Road to a Robust Data Lake: Utilizing Delta Lake & Databricks to Map 150 Million Miles of Roads
In the past, stream processing over data lakes required a lot of development efforts from data engineering teams, as Itai has shown in his talk at Spark+AI Summit 2019 (https://tinyurl.com/2s3az5td). Today, with Delta Lake and Databricks Auto Loader, this becomes a few minutes' work! Not only that, it unlocks a new set of ways to efficiently leverage your data.
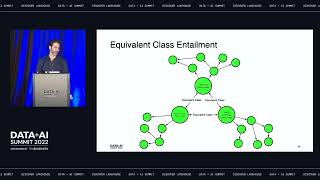
Nexar, a leading provider of dynamic mapping solutions, utilizes Delta Lake and advanced features such as Auto Loader to map 150 million miles of roads a month and provide meaningful insights to cities, mobility companies, driving apps, and insurers. Nexar’s growing dataset contains trillions of images that are used to build and maintain a digital twin of the world. Nexar uses state-of-the-art technologies to detect road furniture (like road signs and traffic lights), surface markings, and road works.
In this talk, we will describe how you can efficiently ingest, process, and maintain a robust Data Lake, whether you’re a mapping solutions provider, a media measurement company, or a social media network. Topics include: * Incremental & efficient streaming over cloud storage such as S3 * Storage optimizations using Delta Lake * Supporting mutable data use-cases with Delta Lake
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/