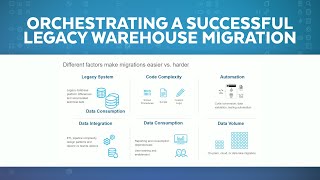
Are you spending too much time on data warehouse management tasks like hardware provisioning, software patching, and performance tuning and not enough time building your applications and innovating with data? Tens of thousands of customers rely on AWS Analytics every day to run and scale analytics in seconds on all their data without managing data warehouse infrastructure. In this session, you’ll learn best practices and proven strategies for modernizing your data warehouse, helping your build powerful analytics and machine learning applications that operate at scale while keeping costs low.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.