Building a Lakehouse on AWS for Less with AWS Graviton and Photon
2022-07-19
Watch
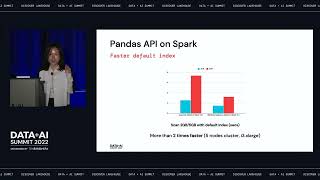
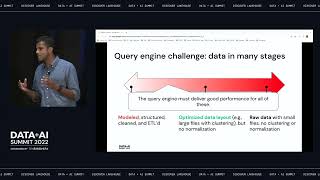
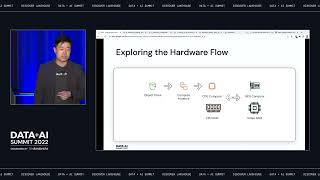
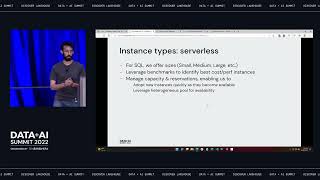
AWS Graviton processors are custom-designed by AWS to enable the best price performance for workloads in Amazon EC2. In this session we will review benchmarks that demonstrate how AWS Graviton based instances run Databricks workloads at a lower price and better performance than x86-based instances on AWS, and when combined with Photon, the new Databricks engine, the price performance gains are even greater. Learn how you can optimize your Databricks workloads on AWS and save more.
Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/