In this session, Datatonic covers the challenges around building and deploying enterprise-grade MDS solutions for analytics at scale and how they have used dbt to address those - especially around near-complete autonomy to the CI/CD processes!
Speaker: Ash Sultan, Lead Data Architect, Datatonic
Register for Coalesce at https://coalesce.getdbt.com