Consider key trends and challenges as you design an effective organizational architecture for data governance while generating value with pervasive analytics. Published at: https://www.eckerson.com/articles/organizational-architecture-can-make-or-break-your-data-governance-program
 talk-data.com
talk-data.com
Topic
Analytics
data_analysis
insights
metrics
4552
tagged
Activity Trend
398
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Science Books
528
O'Reilly Data Engineering Books
395
Moody's Talks - Inside Economics
283
Data Engineering Podcast
227
Data Career Podcast: Helping You Land a Data Analyst Job FAST
187
Data + AI Summit 2025
178
Databricks DATA + AI Summit 2023
170
The Analytics Power Hour
130
DataFramed
103
DATA MINER Big Data Europe Conference 2020
98
Secrets of Data Analytics Leaders
89
Dbt Coalesce 2024
87
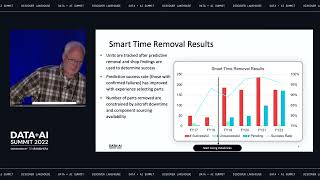
We will show how using Azure Databricks Lakehouse is modernizing our data & analytics environment which has given us new capability to create custom predictive models for hundreds of families of aircraft components without sensor data. We currently have over 95% success rate with over $1.3 million in avoided operational impact costs in FY21.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

The Department of Veterans Affairs (VA) is home to over 420,000 employees, provides health care for 9.16 million enrollees and manages the benefits of 5.75 million recipients. The VA also hosts an array of financial management, professional, and administrative services at their Financial Service Center (FSC), located in Austin, Texas. The FSC is divided into various service groups organized around revenue centers and product lines, including the Data Analytics Service (DAS). To support the VA mission, in 2021 FSC DAS continued to press forward with their cloud modernization efforts, successfully achieving four key accomplishments:
Office of Community Care (OCC) Financial Time Series Forecast - Financial forecasting enhancements to predict claims CFO Dashboard - Productivity and capability enhancements for financial and audit analytics Datasets Migrated to the Cloud - Migration of on-prem datasets to the cloud for down-stream analytics (includes a supply chain proof-of-concept) Data Science Hackathon - A hackathon to predict bad claims codes and demonstrate DAS abilities to accelerate a ML use case using Databricks AutoML
This talk discusses FSC DAS’ cloud and data science modernization accomplishments in 2021, lessons learned, and what’s ahead.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
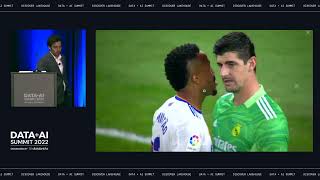
How LaLiga uses and combines eventing and tracking data to implement novel analytics and metrics, thus helping analysts to better understand the technical and tactical aspects of their clubs.
This presentation will explain the treatment of these data and its subsequent use to create metrics and analytical models.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Can we take Data Engineering on Spark 10x beyond where it is today?
Yes, we can enable 10x more users on Spark, and make them 10x more productive from day 1. Data engineering can run at scale, and it can still be 10x simpler and faster to develop, deploy, and manage pipelines.
Low code is the key. A modern data engineering platform built on low code will enable all data users, from new graduates to experts, to visually develop high-quality pipelines. With Visual = Code, the visual elements will be stored as PySpark code on Git and deployed using the best software practices taken from DevOps. Search and lineage help data engineers and their customers in analytics understand how each column value was produced, when it was updated, and the associated quality metric.
See how a complete, low-code data engineering platform can reduce complexity and effort, enabling you to rapidly deploy, scale, and use Spark, making data and analytics a strategic asset in your company.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Learn how semantic layers are becoming a critical component of a modern analytics stack.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Most organizations run complex cloud data architectures that silo applications, users, and data. As a result, most analysis is performed with stale data and there isn’t a single source of truth of data for analytics.
Join this interactive follow-along deep dive demo to learn how Databricks SQL allows you to operate a multicloud lakehouse architecture that delivers data warehouse performance at data lake economics — with up to 12x better price/performance than traditional cloud data warehouses. Now data analysts and scientists can work with the freshest and most complete data and quickly derive new insights for accurate decision-making.
Here’s what we’ll cover: • Managing data access and permissions and monitoring how the data is being used and accessed in real time across your entire lakehouse infrastructure • Configuring and managing compute resources for fast performance, low latency, and high user concurrency to your data lake • Creating and working with queries, dashboards, query refresh, troubleshooting features and alerts • Creating connections to third-party BI and database tools (Power BI, Tableau, DbVisualizer, etc.) so that you can query your lakehouse without making changes to your analytical and dashboarding workflows
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Moving and building in the cloud to accelerate analytics development requires enterprises to rethink their data infrastructure. Whether you are moving from an on-prem legacy system or you were born in the cloud, businesses are turning to Confluent and Databricks to help them unlock new real-time customer experiences and intelligence for their backend operations.
Join us to see how Confluent and Databricks enable companies to set data in motion across any system, at any scale, in near real-time. Connecting Confluent with Databricks allows companies to migrate and connect data from on-prem databases and data warehouses like Netezza, Oracle, and Cloudera to Databricks in the cloud to power real-time analytics.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Organizations want data lakes to be the source of truth for analytics. But operational teams rarely recognize the power the data lake, shortening the reach of all the valuable data within it. Instead, these business users often treat operational tools like Salesforce, Marketo, and NetSuite as their source of truth.
The reality is lakehouses and operational tools alike have missed critical pieces of data and don’t provide the full customer picture. Operational Analytics solves this last mile problem by making it possible to sync transformed data directly from your data lake back into these systems to expand the reach of your data.
In this talk you’ll learn: - What Operational Analytics & Reverse ETL are and why they're taking off - How Operational Analytics helps companies today activate and expand the reach of their data - Real-life use cases from companies using Operational Analytics to empower their data teams & give them the seat at the table they deserve
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
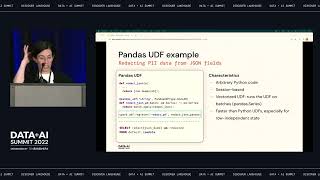
Databricks SQL (DB SQL) allows customers to leverage the simple and powerful Lakehouse architecture with up to 12x better price/performance compared to traditional cloud data warehouses. Analysts can use standard SQL to easily query data and share insights using a query editor, dashboards or a BI tool of their choice, and analytics engineers can build and maintain efficient data pipelines, including with tools like dbt.
While SQL is great at querying and transforming data, sometimes you need to extend its capabilities with the power of Python, a full programming language. Users of Databricks notebooks already enjoy seamlessly mixing SQL, Python and several other programming languages. Use cases include masking or encrypting and decrypting sensitive data, complex transformation logic, using popular open source libraries or simply reusing code that has already been written elsewhere in Databricks. In many cases, it is simply prohibitive or even impossible to rewrite the logic in SQL.
Up to now, there was no way to use Python from within DBSQL. We are removing this restriction with the introduction of Python User Defined Functions (UDFs). DBSQL users can now create, manage and use Python UDFs using standard SQL. UDFs are registered in Unity Catalog, which means they can be governed and used throughout Databricks, including in notebooks.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Serving patients in over 100 countries, Amgen is a leading global biotech company focused on developing therapies that have the power to save lives. Delivering on this mission requires our commercial teams to regularly meet with healthcare providers to discuss new treatments that can help patients in need. With the onset of the pandemic, where face-to-face interactions with doctors and other Healthcare Providers (HCPs) were severely impacted, Amgen had to rethink these interactions. With that in mind, the Amgen Commercial Data and Analytics team leveraged a modern data and AI architecture built on the Databricks Lakehouse to help accelerate its digital and data insights capabilities. This foundation enabled Amgen’s teams to develop a comprehensive, customer-centric view to support flexible go-to-market models and provide personalized experiences to our customers. In this presentation, we will share our recent journey of how we took an agile approach to bringing together over 2.2 petabytes of internally generated and externally sourced vendor data , and onboard into our AWS Cloud and Databricks environments to enable a standardized, scalable and robust capabilities to meet the business requirements in our fast-changing life sciences environment. We will share use cases of how we harmonized and managed our diverse sets of data to deliver efficiency, simplification, and performance outcomes for the business. We will cover the following aspects of our journey along with best practices we learned over time: • Our architecture to support Amgen’s Commercial Data & Analytics constant processing around the globe • Engineering best practices for building large scale Data Lakes and Analytics platforms such as Team organization, Data Ingestion and Data Quality Frameworks, DevOps Toolkit and Maturity Frameworks, and more • Databricks capabilities adopted such as Delta Lake, Workspace policies, SQL workspace endpoints, and MLflow for model registry and deployment. Also, various tools were built for Databricks workspace administration • Databricks capabilities being explored for future, such as Multi-task Orchestration, Container-based Apache Spark Processing, Feature Store, Repos for Git integration, etc. • The types of commercial analytics use cases we are building on the Databricks Lakehouse platform Attendees building global and Enterprise scale data engineering solutions to meet diverse sets of business requirements will benefit from learning about our journey. Technologists will learn how we addressed specific Business problems via reusable capabilities built to maximize value.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

In this breakout session we’ll learn about Flux, the data scripting and query language for InfluxDB. InfluxDB is the leading time series database platform. With Flux you can perform time series lifecycle management tasks, data preparation and analytics, alert tasks, and more. InfluxDB has two offerings: InfluxDB Cloud and InfluxDB OSS. Finally, we’ll learn about how you can use Flux and the replication tool to consolidate data from your OSS instances running at the edge to InfluxDB Cloud.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

The modern data stack makes it possible to query high-volume data with extremely high granularity, dimensionality, and cardinality. Operationalized machine learning is a great way to address this complex data, focusing the scope of analyst inquiry and quickly exposing dimensions, groups, and sub-groups of data with the greatest impact on key metrics.
This session will discuss how to leverage operationalized AI/ML to automatically define millions of features and perform billions of simultaneous hypothesis tests across a wide dataset to identify key drivers of metric change. A technical demonstration will include an overview of leveraging the Databricks Lakehouse using Sisu’s AI/ML-powered decision intelligence platform: connecting to Databricks, defining metrics, automated AI/ML-powered analysis, and exposing actionable business insights.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
The last couple years have put a new lens on how organizations approach analytics - day-old data became useless, and only in-the-moment-insights became relevant, pushing data and analytics teams to their breaking point. The results: everyone has fast forwarded in their transformation and modernization plans, and it's also made us look differently at who engages with data and how.
At ThoughtSpot, we believe analytics is not just for data people. It’s for everyone - everywhere. Join us in this session to: Learn how to transform the user experience with self-service, interactive analytics Get real-life tips on implementing a modern analytics strategy See a demo of Live Analytics in ThoughtSpot Hear how Norwegian airline Flyr is resetting analytics in their industry by putting data first
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
Teams across an organization should be able to use predictive analytics for their business. While there are data scientists and data engineers who can leverage code to build ML models, there are domain experts and analysts who can benefit from low-code tools to build ML solutions.
Join this session to learn how you can leverage Databricks AutoML and other low-code tools to build, train and deploy ML models into production. Additionally, Databricks takes a unique glass-box approach, so you can take the code behind ML model and tweak further to fine-tune performance and integrate into production systems. See these capabilities in action and learn how Databricks empowers users of varying levels of expertise to build ML solutions.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Many federal agencies use SAS software for critical operational data processes. While SAS has historically been a leader in analytics, it has often been used by data analysts for ETL purposes as well. However, modern data science demands on ever-increasing volumes and types of data require a shift to modern, cloud architectures and data management tools and paradigms for ETL/ELT. In this presentation, we will provide a case study at Centers for Medicare and Medicaid Services (CMS) detailing the approach and results of migrating a large, complex legacy SAS process to modern, open-source/open-standard technology - Spark SQL & Databricks – to produce results ~75% faster without reliance on proprietary constructs of the SAS language, with more scalability, and in a manner that can more easily ingest old rules and better govern the inclusion of new rules and data definitions. Significant technical and business benefits derived from this modernization effort are described in this session.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

In today’s modern IT organization whether it is the delivery of a sophisticated analytical model or a product advancement decision or understanding the behavior of a customer, the fact remains that in every instance we rely on data to make good, informed decisions. Given this backdrop, having an architecture which supports the ability to efficiently collect data from a wide range of sources within the company is still an important goal of all data organizations.
In this session we will explain how Bayer has deployed a hybrid data platform which strives to integrate key existing legacy data systems of the past while taking full advantage of what a modern cloud data platform has to offer in terms of scalability and flexibility. It will elaborate the use of its most significant component, Databricks, which serves to provide not only a very sophisticated data pipelining solution but also a complete ecosystem for teams to create data and analytical solutions in a flexible and agile way.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Machine Learning (ML) is increasingly being deployed in complex situations by teams. While much research effort has focused on the training and validation stages, other parts have been neglected by the research community.
In this talk, Daniel Kang will describe two abstractions (model assertions and learned observation assertions) that allow users to input domain knowledge to find errors at deployment time and in labeling pipelines. He will show real-world errors in labels and ML models deployed in autonomous vehicles, visual analytics, and ECG classification that these abstractions can find. I'll further describe how they can be used to improve model quality by up to 2x at a fixed labeling budget. This work is being conducted jointly with researchers from Stanford University and Toyota Research Institute.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/
In this session we’ll present Mosaic, a new Databricks Labs project with a geospatial flavour.
Mosaic provides users of Spark and Databricks with a unified framework for distributing geospatial analytics. Users can choose to employ existing Java-based tools such as JTS or Esri's Geometry API for Java and Mosaic will handle the task of parallelizing these tools' operations: e.g. efficiently reading and writing geospatial data and performing spatial functions on geometries. Mosaic helps users scale these operations by providing spatial indexing capabilities (using, for example, Uber's H3 library) and advanced techniques for optimising common point-in-polygon and polygon-polygon intersection operations.
The development of Mosaic builds upon techniques developed with Ordnance Survey (the central hub for geospatial data across UK Government) and described in this blog post: https://databricks.com/blog/2021/10/11/efficient-point-in-polygon-joins-via-pyspark-and-bng-geospatial-indexing.html
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Microservices is an increasingly popular architecture much loved by application teams, for it allows services to be developed and scaled independently. Data teams, though, often need a centralized repository where all data from different services come together to join and aggregate. The data platform can serve as a single source of company facts, enable near real time analytics, and secure sharing of massive data sets across clouds.
A viable microservices ingestion pattern is Change Data Capture, using AWS Database Migration Services or Debezium. CDC proves to be a scalable solution ideal for stable platforms, but it has several challenges for evolving services: Frequent schema changes, complex, unsupported DDL during migration, and automated deployments are but a few. An event streaming architecture can address these challenges.
Confluent, for example, provides a schema registry service where all services can register their event schemas. Schema registration helps with verifying that the events are being published based on the agreed contracts between data producers and consumers. It also provides a separation between internal service logic and the data consumed downstream. The services write their events to Kafka using the registered schemas with a specific topic based on the type of the event.
Data teams can leverage Spark jobs to ingest Kafka topics into Bronze tables in the Delta Lake. On ingestion, the registered schema from schema registry is used to validate the schema based on the provided version. A merge operation is sometimes called to translate events into final states of the records per business requirements.
Data teams can take advantage of Delta Live Tables on streaming datasets to produce Silver and Gold tables in near real time. Each input data source also has a set of expectations to ensure data quality and business rules. The pipeline allows Engineering and Analytics to collaborate by mixing Python and SQL. The refined data sets are then fed into Auto ML for discovery and baseline modeling.
To expose Gold tables to more consumers, especially non spark users across clouds, data teams can implement Delta Sharing. Recipients can accesses Silver tables from a different cloud and build their own analytics data sets. Analytics teams can also access Gold tables via pandas Delta Sharing client and BI tools.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/