Adam's presentation explores why modern data teams are turning their data warehouse into the core of a Composable Customer Data Platform.
 talk-data.com
talk-data.com
Topic
DWH
Data Warehouse
analytics
business_intelligence
data_storage
568
tagged
Activity Trend
35
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Engineering Books
143
Data Engineering Podcast
127
Databricks DATA + AI Summit 2023
50
O'Reilly Data Science Books
34
Data + AI Summit 2025
27
O'Reilly Business Intelligence Books
24
Secrets of Data Analytics Leaders
15
DataFramed
13
dbt Coalesce 2023
12
AWS re:Invent 2024
7
O'Reilly SQL Books
7
Big Data LDN 2025
6
Data and marketing are often treated as separate functions, but the real opportunity lies in bringing them together. In this fireside chat, Ed (Data Solutions Manager at DinMo) interviews Andrew (Head of Marketing at Brand Alley), who brings a rare dual perspective: before leading marketing, he founded and scaled a data tool for dynamic audience segmentation.
They’ll explore why data and marketing are natural teammates and how aligning the two can unlock powerful business outcomes. From enabling real-time audience activation to translating data capabilities into campaigns that drive measurable growth, the discussion will highlight practical ways to bridge the gap between teams.
Attendees will discover how to maximise the ROI of their data warehouse by embedding it into marketing workflows, ensuring data initiatives deliver clear returns through hyper-personalised customer journeys. They will walk away with actionable insights on how to make data indispensable to marketing, prove its commercial value, and create experiences that drive long-term growth.
A paradigm shift is underway; the primary consumer of data is evolving from human analysts to AI agents. This presents a strategic challenge to every data leader: how do we architect an ecosystem that satisfies relentless, machine-scale demand for governed data without overwhelming our most valuable human experts? A chaotic free-for-all, with AI agents querying sources directly, is a regression that would erase a decade of progress in data warehousing and governance.
To solve this machine-scale problem, we must deploy a machine-scale solution. This session casts a vision for the future, exploring why current models are ill-equipped for the AI era. We will introduce the concept of the virtual data engineer—an AI-powered partner designed to augment and accelerate human capabilities on a collaborative platform. Discover how to evolve your team and architecture to turn this challenge into a strategic advantage, ensuring you lead the way through this transformation.
The data landscape is fickle, and once-coveted roles like 'DBA' and 'Data Scientist' have faced challenges. Now, the spotlight shines on Data Engineers, but will they suffer the same fate? This talk dives into historical trends.
In the early 2010’s, DBA/data warehouse was the sexiest job. Data Warehouse became the “No Team.”
In the mid-2010’s, data scientist was the sexiest job. Data Science became the “mistaken for” team.
Now, data engineering is the sexiest job. Data Engineering became the “confused team”. The confusion run rampant with questions about the industry: What is a data engineer? What do they do? Should we have all kinds of nuanced titles for variations? Just how technical should they be?
Together, let’s go back to history and look for ways on how data engineering can avoid the same fate as data warehousing and data science. This talk provides a thought-provoking discussion on navigating the exciting yet challenging world of data engineering. Let's avoid the pitfalls of the past and shape a future where data engineers thrive as essential drivers of innovation and success.
So you’ve heard of Databricks, but still not sure what the fuss is all about. Yes you’ve heard it’s Spark, but then there’s this Delta thing that’s both a data lake and a data warehouse (isn’t that what Iceberg is?) And then there's Unity Catalog, that's not just a catalog, it also does access management but even surprising things like optimise your data and programmatic access to lineage and billing? But then serverless came out and now you don’t even have to learn Spark? And of course there’s a bunch of AI stuff to use or create yourself. So why not spend 30 mins learning the details of what Databricks does, and how it can turn you into a rockstar Data Engineer.
Hoe zorg je ervoor dat je data sneller, betrouwbaarder en met minder handmatige werkzaamheden beschikbaar is voor analyse? Anne Marthe den Hartog (Aviation & Business Intelligence specialist) en Wim Fieret (Data & Analytics specialist) van Rotterdam The Hague Airport vertellen hoe zij de overstap maakten van hun oude manier van datavoorbereiding naar een low-code datafundament met TimeXtender. Tijdens deze sessie delen ze hun ervaringen en praktische voordelen die deze nieuwe werkwijze oplevert.
Veel organisaties worstelen met een versnipperd datalandschap vol scripts en ETL-tooling die alleen door experts begrepen wordt. Ploeger Logistics laat zien dat het anders kan. Samen met Infotopics migreerde de logistiek dienstverlener haar complete data-logistiek naar de cloud – zonder verlies van continuïteit. Het resultaat: één schaalbaar platform, met een beter datafundament voor de hele organisatie. Tijdens deze sessie ontdek je de keuzes, obstakels en impact van deze transformatie.
There are very few people like Stephen Brobst, a legendary tech CTO and "certified data geek," Stephen shares his incredible journey, from his early days in computational physics and building real-time trading systems on Wall Street to becoming the CTO for Teradata and now Ab Initio Software. Stephen provides a masterclass on the evolution of data architecture, tracing the macro trends from early decision support systems to "active data warehousing" and the rise of AI/ML (formerly known as data mining). He dives deep into why metadata-driven architecture is critical for the future and how AI, large language models, and real-time sensor technology will fundamentally reshape industries and eliminate the dashboard as we know it. We also chat about something way cooler, as Stephen discusses his three passions: travel, music, and teaching. He reveals his personal rule of never staying in the same city for more than five consecutive days since 1993 and how he manages a life of constant motion. From his early days DJing punk rock and seeing the Sex Pistols' last concert to his minimalist travel philosophy and ever-growing bucket list, Stephen offers a unique perspective on living a life rich with experience over material possessions. Finally, he offers invaluable advice for the next generation on navigating careers in an AI-driven world and living life to the fullest.
Summary In this episode of the Data Engineering Podcast Serge Gershkovich, head of product at SQL DBM, talks about the socio-technical aspects of data modeling. Serge shares his background in data modeling and highlights its importance as a collaborative process between business stakeholders and data teams. He debunks common misconceptions that data modeling is optional or secondary, emphasizing its crucial role in ensuring alignment between business requirements and data structures. The conversation covers challenges in complex environments, the impact of technical decisions on data strategy, and the evolving role of AI in data management. Serge stresses the need for business stakeholders' involvement in data initiatives and a systematic approach to data modeling, warning against relying solely on technical expertise without considering business alignment.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Enterprises today face an enormous challenge: they’re investing billions into Snowflake and Databricks, but without strong foundations, those investments risk becoming fragmented, expensive, and hard to govern. And that’s especially evident in large, complex enterprise data environments. That’s why companies like DirecTV and Pfizer rely on SqlDBM. Data modeling may be one of the most traditional practices in IT, but it remains the backbone of enterprise data strategy. In today’s cloud era, that backbone needs a modern approach built natively for the cloud, with direct connections to the very platforms driving your business forward. Without strong modeling, data management becomes chaotic, analytics lose trust, and AI initiatives fail to scale. SqlDBM ensures enterprises don’t just move to the cloud—they maximize their ROI by creating governed, scalable, and business-aligned data environments. If global enterprises are using SqlDBM to tackle the biggest challenges in data management, analytics, and AI, isn’t it worth exploring what it can do for yours? Visit dataengineeringpodcast.com/sqldbm to learn more.Your host is Tobias Macey and today I'm interviewing Serge Gershkovich about how and why data modeling is a sociotechnical endeavorInterview IntroductionHow did you get involved in the area of data management?Can you start by describing the activities that you think of when someone says the term "data modeling"?What are the main groupings of incomplete or inaccurate definitions that you typically encounter in conversation on the topic?How do those conceptions of the problem lead to challenges and bottlenecks in execution?Data modeling is often associated with data warehouse design, but it also extends to source systems and unstructured/semi-structured assets. How does the inclusion of other data localities help in the overall success of a data/domain modeling effort?Another aspect of data modeling that often consumes a substantial amount of debate is which pattern to adhere to (star/snowflake, data vault, one big table, anchor modeling, etc.). What are some of the ways that you have found effective to remove that as a stumbling block when first developing an organizational domain representation?While the overall purpose of data modeling is to provide a digital representation of the business processes, there are inevitable technical decisions to be made. What are the most significant ways that the underlying technical systems can help or hinder the goals of building a digital twin of the business?What impact (positive and negative) are you seeing from the introduction of LLMs into the workflow of data modeling?How does tool use (e.g. MCP connection to warehouse/lakehouse) help when developing the transformation logic for achieving a given domain representation? What are the most interesting, innovative, or unexpected ways that you have seen organizations address the data modeling lifecycle?What are the most interesting, unexpected, or challenging lessons that you have learned while working with organizations implementing a data modeling effort?What are the overall trends in the ecosystem that you are monitoring related to data modeling practices?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links sqlDBMSAPJoe ReisERD == Entity Relation DiagramMaster Data ManagementdbtData ContractsData Modeling With Snowflake book by Serge (affiliate link)Type 2 DimensionData VaultStar SchemaAnchor ModelingRalph KimballBill InmonSixth Normal FormMCP == Model Context ProtocolThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

This book is your guide to the modern market of data analytics platforms and the benefits of using Snowflake, the data warehouse built for the cloud. As organizations increasingly rely on modern cloud data platforms, the core of any analytics framework—the data warehouse—is more important than ever. This updated 2nd edition ensures you are ready to make the most of the industry’s leading data warehouse. This book will onboard you to Snowflake and present best practices for deploying and using the Snowflake data warehouse. The book also covers modern analytics architecture, integration with leading analytics software such as Matillion ETL, Tableau, and Databricks, and migration scenarios for on-premises legacy data warehouses. This new edition includes expanded coverage of SnowPark for developing complex data applications, an introduction to managing large datasets with Apache Iceberg tables, and instructions for creating interactive data applications using Streamlit, ensuring readers are equipped with the latest advancements in Snowflake's capabilities. What You Will Learn Master key functionalities of Snowflake Set up security and access with cluster Bulk load data into Snowflake using the COPY command Migrate from a legacy data warehouse to Snowflake Integrate the Snowflake data platform with modern business intelligence (BI) and data integration tools Manage large datasets with Apache Iceberg Tables Implement continuous data loading with Snowpipe and Dynamic Tables Who This Book Is For Data professionals, business analysts, IT administrators, and existing or potential Snowflake users

As organizations increasingly leverage Microsoft Fabric to unify their data engineering, analytics, and governance strategies, the role of the Fabric Analytics Engineer has become more crucial than ever. This book equips readers with the knowledge and hands-on skills required to excel in this domain and pass the DP-600 certification exam confidently. This book covers the entire certification syllabus with clarity and depth, beginning with an overview of Microsoft Fabric. You will gain an understanding of the platform’s architecture and how it integrates with data and AI workloads to provide a unified analytics solution. You will then delve into implementing a data warehouse in Microsoft Fabric, exploring techniques to ingest, transform, and store data efficiently. Next, you will learn how to work with semantic models in Microsoft Fabric, enabling them to create intuitive, meaningful data representations for visualization and reporting. Then, you will focus on administration and governance in Microsoft Fabric, emphasizing best practices for security, compliance, and efficient management of analytics solutions. Lastly, you will find detailed practice tests and exam strategies along with supplementary materials to reinforce key concepts. After reading the book, you will have the background and capability to learn the skills and concepts necessary both to pass the DP-600 exam and become a confident Fabric Analytics Engineer. What You Will Learn A complete understanding of all DP-600 certification exam objectives and requirements Key concepts and terminology related to Microsoft Fabric Analytics Step-by-step preparation for successfully passing the DP-600 certification exam Insights into exam structure, question patterns, and strategies for tackling challenging sections Confidence in demonstrating skills validated by the Microsoft Certified: Fabric Analytics Engineer Associate credential Who This Book Is For Data engineers, analysts, and professionals with some experience in data engineering or analytics, seeking to expand their knowledge of Microsoft Fabric
SOLID will showcase how they’ve built just-in-time semantic models using the metadata and usage patterns already available in DWH and BI layers. They’ll walk us through how they connected Cortex to their automatic documentation layer, unlocking business context from technical systems—just when it’s needed.
Since 2022, Gold Coast Health have been on a digital transformation journey. Their objective, to “liberate” clinicians and health staff from burdensome digital and administrative processes by combining data analytics, automation and workflow solutions. Hear about their journey from an on premise enterprise data warehouse to their Advanced Data Platform and their recent success using this platform to automate communications between tertiary and primary care.
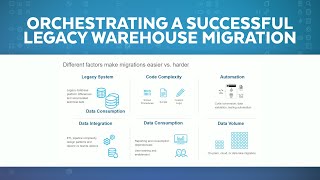
Migrating a legacy data warehouse to Snowflake should be a predictable task. However, after participating in numerous projects, common failure patterns have emerged. In this session, we’ll explore typical pitfalls when moving to the Snowflake AI Data Cloud and offer recommendations for avoiding them. We’ll cover mistakes at every stage of the process, from technical details to end-user involvement and everything in between — code conversion (using SnowConvert!), data migration, deployment, optimization, testing and project management.
Learn how to accelerate and automate your data warehouse migration to Snowflake with enhancements to SnowConvert, Snowflake's native code conversion and data migration solution. Join us for new product and feature overviews, best practices and live demos.

At DXC, we helped our customer FastWeb with their "Welcome Lakehouse" project - a data warehouse transformation from on-premises to Databricks on AWS. But the implementation became something more. Thanks to features such as Lakehouse Federation and Delta Sharing, from the first day of the Fastweb+Vodafone merger, we have been able to connect two different platforms with ease and make the business focus on the value of data and not on the IT integration. This session will feature our customer Alessandro Gattolin of Fastweb to talk about the experience.

The Apache Iceberg™ community is introducing native geospatial type support, addressing key challenges in managing geospatial data at scale, including fragmented formats and inefficiencies in storing large spatial datasets. This talk will delve into the origins of the Iceberg geo type, its specification design and future goals. We will examine the impact on both the geospatial and Iceberg communities, in introducing a standard data warehouse storage layer to the geospatial community, and enabling optimized geospatial analytics for Iceberg users. We will also present a live demonstration of the Iceberg geo data type with Apache Sedona™ and Apache Spark™, showcasing how it simplifies and accelerates geospatial analytics workflows and queries. Finally, we will also provide an in-depth look at its current capabilities and outline the roadmap for future developments, and offer a perspective on its role in advancing geospatial data management in the industry.

Data warehousing in enterprise and mission-critical environments needs special consideration for price/performance. This session will explain how Databricks SQL addresses the most challenging requirements for high-concurrency, low-latency performance at scale. We will also cover the latest advancements in resource-based scheduling, autoscaling and caching enhancements that allow for seamless performance and workload management.

Navy Federal Credit Union has 200+ enterprise data sources in the enterprise data lake. These data assets are used for training 100+ machine learning models and hydrating a semantic layer for serving, at an average 4,000 business users daily across the credit union. The only option for extracting data from analytic semantic layer was to allow consuming application to access it via an already-overloaded cloud data warehouse. Visualizing data lineage for 1,000 + data pipelines and associated metadata is impossible and understanding the granular cost for running data pipelines is a challenge. Implementing Unity Catalog opened alternate path for accessing analytic semantic data from lake. It also opened the doors to remove duplicate data assets stored across multiple lakes which will save hundred thousands of dollars in data engineering efforts, compute and storage costs.

Migrating your Snowflake data warehouse to the Databricks Data Intelligence Platform can accelerate your data modernization journey. Though a cloud platform-to-cloud platform migration should be relatively easy, the breadth of the Databricks Platform provides flexibility and hence requires careful planning and execution. In this session, we present the migration methodology, technical approaches, automation tools, product/feature mapping, a technical demo and best practices using real-world case studies for migrating data, ELT pipelines and warehouses from Snowflake to Databricks.