Do you need to move your code from notebooks into production? Or do you want to level up your software engineering skills? In this tutorial, we will show you how to turn a Jupyter notebook into a robust, reproducible Python script. You will learn how to use tools for converting notebooks into scripts, how to make your code modular, and how to write unit tests.
 talk-data.com
talk-data.com
Topic
Python
programming_language
data_science
web_development
1446
tagged
Activity Trend
185
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Science Books
220
Data Engineering Podcast
183
O'Reilly Data Engineering Books
151
SciPy 2025
67
PyConDE & PyData Berlin 2023
49
Data + AI Summit 2025
30
Databricks DATA + AI Summit 2023
29
O'Reilly AI & ML Books
27
PyData Seattle 2025
23
PyData Paris 2025
20
O'Reilly Data Visualization Books
20
PyData London 2025
20
Datamaps are ML-powered visualizations of high-dimensional data, and in this talk the data is collections of embedding vectors. Interactive datamaps run in-browser as web-apps, potentially without any code running on the web server. Datamap tech can be used to visualize, say, the entire collection of chunks in a RAG vector database.
The best-of-breed tools of this new datamap technique are liberally licensed open source. This presentation is an introduction to building with those repos. The maths will be mentioned only in passing; the topic here is simply how-to with specific tools. Talk attendees will be learning about Python tools, which produce high-quality web UIs.
DataMapPlot is the premiere tool for rendering a datamap as a web-app. Here is a live demo thereof: https://connoiter.com/datamap/cff30bc1-0576-44f0-a07c-60456e131b7b
00-25: Intro to datamaps 25-45: Pipeline architecture 45-55: demos touring such tools as UMAP, HDBSCAN, DataMapPlot, Toponomy, etc. 55-90: Group coding
A Google account is required to log in to Google Colab, where participants can run the workshop notebooks. A Hugging Face API key (token) is needed to download Gemma models.
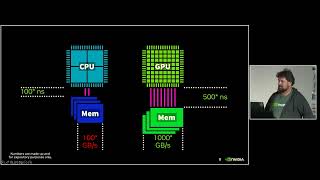
As datasets continue to grow in both size and complexity, CPU-based visualization pipelines often become bottlenecks, slowing down exploratory data analysis and interactive dashboards. In this session, we’ll demonstrate how GPU acceleration can transform Python-based interactive visualization workflows, delivering speedups of up to 50x with minimal code changes. Using libraries such as hvPlot, Datashader, cuxfilter, and Plotly Dash, we’ll walk through real-world examples of visualizing both tabular and unstructured data and demonstrate how RAPIDS, a suite of open-source GPU-accelerated data science libraries from NVIDIA, accelerates these workflows. Attendees will learn best practices for accelerating preprocessing, building scalable dashboards, and profiling pipelines to identify and resolve bottlenecks. Whether you are an experienced data scientist or developer, you’ll leave with practical techniques to instantly scale your interactive visualization workflows on GPUs.

From the speaker who got kicked off the stage after 54 minutes of his 45-minute PyParallel talk at PyData NYC 2013, comes a new talk foaming about the virtues of Python's new free-threaded support!
by
Andy Terrel
The world of generative AI is expanding. New models are hitting the market daily. The field has bifurcated between model training and model inference. The need for fast inference has led to numerous Tile languages to be developed. These languages use concepts from linear algebra and borrow common numpy apis. In this talk we will show how tiling works and how to build inference models from scratch in pure Python with embedded tile languages. The goal is to provide attendees with a good overview that can be integrated in common data pipelines.
Women make up only 22% of data and AI roles and contribute just 3% of Python commits, leaving a “missing 78%” of untapped talent and perspective. This talk shares what happened when our community doubled overnight, revealing hidden demand for inclusive spaces in scientific Python.
We’ll present the data behind this growth, examine systemic barriers, and introduce the VIM framework (Visibility–Invitation–Mechanism) — a research-backed model for building resilient, inclusive communities. Attendees will leave with practical, reproducible strategies to grow engagement, improve retention, and ensure that the future of AI and Python is shaped by all voices, not just the few.

Advancements in deep learning for biomedical image processing have led to the development of promising algorithms across multiple clinical domains, including radiology, digital pathology, ophthalmology, cardiology, and dermatology, among others. With robust AI models demonstrating commendable results, it is crucial to understand that their limited interpretability can impede the clinical translation of deep learning algorithms. The inference mechanism of these black-box models is not entirely understood by clinicians, patients, regulatory authorities, and even algorithm developers, thereby exacerbating safety concerns. In this interactive talk, we will explore some novel explainability techniques designed to interpret the decision-making process of robust deep learning algorithms for biomedical image processing. We will also discuss the impact and limitations of these techniques and analyze their potential to provide medically meaningful algorithmic explanations. Open-source resources for implementing these interpretability techniques using Python will be covered to provide a holistic understanding of explaining deep learning models for biomedical image processing.
This talk is distilled from a course that Ojas Ramwala designed, which received the best seminar award for the highest graduate student enrollment at the Department of Biomedical Informatics and Medical Education at the University of Washington, Seattle.
Most AI pipelines still treat models like Python UDFs, just another function bolted onto Spark, Pandas, or Ray. But models aren’t functions: they’re expensive, stateful, and difficult to configure. In this talk, we’ll explore why this mental model breaks at scale and share practical patterns for treating models as first-class citizens in your pipelines.
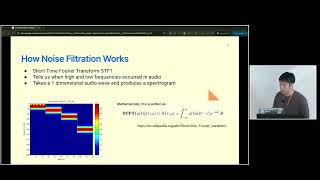
In the world of AI voice agents, especially in sensitive contexts like healthcare, audio clarity is everything. Background noise—a barking dog, a TV, street sounds—degrades transcription accuracy, leading to slower, clunkier, and less reliable AI responses. But how do you solve this in real-time without breaking the bank?
This talk chronicles our journey at a health-tech startup to ship background noise filtration at scale. We'll start with the core principles of noise reduction and our initial experiments with open-source models, then dive deep into the engineering architecture required to scale a compute-hungry ML service using Python and Kubernetes. You'll learn about the practical, operational considerations of deploying third-party models and, most importantly, how to measure their true impact on the product.

Many talks show how to make Python code faster. This one flips the script: what if we try to make our Python as slow as possible? By exploring deliberately inefficient programs — from infinite loops to Turing machines that halt only after an astronomically long time — we’ll discover surprising lessons about computation, large numbers, and the limits of programming languages. Inspired by new Turing machine results, this talk will connect Python experiments with deep questions in theoretical computer science.
Hands-on Python introduction for ages 12-18 featuring the Emoji Master Challenge. The session starts with a Python basics intro and ends with a reveal of the superheroes created by the students. Levels include Level 3: display a rose emoji 10 times; Level 5: conceal a superhero using emojis. Learn practical Python skills and time-saving shortcuts (Ctrl+C/Ctrl+V) through interactive projects using PyGame, Turtle, and PyQt.
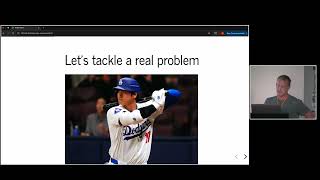
This talk will be about the Gaussian process (GP) functionality in the open source Python package PyMC, and how to use GPs effectively for models in the real world. The goal will be to bridge the (wide!) gap between theory and practice, using an example from baseball. By the end of the talk you'll know what's possible in PyMC and how to avoid common pitfalls.

Generalized Additive Models (GAMs)
Generalized Additive Models (GAMs) strike a rare balance: they combine the flexibility of complex models with the clarity of simple ones.
They often achieve performance comparable to black-box models, yet remain: - Easy to interpret - Computationally efficient - Aligned with the growing demand for transparency in AI
With recent U.S. AI regulations (White House, 2022) and increasing pressure from decision-makers for explainable models, GAMs are emerging as a natural choice across industries.
Audience
This guide is for readers with some background in Python and statistics, including:
- Data scientists
- Machine learning engineers
- Researchers
Takeaway
By the end, you’ll understand:
- The intuition behind GAMs
- How to build and apply them in practice
- How to interpret and explain GAM predictions and results in Python
Prerequisites
You should be comfortable with:
- Basic regression concepts
- Model regularization
- The bias–variance trade-off
- Python programming

Learn how to build fast and reliable retail demand forecasts using StatsForecast, an open-source Python library for scalable statistical forecasting. This session will cover techniques including rolling-origin cross-validation and conformal prediction, with practical retail demand examples.

Creating successful data products requires more than just powerful algorithms it demands a deep understanding of user needs. In this panel, founders and leaders from innovative data-driven startups share their strategies for designing user-centric data products including Python-based tools.
PySpark’s Arrow-based Python UDFs open the door to dramatically faster data processing by avoiding expensive serialization overhead. At the same time, Polars, a high-performance DataFrame library built on Rust, offers zero-copy interoperability with Apache Arrow. This talk shows how combining these two technologies unlocks new performance gains: writing Arrow UDFs with Polars in PySpark can deliver performance speedups compared to Python UDFs. Attendees will learn how Arrow UDFs work in PySpark, how it can be used with other data processing libraries, and how to apply this approach to real-world Spark pipelines for faster, more efficient workloads.
The proliferation of AI/ML workloads across commercial enterprises, necessitates robust mechanisms to track, inspect and analyze their use of on-prem/cloud infrastructure. To that end, effective insights are crucial for optimizing cloud resource allocation with increasing workload demand, while mitigating cloud infrastructure costs and promoting operational stability.
This talk will outline an approach to systematically monitor, inspect and analyze AI/ML workloads’ properties like runtime, resource demand/utilization and cost attribution tags . By implementing granular inspection across multi-player teams and projects, organizations can gain actionable insights into resource bottlenecks, identify opportunities for cost savings, and enable AI/ML platform engineers to directly attribute infrastructure costs to specific workloads.
Cost attribution of infrastructure usage by AI/ML workloads focuses on key metrics such as compute node group information, cpu usage seconds, data transfer, gpu allocation , memory and ephemeral storage utilization. It enables platform administrators to identify competing workloads which lead to diminishing ROI. Answering questions from data scientists like "Why did my workload run for 6 hours today, when it took only 2 hours yesterday" or "Why did my workload start 3 hours behind schedule?" also becomes easier.
Through our work on Metaflow, we will showcase how we built a comprehensive framework for transparent usage reporting, cost attribution, performance optimization, and strategic planning for future AI/ML initiatives. Metaflow is a human centric python library that enables seamless scaling and management of AI/ML projects.
Ultimately, a well-defined usage tracking system empowers organizations to maximize the return on investment from their AI/ML endeavors while maintaining budgetary control and operational efficiency. Platform engineers and administrators will be able to gain insights into the following operational aspects of supporting a battle hardened ML Platform:
1.Optimize resource allocation: Understand consumption patterns to right-size clusters and allocate resources more efficiently, reducing idle time and preventing bottlenecks.
-
Proactively manage capacity: Forecast future resource needs based on historical usage trends, ensuring the infrastructure can scale effectively with increasing workload demand.
-
Facilitate strategic planning: Make informed decisions regarding future infrastructure investments and scaling strategies.
4.Diagnose workload execution delays: Identify resource contention, queuing issues, or insufficient capacity leading to delayed workload starts.
Data Scientists on the other hand will gain clarity on factors that influence workload performance. Tuning them can lead to efficiencies in runtime and associated cost profiles.

As generative AI systems become more powerful and widely deployed, ensuring safety and security is critical. This talk introduces AI red teaming—systematically probing AI systems to uncover potential risks—and demonstrates how to get started using PyRIT (Python Risk Identification Toolkit), an open-source framework for automated and semi-automated red teaming of generative AI systems. Attendees will leave with a practical understanding of how to identify and mitigate risks in AI applications, and how PyRIT can help along the way.

Why can we solve some equations with neat formulas, while others stubbornly resist every trick we know? Equations with squares bow to the quadratic formula. Those with cubes and fourth powers also have solutions. But then the magic stops. And when we, as data scientists, add exponentials, logarithms, or trigonometric terms into models, the resulting equations often cross into territory where no closed-form solutions exist.
This talk is both fun and useful. With Python and SymPy, we’ll “cheat” our way through centuries of mathematics, testing families of equations to see when closed forms appear and when numerical methods are our only option. Attendees will enjoy surprising examples, a bit of mathematical history, and practical insight into when exact solutions exist — and when to stop searching and switch to numerical methods.

by
Jim Dowling
Agents need timely and relevant context data to work effectively in an interactive environment. If an agent takes more than a few seconds to react to an action in a client applicatoin, users will not perceive it as intelligent - just laggy.
Real-time context engineering involves building real-time data pipelines to pre-process application data and serve relevant and timely context to agents. This talk will focus on how you can leverage application identifiers (user ID, session ID, article ID, order ID, etc) to identify which real-time context data to provide to agents. We will contrast this approach with the more traditional RAG approach of using vector indexes to retrieve chunks of relevent text using the user query. Our approach will necessitate the introduction of the Agent-to-Agent protocol, an emerging standard for defining APIs for agents.
We will also demonstrate how we provide real-time context data from applications inside Python agents using the Hopsworks feature store. We will walk through an example of an interactive application (TikTok clone).