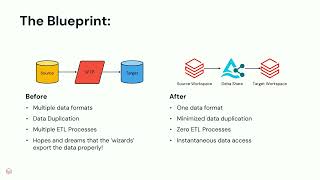
Ready to take your AI/BI dashboards to the next level? This session dives into the latest capabilities in Databricks AI/BI Dashboards and how to maximize impact across your organization. Learn how data authors can tailor visualizations for different audiences, optimize performance and seamlessly integrate with Genie for a unified analytics experience. We’ll also share practical tips on how business users and data teams can better collaborate — ensuring insights are accessible, actionable and aligned to business goals.