This session begins with data warehouse trivia and lessons learned from production implementations of multicloud data architecture. You will learn to design future-proof low latency data systems that focus on openness and interoperability. You will also gain a gentle introduction to Cloud FinOps principles that can help your organization reduce compute spend and increase efficiency.
Most enterprises today are multicloud. While an assortment of low-code connectors boasts the ability to make data available for analytics in real time, they post long-lasting challenges:
- Inefficient EDW targets
- Inability to evolve schema
- Forbiddingly expensive data exports due to cloud and vendor lock-in
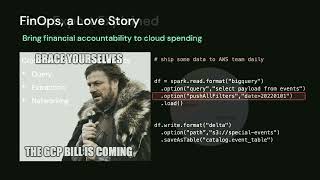
The alternative is an open data lake that unifies batch and streaming workloads. Bronze landing zones in open format eliminate the data extraction costs required by proprietary EDW. Apache Spark™ Structured Streaming provides a unified ingestion interface. Streaming triggers allow us to switch back and forth between batch and stream with one-line code changes. Streaming aggregation enables us to incrementally compute on data that arrives near each other.
Specific examples are given on how to use Autoloader to discover newly arrived data and ensure exactly once, incremental processing. How DLT can be configured effectively to further simplify streaming jobs and accelerate the development cycle. How to apply SWE best practices to Workflows and integrate with popular Git providers, either using the Databricks Project or Databricks Terraform provider.
Talk by: Christina Taylor
Here’s more to explore: Big Book of Data Engineering: 2nd Edition: https://dbricks.co/3XpPgNV The Data Team's Guide to the Databricks Lakehouse Platform: https://dbricks.co/46nuDpI
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc