The proliferation of AI/ML workloads across commercial enterprises, necessitates robust mechanisms to track, inspect and analyze their use of on-prem/cloud infrastructure. To that end, effective insights are crucial for optimizing cloud resource allocation with increasing workload demand, while mitigating cloud infrastructure costs and promoting operational stability.
This talk will outline an approach to systematically monitor, inspect and analyze AI/ML workloads’ properties like runtime, resource demand/utilization and cost attribution tags . By implementing granular inspection across multi-player teams and projects, organizations can gain actionable insights into resource bottlenecks, identify opportunities for cost savings, and enable AI/ML platform engineers to directly attribute infrastructure costs to specific workloads.
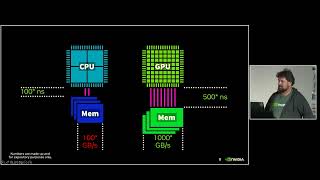
Cost attribution of infrastructure usage by AI/ML workloads focuses on key metrics such as compute node group information, cpu usage seconds, data transfer, gpu allocation , memory and ephemeral storage utilization. It enables platform administrators to identify competing workloads which lead to diminishing ROI. Answering questions from data scientists like "Why did my workload run for 6 hours today, when it took only 2 hours yesterday" or "Why did my workload start 3 hours behind schedule?" also becomes easier.
Through our work on Metaflow, we will showcase how we built a comprehensive framework for transparent usage reporting, cost attribution, performance optimization, and strategic planning for future AI/ML initiatives. Metaflow is a human centric python library that enables seamless scaling and management of AI/ML projects.
Ultimately, a well-defined usage tracking system empowers organizations to maximize the return on investment from their AI/ML endeavors while maintaining budgetary control and operational efficiency. Platform engineers and administrators will be able to gain insights into the following operational aspects of supporting a battle hardened ML Platform:
1.Optimize resource allocation: Understand consumption patterns to right-size clusters and allocate resources more efficiently, reducing idle time and preventing bottlenecks.
-
Proactively manage capacity: Forecast future resource needs based on historical usage trends, ensuring the infrastructure can scale effectively with increasing workload demand.
-
Facilitate strategic planning: Make informed decisions regarding future infrastructure investments and scaling strategies.
4.Diagnose workload execution delays: Identify resource contention, queuing issues, or insufficient capacity leading to delayed workload starts.
Data Scientists on the other hand will gain clarity on factors that influence workload performance. Tuning them can lead to efficiencies in runtime and associated cost profiles.