Rivers have long been storytellers of human history. From the Nile to the Yangtze, they have shaped trade, migration, settlement, and the rise of civilizations. They reveal the traces of human ambition... and the costs of it. Today, from the Charles to the Golden Gate, US rivers continue to tell stories, especially through data.
Over the past decades, extensive water quality monitoring efforts have generated vast public datasets: millions of measurements of pH, dissolved oxygen, temperature, and conductivity collected across the country. These records are more than environmental snapshots; they are archives of political priorities, regulatory choices, and ecological disruptions. Ultimately, they are evidence of how societies interact with their environments, often unevenly.
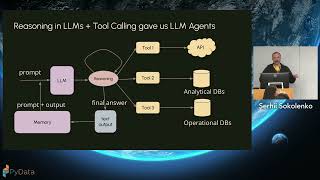
In this talk, I’ll explore how Python and modern data workflows can help us "listen" to these stories at scale. Using the United States Geological Survey (USGS) Water Data APIs and Remote SSH in Positron, I’ll process terabytes of sensor data spanning several years and regions. I’ll demonstrate that, while Parquet and DuckDB enable scalable exploration of historical records, using Remote SSH is paramount in order to enable large-scale data analysis. By doing so, I hope to answer some analytical questions that can surface patterns linked to industrial growth, regulatory shifts, and climate change.
By treating rivers as both ecological systems and social mirrors, we can begin to see how environmental data encodes histories of inequality, resilience, and transformation.
Whether your interest lies in data engineering, environmental analytics, or the human dimensions of climate and infrastructure, this talk will explore topics at the intersection of environmental science, will offer both technical methods and sociological lenses to understand the stories rivers continue to tell.