
This session delivers a blueprint for building, deploying, and managing agents in a secure, scalable, and cost-effective manner on Google Cloud, bridging the critical gap between development and operations.
Topic
Google Cloud Platform (GCP)
24
tagged
This session delivers a blueprint for building, deploying, and managing agents in a secure, scalable, and cost-effective manner on Google Cloud, bridging the critical gap between development and operations.
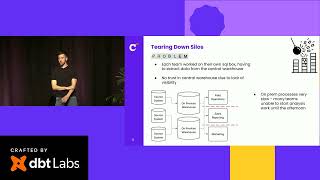
Merging two large organizations with different tools, teams, and data practices is never simple. At Virgin Media O2, we used dbt to help bring consistency to that complexity, building a hybrid data mesh that supported self-serve analytics across domains. In this session, we’ll share how we gave teams clearer ownership, put governance in place using dbt, and set up secure data sharing through GCP’s Analytics Hub. If you’re working in a federated or fast-changing environment, this session offers practical lessons for making self-serve work at scale.

The data world has long been divided, with data engineers and data scientists working in silos. This fragmentation creates a long, difficult journey from raw data to machine learning models. We've unified these worlds through the Google Cloud and dbt partnership. In this session, we'll show you an end-to-end workflow that simplifies data to AI journey. The availability of dbt Cloud on Google Cloud Marketplace streamlines getting started, and its integration with BigQuery's new Apache Iceberg tables creates an open foundation. We'll also highlight how BigQuery DataFrames' integration with dbt Python models lets you perform complex data science at scale, all within a single, streamlined process. Join us to learn how to build a unified data and AI platform with dbt on Google Cloud.

Enterprise customers need a powerful and adaptable data foundation to navigate demands of AI and multi-cloud environments. This session dives into how Google Cloud Storage serves as a unified platform for modern analytics data lakes, together with Databricks. Discover how Google Cloud Storage provides key innovations like performance optimizations for Apache Iceberg, Anywhere Cache as the easiest way to colocate storage and compute, Rapid Storage for ultra low latency object reads and appends, and Storage Intelligence for vital data insights and recommendations. Learn how you can optimize your infrastructure to unlock the full value of your data for AI-driven success.

In this session you will learn how to leverage a wide set of GenAI models in Databricks, including external connections to cloud vendors and other model providers. We will cover establishing connection to externally served models, via Mosaic AI Gateway. This will showcase connection to Azure, AWS & Google Cloud models, as well as model vendors like Anthropic, Cohere, AI21 Labs and more. You will also discover best practices on model comparison, governance and cost control on those model deployments.

Maximize the performance of your Databricks Platform with innovations on Google Cloud. Discover how Google's Arm-based Axion C4A virtual machines (VMs) deliver breakthrough price-performance and efficiency for Databricks, supercharging Databricks Photon engine. Gain actionable strategies to optimize your Databricks deployments on Google Cloud.

This session unveils Google Cloud's Agent2Agent (A2A) protocol, ushering in a new era of AI interoperability where diverse agents collaborate seamlessly to solve complex enterprise challenges. Join our panel of experts to discover how A2A empowers you to deeply integrate these collaborative AI systems with your existing enterprise data, custom APIs, and critical workflows. Ultimately, learn to build more powerful, versatile, and securely managed agentic ecosystems by combining specialized Google-built agents with your own custom solutions (Vertex AI or no-code). Extend this ecosystem further by serving these agents with Databricks Model Serving and governing them with Unity Catalog for consistent security and management across your enterprise.

Building an open data lakehouse? Start with the right blueprint. This session walks through common reference architectures for interoperable lakehouse deployments across AWS, Google Cloud, Azure and tools like Snowflake, BigQuery and Microsoft Fabric. Learn how to design for cross-platform data access, unify governance with Unity Catalog and ensure your stack is future-ready — no matter where your data lives.

In this session, we’ll walk through the latest advancements in platform security and compliance on Databricks — from networking updates to encryption, serverless security and new compliance certifications across AWS, Azure and Google Cloud. We’ll also share our roadmap and best practices for how to securely configure workloads on Databricks SQL Serverless, Unity Catalog, Mosaic AI and more — at scale. If you're building on Databricks and want to stay ahead of evolving risk and regulatory demands, this session is your guide.

Elevate your AI initiatives on Databricks by harnessing the latest advancements in Google Cloud's Gemini models. Learn how to integrate Gemini's built-in reasoning and powerful development tools to build more dynamic and intelligent applications within your existing Databricks platform. We'll explore concrete ideas for agentic AI solutions, showcasing how Gemini can help you unlock new value from your data in Databricks.

Effective Identity and Access Management (IAM) is essential for securing enterprise environments while enabling innovation and collaboration. As companies scale, ensuring users have the right access without adding administrative overhead is critical. In this session, we’ll explore how Databricks is simplifying identity management by integrating with customers’ Identity Providers (IDPs). Learn about Automatic Identity Management in Azure Databricks, which eliminates SCIM for Entra ID users and ensures scalable identity provisioning for other IDPs. We'll also cover externally managed groups, PIM integration and upcoming enhancements like a bring-your-own-IDP model for Google Cloud. Through a customer success story and live demo, see how Databricks is making IAM more scalable, secure and user-friendly.

Leveraging Databricks as a platform, we facilitate the sharing of anonymized datasets across various Databricks workspaces and accounts, spanning multiple cloud environments such as AWS, Azure, and Google Cloud. This capability, powered by Delta Sharing, extends both within and outside Sleep Number, enabling accelerated insights while ensuring compliance with data security and privacy standards. In this session, we will showcase our architecture and implementation strategy for data sharing, highlighting the use of Databricks’ Unity Catalog and Delta Sharing, along with integration with platforms like Jira, Jenkins, and Terraform to streamline project management and system orchestration.

Delta Lake is a fantastic technology for quickly querying massive data sets, but first you need those massive data sets! In this session we will dive into the cloud-native architecture Scribd has adopted to ingest data from AWS Aurora, SQS, Kinesis Data Firehose and more. By using off-the-shelf open source tools like kafka-delta-ingest, oxbow and Airbyte, Scribd has redefined its ingestion architecture to be more event-driven, reliable, and most importantly: cheaper. No jobs needed! Attendees will learn how to use third-party tools in concert with a Databricks and Unity Catalog environment to provide a highly efficient and available data platform. This architecture will be presented in the context of AWS but can be adapted for Azure, Google Cloud Platform or even on-premise environments.

We aim to illustrate the transition from an antiquated methodology for generating final tables/views in Google Cloud Platform (GCP) to the implementation of a structured process utilizing dbt.
This transition involves defining how we develop source, staging, intermediate, and final models within dbt, facilitating enhanced change management and error detection mechanisms. We will talk about how far we have come and our plan to maintain this work-stream.
Speaker: Kyle Salomon Business Analytics Manager LiveRamp
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Discover the journey of building recommendation systems for global e-commerce marketplaces with Bongani Shongwe. 🌐🛍️ Learn how Adevinta leveraged Vertex AI (GCP-managed Kubeflow) to streamline the development of recommender models, and find out the benefits it offers, empowering Data Scientists to produce production-ready code efficiently. 🤖💼 #RecommendationSystems #machinelearning
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear

Explore Apache Beam with David Regalado, a seasoned data practitioner and Google Cloud Champion Innovator. Join his session for a gentle introduction to this powerful tool! 🌐📊 #ApacheBeam #datainnovationsummit
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear

Join Damian Filonowicz as he shares 'Lessons Learned from the GCP Data Migration.' 🌐 Discover how PAYBACK tackled challenges in shifting data to the cloud, navigated privacy regulations, and uncovered insights about Google Cloud services like Cloud Dataflow, Cloud DLP, BigQuery, and more. Gain valuable suggestions for future endeavors in this enlightening presentation! 🚀🔍 #DataMigration #GCP #lessonslearned
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear

Karim Wadie: Don’t Worry About BigQuery PII: How Google Cloud Helped a Large Telco Automate Data Governance at Scale
Discover how Google Cloud helped a large Telco automate data governance at scale in BigQuery with Karim Wadie. 📊🔒 Learn about the technical solution, GCP concepts, and see a live demo to fast-track your cloud journey. 🌐💡 #DataGovernance #BigQuery #googlecloud
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear

This talk was recorded at Crunch Conference 2022. Zoltán and Gergely from Aliz.ai company spoke about FinOps examples using Google Cloud BigQuery.
"In this talk we will talk about the basics of FinOps concept and going to make an introduction to it through real life examples using BigQuery."
The event was organized by Crafthub.
You can watch the rest of the conference talks on our channel.
If you are interested in more speakers, tickets and details of the conference, check out our website: https://crunchconf.com/ If you are interested in more events from our company: https://crafthub.events/

Databricks workflows has come a long way since the initial days of orchestrating simple notebooks and jar/wheel files. Now we can orchestrate multi-task jobs and create a chain of tasks with lineage and DAG with either fan-in or fan-out among multiple other patterns or even run another Databricks job directly inside another job.
Databricks workflows takes its tag: “orchestrate anything anywhere” pretty seriously and is a truly fully-managed, cloud-native orchestrator to orchestrate diverse workloads like Delta Live Tables, SQL, Notebooks, Jars, Python Wheels, dbt, SQL, Apache Spark™, ML pipelines with excellent monitoring, alerting and observability capabilities as well. Basically, it is a one-stop product for all orchestration needs for an efficient lakehouse. And what is even better is, it gives full flexibility of running your jobs in a cloud-agnostic and cloud-independent way and is available across AWS, Azure and GCP.
In this session, we will discuss and deep dive on some of the very interesting features and will showcase end-to-end demos of the features which will allow you to take full advantage of Databricks workflows for orchestrating the lakehouse.
Talk by: Prashanth Babu
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc