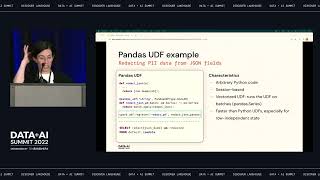
This talk discusses “software-defined assets”, a declarative approach to orchestration and data management that makes it drastically easier to trust and evolve datasets and ML models. Dagster is an open source orchestrator built for maintaining software-defined assets.
In traditional data platforms, code and data are only loosely coupled. As a consequence, deploying changes to data feels dangerous, backfills are error-prone and irreversible, and it’s difficult to trust data, because you don’t know where it comes from or how it’s intended to be maintained. Each time you run a job that mutates a data asset, you add a new variable to account for when debugging problems.
Dagster proposes an alternative approach to data management that tightly couples data assets to code - each table or ML model corresponds to the function that’s responsible for generating it. This results in a “Data as Code” approach that mimics the “Infrastructure as Code” approach that’s central to modern DevOps. Your git repo becomes your source of truth on your data, so pushing data changes feels as safe as pushing code changes. Backfills become easy to reason about. You trust your data assets because you know how they’re computed and can reproduce them at any time. The role of the orchestrator is to ensure that physical assets in the data warehouse match the logical assets that are defined in code, so each job run is a step towards order.
Software-defined assets is a natural approach to orchestration for the modern data stack, in part because dbt models are a type of software-defined asset.
Attendees of this session will learn how to build and maintain lakehouses of software-defined assets with Dagster.
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/data...
Instagram: https://www.instagram.com/databricksinc/