Data management practices have changed substantially since the early 1990s and the dawn of data warehousing. Published at: https://www.eckerson.com/articles/the-continuing-evolution-of-data-management
 talk-data.com
talk-data.com
Topic
Data Management
data_governance
data_quality
metadata_management
1097
tagged
Activity Trend
88
peak/qtr
2020-Q1
2026-Q1
Top Events
Data Engineering Podcast
485
O'Reilly Data Engineering Books
158
O'Reilly Data Science Books
53
Hub & Spoken: Data | Analytics | Chief Data Officer | CDO | Data Strategy
42
Secrets of Data Analytics Leaders
32
Data + AI Summit 2025
32
Big Data LDN 2024
28
Databricks DATA + AI Summit 2023
26
Big Data LDN 2025
16
gartner-data-analytics-uk-2025
16
Data Product Management in Action: The Practitioner's Podcast
15
gartner-data-analytics-us-2026
15

Mastering MongoDB 7.0 is your in-depth resource for learning MongoDB 7.0, the powerful NoSQL database designed for developers. Gain expertise in database architecture, data management, and modern features like MongoDB Atlas. By reading this book, you'll acquire the essential skills needed for building efficient, scalable, and secure applications. What this Book will help me do Develop expert-level skills in crafting advanced queries and managing complex data tasks in MongoDB. Learn to design efficient schemas and optimize indexing to maximize database performance. Integrate applications seamlessly with MongoDB Atlas, mastering its monitoring and backup tools. Implement robust security with RBAC, auditing strategies, and comprehensive encryption. Explore the latest MongoDB 7.0 features, including Atlas Vector Search, for modern applications. Author(s) Marko Aleksendrić, Arek Borucki, and co-authors are recognized MongoDB experts with years of hands-on experience. They bring together their expertise to deliver a practical guide filled with real-world insights that help developers advance their MongoDB skills. Their collaborative writing ensures comprehensive coverage of MongoDB 7.0 tools and techniques. Who is it for? This book is written for software developers, database administrators, and engineers who have intermediate knowledge of MongoDB and want to extend their expertise. Whether you are developing scalable applications, managing data systems, or ensuring database security, this book offers advanced guidance for achieving your professional goals with MongoDB.
Summary
Working with financial data requires a high degree of rigor due to the numerous regulations and the risks involved in security breaches. In this episode Andrey Korchack, CTO of fintech startup Monite, discusses the complexities of designing and implementing a data platform in that sector.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Andrey Korchak about how to manage data in a fintech environment
Interview
Introduction How did you get involved in the area of data management? Can you start by summarizing the data challenges that are particular to the fintech ecosystem? What are the primary sources and types of data that fintech organizations are working with?
What are the business-level capabilities that are dependent on this data?
How do the regulatory and business requirements influence the technology landscape in fintech organizations?
What does a typical build vs. buy decision process look like?
Fraud prediction in e.g. banks is one of the most well-established applications of machine learning in industry. What are some of the other ways that ML plays a part in fintech?
How does that influence the architectural design/capabilities for data platforms in those organizations?
Data governance is a notoriously challenging problem. What are some of the strategies that fintech companies are able to apply to this problem given their regulatory burdens? What are the most interesting, innovative, or unexpected approaches to data management that you have seen in the fintech sector? What are the most interesting, unexpected, or challenging lessons that you have learned while working on data in fintech? What do you have planned for the future of your data capabilities at Monite?
Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Monite ISO 270001 Tesseract GitOps SWIFT Protocol
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Starburst: 
This episode is brought to you by Starburst - a data lake analytics platform for data engineers who are battling to build and scale high quality data pipelines on the data lake. Powered by Trino, Starburst runs petabyte-scale SQL analytics fast at a fraction of the cost of traditional methods, helping you meet all your data needs ranging from AI/ML workloads to data applications to complete analytics.
Trusted by the teams at Comcast and Doordash, Starburst delivers the adaptability and flexibility a lakehouse ecosystem promises, while providing a single point of access for your data and all your data governance allowing you to discover, transform, govern, and secure all in one place. Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Try Starburst Galaxy today, the easiest and fastest way to get started using Trino, and get $500 of credits free. dataengineeringpodcast.com/starburstRudderstack: 
Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstackMaterialize: 
You shouldn't have to throw away the database to build with fast-changing data. Keep the familiar SQL, keep the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date.
That is Materialize, the only true SQL streaming database built from the ground up to meet the needs of modern data products: Fresh, Correct, Scalable — all in a familiar SQL UI. Built on Timely Dataflow and Differential Dataflow, open source frameworks created by cofounder Frank McSherry at Microsoft Research, Materialize is trusted by data and engineering teams at Ramp, Pluralsight, Onward and more to build real-time data products without the cost, complexity, and development time of stream processing.
Go to materialize.com today and get 2 weeks free!Support Data Engineering Podcast
Summary
Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Operating it at scale, however, is notoriously challenging. Elad Eldor has experienced these challenges first-hand, leading to his work writing the book "Kafka: : Troubleshooting in Production". In this episode he highlights the sources of complexity that contribute to Kafka's operational difficulties, and some of the main ways to identify and mitigate potential sources of trouble.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Elad Eldor about operating Kafka in production and how to keep your clusters stable and performant
Interview
Introduction How did you get involved in the area of data management? Can you describe your experiences with Kafka?
What are the operational challenges that you have had to overcome while working with Kafka? What motivated to write a book about how to manage Kafka in production?
There are many options now for persistent data queues. What are the factors to consider when determining whether Kafka is the right choice?
In the case where Kafka is the appropriate tool, there are many ways to run it now. What are the considerations that teams need to work through when determining whether/where/how to operate a cluster?
When provisioning a Kafka cluster, what are the requirements that need to be considered when determining the sizing?
What are the axes along which size/scale need to be determined?
The core promise of Kafka is that it is a durable store for continuous data. What are the mechanisms that are available for preventing data loss?
Under what circumstances can data be lost?
What are the different failure conditions that cluster operators need to be aware of?
What are the monitoring strategies that ar
Summary
The "modern data stack" promised a scalable, composable data platform that gave everyone the flexibility to use the best tools for every job. The reality was that it left data teams in the position of spending all of their engineering effort on integrating systems that weren't designed with compatible user experiences. The team at 5X understand the pain involved and the barriers to productivity and set out to solve it by pre-integrating the best tools from each layer of the stack. In this episode founder Tarush Aggarwal explains how the realities of the modern data stack are impacting data teams and the work that they are doing to accelerate time to value.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm welcoming back Tarush Aggarwal to talk about what he and his team at 5x data are building to improve the user experience of the modern data stack.
Interview
Introduction How did you get involved in the area of data management? Can you describe what 5x is and the story behind it?
We last spoke in March of 2022. What are the notable changes in the 5x business and product?
What are the notable shifts in the data ecosystem that have influenced your adoption and product direction?
What trends are you most focused on tracking as you plan the continued evolution of your offerings?
What are the points of friction that teams run into when trying to build their data platform? Can you describe design of the system that you have built?
What are the strategies that you rely on to support adaptability and speed of onboarding for new integrations?
What are some of the types of edge cases that you have to deal with while integrating and operating the platform implementations that you design for your customers? What is your process for selection of vendors to support?
How would you characte
Summary
If your business metrics looked weird tomorrow, would you know about it first? Anomaly detection is focused on identifying those outliers for you, so that you are the first to know when a business critical dashboard isn't right. Unfortunately, it can often be complex or expensive to incorporate anomaly detection into your data platform. Andrew Maguire got tired of solving that problem for each of the different roles he has ended up in, so he created the open source Anomstack project. In this episode he shares what it is, how it works, and how you can start using it today to get notified when the critical metrics in your business aren't quite right.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Andrew Maguire about his work on the Anomstack project and how you can use it to run your own anomaly detection for your metrics
Interview
Introduction How did you get involved in the area of data management? Can you describe what Anomstack is and the story behind it?
What are your goals for this project? What other tools/products might teams be evaluating while they consider Anom

Valentina Tortolini: Unified Customer Data Management: Leveraging Warehouse-Native Customer Data Modeling for Informed Decision-Making
Dive into the future of data management with Valentina Tortolini as she explores Warehouse-Native Customer Data Modeling and its pivotal role in informed decision-making. 📈🤝 Discover privacy-centric approaches, cross-device user identification, and predictive cLTV models, all aimed at forging lasting customer relationships and driving growth. 📊🌐 #DataManagement #customerdata
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear
Effective data management has become a cornerstone of success in our digital era. It involves not just collecting and storing information but also organizing, securing, and leveraging data to drive progress and innovation. Many organizations turn to tools like Snowflake for advanced data warehousing capabilities. However, while Snowflake enhances data storage and access, it's not a complete solution for all data management challenges. To address this, tools like Capital One’s Slingshot can be used alongside Snowflake, helping to optimize costs and refine data management strategies. Salim Syed is a VP, Head of engineering for Capital One Slingshot product. He led Capital One’s data warehouse migration to AWS and is a specialist in deploying Snowflake to a large enterprise. Salim’s expertise lies in developing Big Data (Lake) and Data Warehouse strategy on the public cloud. He leads an organization of more than 100 data engineers, support engineers, DBAs and full stack developers in driving enterprise data lake, data warehouse, data management and visualization platform services. Salim has more than 25 years of experience in the data ecosystem. His career started in data engineering where he built data pipelines and then moved into maintenance and administration of large database servers using multi-tier replication architecture in various remote locations. He then worked at CodeRye as a database architect and at 3M Health Information Systems as an enterprise data architect. Salim has been at Capital One for the past six years. In this episode, Adel and Salim explore cloud data management and the evolution of Slingshot into a major multi-tenant SaaS platform, the shift from on-premise to cloud-based data governance, the role of centralized tooling, strategies for effective cloud data management, including data governance, cost optimization, and waste reduction as well as insights into navigating the complexities of data infrastructure, security, and scalability in the modern digital era. Links Mentioned in the Show: Capital One SlingshotSnowflakeCourse: Introduction to Data WarehousingCourse: Introduction to Snowflake
Summary
The first step of data pipelines is to move the data to a place where you can process and prepare it for its eventual purpose. Data transfer systems are a critical component of data enablement, and building them to support large volumes of information is a complex endeavor. Andrei Tserakhau has dedicated his careeer to this problem, and in this episode he shares the lessons that he has learned and the work he is doing on his most recent data transfer system at DoubleCloud.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues for every part of your data workflow, from migration to deployment. Datafold has recently launched a 3-in-1 product experience to support accelerated data migrations. With Datafold, you can seamlessly plan, translate, and validate data across systems, massively accelerating your migration project. Datafold leverages cross-database diffing to compare tables across environments in seconds, column-level lineage for smarter migration planning, and a SQL translator to make moving your SQL scripts easier. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold today! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Andrei Tserakhau about operationalizing high bandwidth and low-latency change-data capture
Interview
Introduction How did you get involved in the area of data management? Your most recent project involves operationalizing a generalized data transfer service. What was the original problem that you were trying to solve?
What were the shortcomings of other options in the ecosystem that led you to building a new system?
What was the design of your initial solution to the problem?
What are the sharp edges that you had to deal with to operate and use that i
What exactly is #DataManagement? How can it help us #monetize the data we have? And does this help with things like protecting #datasources? We discuss all these #questions and more on this latest #podcast episode of Data Unchained as #CEO and #CoFounder of Masthead Data, Yuliia Tkachova joins us to discus these topics and how her business is #disrupting the #industry.
datapipeline #datatables #bigdata #technology #hightech
Cyberpunk by jiglr | https://soundcloud.com/jiglrmusic Music promoted by https://www.free-stock-music.com Creative Commons Attribution 3.0 Unported License https://creativecommons.org/licenses/by/3.0/deed.en_US Hosted on Acast. See acast.com/privacy for more information.

The book "Vector Search for Practitioners with Elastic" provides a comprehensive guide to leveraging vector search technology within Elastic for applications in NLP, cybersecurity, and observability. By exploring practical examples and advanced techniques, this book teaches you how to optimize and implement vector search to address complex challenges in modern data management. What this Book will help me do Gain a deep understanding of implementing vector search with Elastic. Learn techniques to optimize vector data storage and retrieval for practical applications. Understand how to apply vector search for image similarity in Elastic. Discover methods for utilizing vector search for security and observability enhancements. Develop skills to integrate modern NLP tools with vector databases and Elastic. Author(s) Bahaaldine Azarmi, with his extensive experience in Elastic and NLP technologies, brings a practitioner's insight into the world of vector search. Co-author None Vestal contributes expertise in observability and system optimization. Together, they deliver practical and actionable knowledge in a clear and approachable manner. Who is it for? This book is designed for data professionals seeking to deepen their expertise in vector search and Elastic technologies. It is ideal for individuals in observability, search technology, or cybersecurity roles. If you have foundational knowledge in machine learning models, Python, and Elastic, this book will enable you to effectively utilize vector search in your projects.
Summary
Building a data platform that is enjoyable and accessible for all of its end users is a substantial challenge. One of the core complexities that needs to be addressed is the fractal set of integrations that need to be managed across the individual components. In this episode Tobias Macey shares his thoughts on the challenges that he is facing as he prepares to build the next set of architectural layers for his data platform to enable a larger audience to start accessing the data being managed by his team.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Developing event-driven pipelines is going to be a lot easier - Meet Functions! Memphis functions enable developers and data engineers to build an organizational toolbox of functions to process, transform, and enrich ingested events “on the fly” in a serverless manner using AWS Lambda syntax, without boilerplate, orchestration, error handling, and infrastructure in almost any language, including Go, Python, JS, .NET, Java, SQL, and more. Go to dataengineeringpodcast.com/memphis today to get started! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'll be sharing an update on my own journey of building a data platform, with a particular focus on the challenges of tool integration and maintaining a single source of truth
Interview
Introduction How did you get involved in the area of data management? data sharing weight of history
existing integrations with dbt switching cost for e.g. SQLMesh de facto standard of Airflow
Single source of truth
permissions management across application layers Database engine Storage layer in a lakehouse Presentation/access layer (BI) Data flows dbt -> table level lineage orchestration engine -> pipeline flows
task based vs. asset based
Metadata platform as the logical place for horizontal view
Contact Info
LinkedIn Website
Parting Questio
Summary
The dbt project has become overwhelmingly popular across analytics and data engineering teams. While it is easy to adopt, there are many potential pitfalls. Dustin Dorsey and Cameron Cyr co-authored a practical guide to building your dbt project. In this episode they share their hard-won wisdom about how to build and scale your dbt projects.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Dustin Dorsey and Cameron Cyr about how to design your dbt projects
Interview
Introduction How did you get involved in the area of data management? What was your path to adoption of dbt?
What did you use prior to its existence? When/why/how did you start using it?
What are some of the common challenges that teams experience when getting started with dbt?
How does prior experience in analytics and/or software engineering impact those outcomes?
You recently wrote a book to give a crash course in best practices for dbt. What motivated you to invest that time and effort?
What new lessons did you learn about dbt in the process of writing the book?
The introduction of dbt is largely res
I recap two events from this week - Matillion's Data Unlocked and the first MLOps Community event in Silicon Valley, hosted at Coactive.ai's office. Lots to unpack in 8 minutes, so let's get going.
Join host Jason Foster and Laura Sebastian-Coleman, VP of Data Management and Governance at Prudential Financial, for an insightful discussion around the intricate challenges organisations face in managing data effectively. Laura delves into the complexities of data connectivity and the difficulties in visualising and utilising data optimally, shedding light on the relationship between data management and decision-making. She shares valuable insights into the cultural perspective of data management, emphasising the need for awareness, formalisation of successful practices, and the pivotal role of leadership in nurturing a data-centric culture.
Data democratization is the buzzword to describe empowering enterprise stakeholders with data. While there have been advances in data management, governance, and analytics, something keeps getting in the way of achieving data democratization. Published at: https://www.eckerson.com/articles/data-democratization-and-the-duties-of-data-citizenship
Summary
Software development involves an interesting balance of creativity and repetition of patterns. Generative AI has accelerated the ability of developer tools to provide useful suggestions that speed up the work of engineers. Tabnine is one of the main platforms offering an AI powered assistant for software engineers. In this episode Eran Yahav shares the journey that he has taken in building this product and the ways that it enhances the ability of humans to get their work done, and when the humans have to adapt to the tool.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Eran Yahav about building an AI powered developer assistant at Tabnine
Interview
Introduction How did you get involved in machine learning? Can you describe what Tabnine is and the story behind it? What are the individual and organizational motivations for using AI to generate code?
What are the real-world limitations of generative AI for creating software? (e.g. size/complexity of the outputs, naming conventions, etc.) What are the elements of skepticism/overs
Summary
Databases are the core of most applications, but they are often treated as inscrutable black boxes. When an application is slow, there is a good probability that the database needs some attention. In this episode Lukas Fittl shares some hard-won wisdom about the causes and solution of many performance bottlenecks and the work that he is doing to shine some light on PostgreSQL to make it easier to understand how to keep it running smoothly.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Lukas Fittl about optimizing your database performance and tips for tuning Postgres
Interview
Introduction How did you get involved in the area of data management? What are the different ways that database performance problems impact the business? What are the most common contributors to performance issues? What are the useful signals that indicate performance challenges in the database?
For a given symptom, what are the steps that you recommend for determining the proximate cause?
What are the potential negative impacts to be aware of when tu
Summary
Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Your host is Tobias Macey and today I'm interviewing Tanya Bragin about her views on the database products market
Interview
Introduction How did you get involved in the area of data management? What are the aspects of the database market that keep you interested as a VP of product?
How have your experiences at Elastic informed your current work at Clickhouse?
What are the main product categories for databases today?
What are the industry trends that have the most impact on the development and growth of different product categories? Which categories do you see growing the fastest?
When a team is selecting a database technology for a given task, what are the types of questions that they should be asking? Transactional engines like Postgres, SQL Server, Oracle, etc. were long used
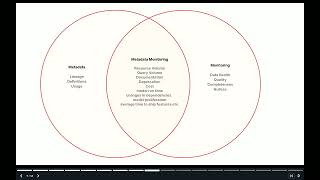
Explore the pivotal role of metadata monitoring in revolutionizing your data team’s operations. Uncover how metadata serves as the key ingredient in addressing cost-related challenges, data monitoring, and mitigating ever-growing data sprawl. Discover its crucial function in cost-effective data management and compliance assurance.
Using real-world examples and practical tips, learn how to empower data stewards to proactively address systemic issues, optimize storage and resource allocation, and strategically guide the evolution of data infrastructures to align with organizational goals. Understand how to unlock the potential of metadata, and gain a fresh perspective on optimizing your data strategy.
Speaker: Etai Mizrahi, Co-Founder & CEO, Secoda
Register for Coalesce at https://coalesce.getdbt.com