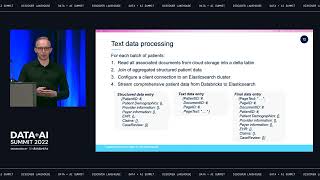
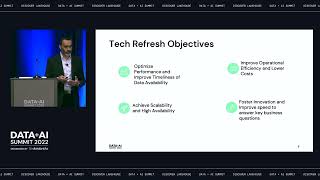
Transform your generative AI model development with checkpointless and elastic training on Amazon SageMaker HyperPod. Learn how checkpointless training eliminates costly downtime by automatically recovering from infrastructure faults in minutes instead of hours, using peer-to-peer state transfer without relying on restarting from checkpoints. Discover how elastic training can dynamically expand to claim idle accelerators or gracefully contract when higher-priority tasks need capacity, all without manual intervention. See how these innovations help you maintain forward training momentum despite infrastructure faults or fluctuations in resource availability, helping you scale and accelerate generative AI model development across hundreds to thousands of AI accelerators.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.