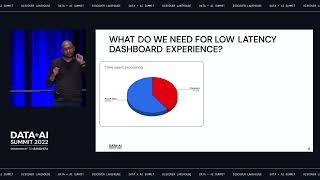
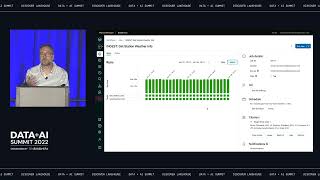
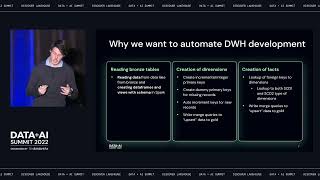
COVID has changed the way that we work and the way that we must do business. Supply Chain disruptions have impacted manufacturers’ ability to manufacture and distribute products. Logistics and the lack of labor have forced us to staff differently. The existential threat is real and we must change the way that we analyze data and solve problems real time in order to stay relevant.
In this session, you’ll learn about our journey, why the Data Lake and digital tech is essential to survival in this new world, some practical examples of how machine learning and data pipelines enable faster decision making, and why businesses cannot survive without these capabilities.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/