Daniel will take a hands-on journey into building AI analyst agents from scratch. Using dbt metadata to provide large language models with the right context, he’ll show how to connect LLMs to your data effectively. Expect a deep dive into the challenges of query generation, practical frameworks for success, and lessons learned from real-world implementations.
 talk-data.com
talk-data.com
Topic
dbt
dbt (data build tool)
data_transformation
analytics_engineering
sql
758
tagged
Activity Trend
134
peak/qtr
2020-Q1
2026-Q2
Top Events
In this twofold session, I'll cover how we've used dbt to bring order in heaps of SQL statements used to manage a datawarehouse. I'd like to share how dbt made our team more efficient and our data warehouse more resilient. Secondly, I'll highlight why dbt enabled a way forward on supporting low-code applications: by leveraging our data warehouse as a backend. I'll dive into systemic design, application architecture & data modelling. Tools/tech covered will be SQL, Trino, Outsystems, GIT, Airflow and of course dbt! Expect practical insights, architectural patterns, and lessons learned from a real-world implementation.
Using email personalisation tools is not enough. True impact comes when your efforts are powered by data that is always consistent and unified across systems. In this session, Miši will show us how Slido leverages dbt models to drive engaging client communication while ensuring that data remains accurate and harmonised throughout all systems.
Lukáš Kozelnický will walk us through the production-grade dbt implementation that powers Muziker, Europe's leading musical instrument e-commerce platform operating across 30+ countries. He will explore the data warehouse that: Handles complex multi-currency operations; Integrates 50+ data sources; Features sophisticated AI-powered inventory optimisation. Let’s compare Muziker’s setup 4 years ago with their data platform today to see what has changed in the analytics world, how the new approach empowers the business, and how the data culture at the company has changed to support this shift.
Managing dbt for 150 analytics engineers meant evolving from fragmented dbt Core projects to unified standards, migrating to dbt Cloud. We solved security risks and inconsistent practices through standardization and centralized workflows, while maintaining our Airflow orchestration. Challenges remain in balancing governance with analyst autonomy at scale.
Let's explore the capabilities of dbt's brand-new engine: Fusion. We’ll explore it from different angles, such as performance, functionalities, and how it transforms the developer experience.
Summary In this episode of the Data Engineering Podcast Omri Lifshitz (CTO) and Ido Bronstein (CEO) of Upriver talk about the growing gap between AI's demand for high-quality data and organizations' current data practices. They discuss why AI accelerates both the supply and demand sides of data, highlighting that the bottleneck lies in the "middle layer" of curation, semantics, and serving. Omri and Ido outline a three-part framework for making data usable by LLMs and agents: collect, curate, serve, and share challenges of scaling from POCs to production, including compounding error rates and reliability concerns. They also explore organizational shifts, patterns for managing context windows, pragmatic views on schema choices, and Upriver's approach to building autonomous data workflows using determinism and LLMs at the right boundaries. The conversation concludes with a look ahead to AI-first data platforms where engineers supervise business semantics while automation stitches technical details end-to-end.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData teams everywhere face the same problem: they're forcing ML models, streaming data, and real-time processing through orchestration tools built for simple ETL. The result? Inflexible infrastructure that can't adapt to different workloads. That's why Cash App and Cisco rely on Prefect. Cash App's fraud detection team got what they needed - flexible compute options, isolated environments for custom packages, and seamless data exchange between workflows. Each model runs on the right infrastructure, whether that's high-memory machines or distributed compute. Orchestration is the foundation that determines whether your data team ships or struggles. ETL, ML model training, AI Engineering, Streaming - Prefect runs it all from ingestion to activation in one platform. Whoop and 1Password also trust Prefect for their data operations. If these industry leaders use Prefect for critical workflows, see what it can do for you at dataengineeringpodcast.com/prefect.Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Composable data infrastructure is great, until you spend all of your time gluing it together. Bruin is an open source framework, driven from the command line, that makes integration a breeze. Write Python and SQL to handle the business logic, and let Bruin handle the heavy lifting of data movement, lineage tracking, data quality monitoring, and governance enforcement. Bruin allows you to build end-to-end data workflows using AI, has connectors for hundreds of platforms, and helps data teams deliver faster. Teams that use Bruin need less engineering effort to process data and benefit from a fully integrated data platform. Go to dataengineeringpodcast.com/bruin today to get started. And for dbt Cloud customers, they'll give you $1,000 credit to migrate to Bruin Cloud.Your host is Tobias Macey and today I'm interviewing Omri Lifshitz and Ido Bronstein about the challenges of keeping up with the demand for data when supporting AI systemsInterview IntroductionHow did you get involved in the area of data management?We're here to talk about "The Growing Gap Between Data & AI". From your perspective, what is this gap, and why do you think it's widening so rapidly right now?How does this gap relate to the founding story of Upriver? What problems were you and your co-founders experiencing that led you to build this?The core premise of new AI tools, from RAG pipelines to LLM agents, is that they are only as good as the data they're given. How does this "garbage in, garbage out" problem change when the "in" is not a static file but a complex, high-velocity, and constantly changing data pipeline?Upriver is described as an "intelligent agent system" and an "autonomous data engineer." This is a fascinating "AI to solve for AI" approach. Can you describe this agent-based architecture and how it specifically works to bridge that data-AI gap?Your website mentions a "Data Context Layer" that turns "tribal knowledge" into a "machine-usable mode." This sounds critical for AI. How do you capture that context, and how does it make data "AI-ready" in a way that a traditional data catalog or quality tool doesn't?What are the most innovative or unexpected ways you've seen companies trying to make their data "AI-ready"? And where are the biggest points of failure you observe?What has been the most challenging or unexpected lesson you've learned while building an AI system (Upriver) that is designed to fix the data foundation for other AI systems?When is an autonomous, agent-based approach not the right solution for a team's data quality problems? What organizational or technical maturity is required to even start closing this data-AI gap?What do you have planned for the future of Upriver? And looking more broadly, how do you see this gap between data and AI evolving over the next few years?Contact Info Ido - LinkedInOmri - LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links UpriverRAG == Retrieval Augmented GenerationAI Engineering Podcast EpisodeAI AgentContext WindowModel Finetuning)The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Join Toyota Motor Europe to discover their journey towards a fully operationalized Data Mesh with dbt and Snowflake.
TME (Toyota Motos Europe), one of biggest automobile manufacturing companies, oversees the wholesale sales and marketing of Toyota and Lexus vehicles in Europe. This session will showcase how dbt Cloud and Snowflake are supporting their data strategy.
They will elaborate on challenges faced along the way, and how their platform is supporting their future vision, e.g. enabling advanced real-time analytics, scaling while maintaining governance and best practices and setting themselves up with a strong data foundation to launch their AI/ML initiatives.

This practical, in-depth guide shows you how to build modern, sophisticated data processes using the Snowflake platform and DataOps.live —the only platform that enables seamless DataOps integration with Snowflake. Designed for data engineers, architects, and technical leaders, it bridges the gap between DataOps theory and real-world implementation, helping you take control of your data pipelines to deliver more efficient, automated solutions. . You’ll explore the core principles of DataOps and how they differ from traditional DevOps, while gaining a solid foundation in the tools and technologies that power modern data management—including Git, DBT, and Snowflake. Through hands-on examples and detailed walkthroughs, you’ll learn how to implement your own DataOps strategy within Snowflake and maximize the power of DataOps.live to scale and refine your DataOps processes. Whether you're just starting with DataOps or looking to refine and scale your existing strategies, this book—complete with practical code examples and starter projects—provides the knowledge and tools you need to streamline data operations, integrate DataOps into your Snowflake infrastructure, and stay ahead of the curve in the rapidly evolving world of data management. What You Will Learn Explore the fundamentals of DataOps , its differences from DevOps, and its significance in modern data management Understand Git’s role in DataOps and how to use it effectively Know why DBT is preferred for DataOps and how to apply it Set up and manage DataOps.live within the Snowflake ecosystem Apply advanced techniques to scale and evolve your DataOps strategy Who This Book Is For Snowflake practitioners—including data engineers, platform architects, and technical managers—who are ready to implement DataOps principles and streamline complex data workflows using DataOps.live.
With Fivetran and DBT becoming a common tooling pair, lets dive into how Fivetran can take care of our Extract, Loading and DBT to deal with the transformation logic. This tooling changes our data stack as we move closer to the domain and back to data modelling. We will look at the cost models and give some of the decision points to decide if this is valuable to your team and your business.
Learn about a framework of tests and macros that can be deployed within a dbt Project to protect data quality and secure trust in data.
Catch up on the latest dbt news from Coalesce and find out highlights, need to knows from the conference!
Overview of how DoubleVerify applied core programming principles (abstraction, modularity, DRY) to transform scattered SQL into reusable DBT packages. A three-layer architecture—raw data, standardized signals, and modular packages—enables building scalable, reusable DBT pipelines that work with any conforming input and reduce onboarding time.
Summary In this episode of the Data Engineering Podcast Matt Topper, president of UberEther, talks about the complex challenge of identity, credentials, and access control in modern data platforms. With the shift to composable ecosystems, integration burdens have exploded, fracturing governance and auditability across warehouses, lakes, files, vector stores, and streaming systems. Matt shares practical solutions, including propagating user identity via JWTs, externalizing policy with engines like OPA/Rego and Cedar, and using database proxies for native row/column security. He also explores catalog-driven governance, lineage-based label propagation, and OpenTDF for binding policies to data objects. The conversation covers machine-to-machine access, short-lived credentials, workload identity, and constraining access by interface choke points, as well as lessons from Zanzibar-style policy models and the human side of enforcement. Matt emphasizes the need for trust composition - unifying provenance, policy, and identity context - to answer questions about data access, usage, and intent across the entire data path.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData teams everywhere face the same problem: they're forcing ML models, streaming data, and real-time processing through orchestration tools built for simple ETL. The result? Inflexible infrastructure that can't adapt to different workloads. That's why Cash App and Cisco rely on Prefect. Cash App's fraud detection team got what they needed - flexible compute options, isolated environments for custom packages, and seamless data exchange between workflows. Each model runs on the right infrastructure, whether that's high-memory machines or distributed compute. Orchestration is the foundation that determines whether your data team ships or struggles. ETL, ML model training, AI Engineering, Streaming - Prefect runs it all from ingestion to activation in one platform. Whoop and 1Password also trust Prefect for their data operations. If these industry leaders use Prefect for critical workflows, see what it can do for you at dataengineeringpodcast.com/prefect.Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Composable data infrastructure is great, until you spend all of your time gluing it together. Bruin is an open source framework, driven from the command line, that makes integration a breeze. Write Python and SQL to handle the business logic, and let Bruin handle the heavy lifting of data movement, lineage tracking, data quality monitoring, and governance enforcement. Bruin allows you to build end-to-end data workflows using AI, has connectors for hundreds of platforms, and helps data teams deliver faster. Teams that use Bruin need less engineering effort to process data and benefit from a fully integrated data platform. Go to dataengineeringpodcast.com/bruin today to get started. And for dbt Cloud customers, they'll give you $1,000 credit to migrate to Bruin Cloud.Your host is Tobias Macey and today I'm interviewing Matt Topper about the challenges of managing identity and access controls in the context of data systemsInterview IntroductionHow did you get involved in the area of data management?The data ecosystem is a uniquely challenging space for creating and enforcing technical controls for identity and access control. What are the key considerations for designing a strategy for addressing those challenges?For data acess the off-the-shelf options are typically on either extreme of too coarse or too granular in their capabilities. What do you see as the major factors that contribute to that situation?Data governance policies are often used as the primary means of identifying what data can be accesssed by whom, but translating that into enforceable constraints is often left as a secondary exercise. How can we as an industry make that a more manageable and sustainable practice?How can the audit trails that are generated by data systems be used to inform the technical controls for identity and access?How can the foundational technologies of our data platforms be improved to make identity and authz a more composable primitive?How does the introduction of streaming/real-time data ingest and delivery complicate the challenges of security controls?What are the most interesting, innovative, or unexpected ways that you have seen data teams address ICAM?What are the most interesting, unexpected, or challenging lessons that you have learned while working on ICAM?What are the aspects of ICAM in data systems that you are paying close attention to?What are your predictions for the industry adoption or enforcement of those controls?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links UberEtherJWT == JSON Web TokenOPA == Open Policy AgentRegoPingIdentityOktaMicrosoft EntraSAML == Security Assertion Markup LanguageOAuthOIDC == OpenID ConnectIDP == Identity ProviderKubernetesIstioAmazon CEDAR policy languageAWS IAMPII == Personally Identifiable InformationCISO == Chief Information Security OfficerOpenTDFOpenFGAGoogle ZanzibarRisk Management FrameworkModel Context ProtocolGoogle Data ProjectTPM == Trusted Platform ModulePKI == Public Key InfrastructurePassskeysDuckLakePodcast EpisodeAccumuloJDBCOpenBaoHashicorp VaultLDAPThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Date: 2025-10-23. Joint webinar showing how a modern data integration layer can transform Bayesian Marketing Mix Models (MMMs). From automated data ingestion and standardization with Fivetran connectors and dbt models to Bayesian inference and performance optimization with PyMC-Marketing. You will learn: unify ad and commerce data across platforms; transform standardized tables into model-ready datasets; run Bayesian MMMs with uncertainty quantification, adstock and saturation effects, and budget optimization; and scale a production-ready MMM pipeline across markets and brands. Start time: 15:00 UTC (8:00 PT / 11:00 ET / 5:00 Berlin).
Ryan Dolley, VP of Product Strategy at GoodData and co-host of Super Data Brothers podcast, joined Yuliia and Dumke to discuss the DBT-Fivetran merger and what it signals about the modern data stack's consolidation phase. After 16 years in BI and analytics, Ryan explains why BI adoption has been stuck at 27% for a decade and why simply adding AI chatbots won't solve it. He argues that at large enterprises, purchasing new software is actually the only viable opportunity to change company culture - not because of the features, but because it forces operational pauses and new ways of working. Ryan shares his take that AI will struggle with BI because LLMs are trained to give emotionally satisfying answers rather than accurate ones. Ryan Dolley linkedin
Learn how Fresha scaled Snowflake to 100k users and hear the key lessons from their embedded analytics journey with dbt.
Register here to save your spot! Join Tristan from dbt and Barry from Hex for a fireside chat and Q&A, discussing everything dbt launched at Coalesce, the future of the data stack, and why they’re bullish on data teams. Plus, network with your peers and fellow conference-goers over happy hour drinks, snacks and data-filled discussions.
Take a break from the hustle and bustle to come hang out with the LGBTQIA+ data nerds. dbt Labs’ Queeries ERG is hosting a casual, alcohol-free hangout with snacks and good vibes in the cozy dbt full refresh Room. At seven, we'll head to the Coalesce Party together with all our new friends. All are welcome.
by
Noritaka Sekiyama
(Amazon Web Services (AWS))
,
Venkatesh Aravamudan
(Amazon Web Services (AWS))
,
Neela Kulkarni
(AWS)
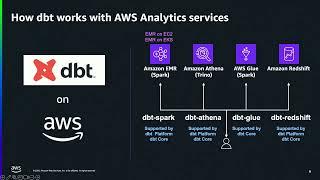
As organizations increasingly adopt modern data stacks, the combination of dbt and AWS Analytics services emerged as a powerful pairing for analytics engineering at scale. This session will explore proven strategies and hard-learned lessons for optimizing this technology stack to use dbt-athena, dbt-redshift, and dbt-glue to deliver reliable, performant data transformations. We will also cover case studies, best practices, and modern lakehouse scenarios with Apache Iceberg and Amazon S3 Tables.