A talk about re-implementing the React useState hook using Vanilla JavaScript.
 talk-data.com
talk-data.com
Topic
React
javascript_library
front_end
web_development
99
tagged
Activity Trend
9
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Engineering Books
12
O'Reilly Data Science Books
6
Data Engineering Podcast
5
Making Data Simple
4
Experiencing Data w/ Brian T. O’Neill (AI & data product management leadership—powered by UX design)
4
Data + AI Summit 2025
4
Databricks DATA + AI Summit 2023
4
React Paris Meetup #007
3
React Paris Meetup #5
3
Airflow Summit 2025
2
React Paris Meetup #1
2
React.NYC Meetup - React Threads, Type Safety, Isograph & more
2
Welcome to another curated, Promoted Episode of Experiencing Data!
In episode 144, Shashank Garg, Co-Founder and CEO of Infocepts, joins me to explore whether all this discussion of data products out on the web actually has substance and is worth the perceived extra effort. Do we always need to take a product approach for ML and analytics initiatives? Shashank dives into how Infocepts approaches the creation of data solutions that are designed to be actionable within specific business workflows—and as I often do, I started out by asking Shashank how he and Infocepts define the term “data product.” We discuss a few real-world applications Infocepts has built, and the measurable impact of these data products—as well as some of the challenges they’ve faced that your team might as well. Skill sets also came up; who does design? Who takes ownership of the product/value side? And of course, we touch a bit on GenAI.
Highlights/ Skip to
Shashank gives his definition of data products (01:24) We tackle the challenges of user adoption in data products (04:29) We discuss the crucial role of integrating actionable insights into data products for enhanced decision-making (05:47) Shashank shares insights on the evolution of data products from concept to practical integration (10:35) We explore the challenges and strategies in designing user-centric data products (12:30) I ask Shashank about typical environments and challenges when starting new data product consultations (15:57) Shashank explains how Infocepts incorporates AI into their data solutions (18:55) We discuss the importance of understanding user personas and engaging with actual users (25:06) Shashank describes the roles involved in data product development’s ideation and brainstorming stages (32:20) The issue of proxy users not truly representing end-users in data product design is examined (35:47) We consider how organizations are adopting a product-oriented approach to their data strategies (39:48) Shashank and I delve into the implications of GenAI and other AI technologies on product orientation and user adoption (43:47) Closing thoughts (51:00)
Quotes from Today’s Episode
“Data products, at least to us at Infocepts, refers to a way of thinking about and organizing your data in a way so that it drives consumption, and most importantly, actions.” - Shashank Garg (1:44) “The way I see it is [that] the role of a DPM (data product manager)—whether they have the title or not—is benefits creation. You need to be responsible for benefits, not for outputs. The outputs have to create benefits or it doesn’t count. Game over” - Brian O’Neill (10:07) We talk about bridging the gap between the worlds of business and analytics... There's a huge gap between the perception of users and the tech leaders who are producing it." - Shashank Garg (17:37) “IT leaders often limit their roles to provisioning their secure data, and then they rely on businesses to be able to generate insights and take actions. Sometimes this handoff works, and sometimes it doesn’t because of quality governance.” - Shashank Garg (23:02) “Data is the kind of field where people can react very, very quickly to what’s wrong.” - Shashank Garg (29:44) “It’s much easier to get to a good prototype if we know what the inputs to a prototype are, which include data about the people who are going to use the solution, their usage scenarios, use cases, attitudes, beliefs…all these kinds of things.” - Brian O’Neill (31:49) “For data, you need a separate person, and then for designing, you need a separate person, and for analysis, you need a separate person—the more you can combine, I don’t think you can create super-humans who can do all three, four disciplines, but at least two disciplines and can appreciate the third one that makes it easier.” - Shashank Garg (39:20) “When we think of AI, we’re all talking about multiple different delivery methods here. I think AI is starting to become GenAI to a lot of non-data people. It’s like their—everything is GenAI.” - Brian O'Neill (43:48)
Links
Infocepts website: https://www.infocepts.ai/ Shashank Garg on LinkedIn: https://www.linkedin.com/in/shashankgarg/ Top 5 Data & AI initiatives for business success: https://www.infocepts.ai/downloads/top-5-data-and-ai-initiatives-to-drive-business-growth-in-2024-beyond/
Aren't You Tired of Repeating Yourself? Tired of repeating the same code over and over again in your React projects? In this talk, we'll discover the power of headless components, a design pattern that separates the logic from the presentation layer, allowing you to create reusable and flexible UI components. We'll explore how headless components can simplify your development process, saving you both time and effort. Whether you're a beginner or an experienced developer, join us to discover how headless components can help you streamline your React development and create high-quality, customizable UIs.
This session will be an introduction to using React as your frontend library. It covers the React component-based approach and how React enables dynamic, interactive user interfaces. Basic knowledge of HTML, CSS, and JavaScript is required. We will use https://codesandbox.io/s/react-new to play around with a React application.
David Martin Cohen, front-end developer at Leboncoin, apporte une expérience de six années avec React et met l'accent sur la transmission des concepts complexes à travers le code afin d'approfondir et partager ses connaissances au sein de la communauté tech.
Explore Mongodb Atlas — MongoDB’s developer data platform, and learn how to integrate it with various Google Cloud services. During this lab lounge, you will create a fully managed database deployment, set up serverless Triggers that react to database events, and build Atlas Functions to communicate with Google Cloud APIs.
Additionally, you will explore Google Cloud’s NLP APIs, perform sentiment analysis on incoming data, learn how to replicate operational datasets from MongoDB Atlas to BigQuery and build an ML model for classification.
Click the blue “Learn more” button above to tap into special offers designed to help you implement what you are learning at Google Cloud Next 25.

Whether you’ve been in the developer kitchen for decades or are just taking the plunge to do it yourself, The Complete Developer will show you how to build and implement every component of a modern stack—from scratch. You’ll go from a React-driven frontend to a fully fleshed-out backend with Mongoose, MongoDB, and a complete set of REST and GraphQL APIs, and back again through the whole Next.js stack. The book’s easy-to-follow, step-by-step recipes will teach you how to build a web server with Express.js, create custom API routes, deploy applications via self-contained microservices, and add a reactive, component-based UI. You’ll leverage command line tools and full-stack frameworks to build an application whose no-effort user management rides on GitHub logins. You’ll also learn how to: Work with modern JavaScript syntax, TypeScript, and the Next.js framework Simplify UI development with the React library Extend your application with REST and GraphQL APIs Manage your data with the MongoDB NoSQL database Use OAuth to simplify user management, authentication, and authorization Automate testing with Jest, test-driven development, stubs, mocks, and fakes Whether you’re an experienced software engineer or new to DIY web development, The Complete Developer will teach you to succeed with the modern full stack. After all, control matters. Covers: Docker, Express.js, JavaScript, Jest, MongoDB, Mongoose, Next.js, Node.js, OAuth, React, REST and GraphQL APIs, and TypeScript
by
Reem Mahmoud
We talked about:
Reem’s background Context-aware sensing and transfer learning Shifting focus from PhD to industry Reem’s experience with startups and dealing with prejudices towards PhDs AI interviewing solution How candidates react to getting interviewed by an AI avatar End-to-end overview of a machine learning project The pitfalls of using LLMs in your process Mitigating biases Addressing specific requirements for specific roles Reem’s resource recommendations
Links:
LinkedIn: https://www.linkedin.com/in/reemmahmoud/recent-activity/all/ Website: https://topmate.io/reem_mahmoud
Free Data Engineering course: https://github.com/DataTalksClub/data-engineering-zoomcamp Join DataTalks.Club: https://datatalks.club/slack.html Our events: https://datatalks.club/events.html
This session will be an introduction to using React as your frontend library. Basic knowledge of HTML, CSS, and JavaScript is required for you to understand what is going on.
The tracking landscape has changed a lot over the last years and will be facing new challenges with the deprecation of third party cookies also in Google Chrome. This presentation will set the scene from a legal and business perspective. Solutions will be shown how to react and act and what impact this will have on tracking.
This week I’m covering Part 1 of the 15 Ways to Increase User Adoption of Data Products, which is based on an article I wrote for subscribers of my mailing list. Throughout this episode, I describe why focusing on empathy, outcomes, and user experience leads to not only better data products, but also better business outcomes. The focus of this episode is to show you that it’s completely possible to take a human-centered approach to data product development without mandating behavioral changes, and to show how this approach benefits not just end users, but also the businesses and employees creating these data products.
Highlights/ Skip to:
Design behavior change into the data product. (05:34) Establish a weekly habit of exposing technical and non-technical members of the data team directly to end users of solutions - no gatekeepers allowed. (08:12) Change funding models to fund problems, not specific solutions, so that your data product teams are invested in solving real problems. (13:30) Hold teams accountable for writing down and agreeing to the intended benefits and outcomes for both users and business stakeholders. Reject projects that have vague outcomes defined. (16:49) Approach the creation of data products as “user experiences” instead of a “thing” that is being built that has different quality attributes. (20:16) If the team is tasked with being “innovative,” leaders need to understand the innoficiency problem, shortened iterations, and the importance of generating a volume of ideas (bad and good) before committing to a final direction. (23:08) Co-design solutions with [not for!] end users in low, throw-away fidelity, refining success criteria for usability and utility as the solution evolves. Embrace the idea that research/design/build/test is not a linear process. (28:13) Test (validate) solutions with users early, before committing to releasing them, but with a pre-commitment to react to the insights you get back from the test. (31:50)
Links:
15 Ways to Increase Adoption of Data Products: https://designingforanalytics.com/resources/15-ways-to-increase-adoption-of-data-products-using-techniques-from-ux-design-product-management-and-beyond/ Company website: https://designingforanalytics.com Episode 54: https://designingforanalytics.com/resources/episodes/054-jared-spool-on-designing-innovative-ml-ai-and-analytics-user-experiences/ Episode 106: https://designingforanalytics.com/resources/episodes/106-ideaflow-applying-the-practice-of-design-and-innovation-to-internal-data-products-w-jeremy-utley/ Ideaflow: https://www.amazon.com/Ideaflow-Only-Business-Metric-Matters/dp/0593420586/ Podcast website: https://designingforanalytics.com/podcast

Companies today are moving rapidly to integrate generative AI into their products and services. But there's a great deal of hype (and misunderstanding) about the impact and promise of this technology. With this book, Chris Fregly, Antje Barth, and Shelbee Eigenbrode from AWS help CTOs, ML practitioners, application developers, business analysts, data engineers, and data scientists find practical ways to use this exciting new technology. You'll learn the generative AI project life cycle including use case definition, model selection, model fine-tuning, retrieval-augmented generation, reinforcement learning from human feedback, and model quantization, optimization, and deployment. And you'll explore different types of models including large language models (LLMs) and multimodal models such as Stable Diffusion for generating images and Flamingo/IDEFICS for answering questions about images. Apply generative AI to your business use cases Determine which generative AI models are best suited to your task Perform prompt engineering and in-context learning Fine-tune generative AI models on your datasets with low-rank adaptation (LoRA) Align generative AI models to human values with reinforcement learning from human feedback (RLHF) Augment your model with retrieval-augmented generation (RAG) Explore libraries such as LangChain and ReAct to develop agents and actions Build generative AI applications with Amazon Bedrock
Send us a text Microsoft announces Python for ExcelAnnouncing Python in Excel: Combining the power of Python and the flexibility of Excel.https://techcommunity.microsoft.com/t5/excel-blog/announcing-python-in-excel-combining-the-power-of-python-and-the/ba-p/3893439AI-powered Coca ColaCoca‑Cola® Creations Imagines Year 3000 With New Futuristic Flavor and AI-Powered Experiencehttps://www.coca-colacompany.com/media-center/coca-cola-creations-imagines-year-3000-futuristic-flavor-ai-powered-experience40% productivity boost from AI, according to HarvardEnterprise workers gain 40 percent performance boost from GPT-4, Harvard study findshttps://venturebeat.com/ai/enterprise-workers-gain-40-percent-performance-boost-from[…]ewsletter&utm_campaign=ibm-pledges-to-train-two-million-in-aiMicrosoft’s Copilot announcementAnnouncing Microsoft Copilot, your everyday AI companionhttps://blogs.microsoft.com/blog/2023/09/21/announcing-microsoft-copilot-your-everyday-ai-companion/v0 - AI-powered react componentsWhat is v0?https://v0.dev/faq#what-is-v0Microsoft looking for a nuclear energy expertMicrosoft is hiring a nuclear energy expert to help power its AI and cloud data centershttps://www.cnbc.com/2023/09/25/microsoft-is-hiring-a-nuclear-energy-expert-to-help-power-data-centers.htmlIntro music courtesy of fesliyanstudios.com

Using Databricks, we built a “Unified Talent Solution” backed by a robust data and AI engine for analyzing skills of a combined pool of permanent employees, contractors, part-time employees and vendors, inferring skill gaps, future trends and recommended priority areas to bridge talent gaps, which ultimately greatly improved operational efficiency, transparency, commercial model, and talent experience of our client. We leveraged a variety of ML algorithms such as boosting, neural networks and NLP transformers to provide better AI-driven insights.
One inevitable part of developing these models within a typical DS workflow is iteration. Databricks' end-to-end ML/DS workflow service, MLflow, helped streamline this process by organizing them into experiments that tracked the data used for training/testing, model artifacts, lineage and the corresponding results/metrics. For checking the health of our models using drift detection, bias and explainability techniques, MLflow's deploying, and monitoring services were leveraged extensively.
Our solution built on Databricks platform, simplified ML by defining a data-centric workflow that unified best practices from DevOps, DataOps, and ModelOps. Databricks Feature Store allowed us to productionize our models and features jointly. Insights were done with visually appealing charts and graphs using PowerBI, plotly, matplotlib, that answer business questions most relevant to clients. We built our own advanced custom analytics platform on top of delta lake as Delta’s ACID guarantees allows us to build a real-time reporting app that displays consistent and reliable data - React (for front-end), Structured Streaming for ingesting data from Delta table with live query analytics on real time data ML predictions based on analytics data.
Talk by: Nitu Nivedita
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc
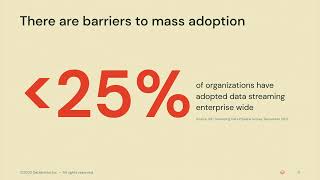
Streaming is the future of all data pipelines and applications. It enables businesses to make data-driven decisions sooner and react faster, develop data-driven applications considered previously impossible, and deliver new and differentiated experiences to customers. However, many organizations have not realized the promise of streaming to its full potential because it requires them to completely redevelop their data pipelines and applications on new, complex, proprietary, and disjointed technology stacks.
The Databricks Lakehouse Platform is a simple, unified, and open platform that supports all streaming workloads ranging from ingestion, ETL to event processing, event-driven application, and ML inference. In this session, we will discuss the streaming capabilities of the Databricks Lakehouse Platform and demonstrate how easy it is to build end-to-end, scalable streaming pipelines and applications, to fulfill the promise of streaming for your business.
Talk by: Zoe Durand and Yue Zhang
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc
Aaron Pavlick on unifying content and developer workflows by using Yext Content and Pages to build a performant, statically-generated website. He covers authoring content in Yext and delivering a great UX using the Pages framework and serving system.
Robert Balicki discusses how React renders components with a focus on Suspense, exploring why data fetching during render is challenging and why, to the presenter's knowledge, no library besides Relay supports this — with a demonstration using @boulton/react-disposable-state to implement suspense-compatible data fetching.
Local Planning Authorities (LPAs) in the UK rely on written representations from the community to inform their Local Plans which outline development needs for their area. With an average of 2000 representations per consultation and 4 rounds of consultation per Local Plan, the volume of information can be overwhelming for both LPAs and the Planning Inspectorate tasked with examining the legality and soundness of plans. In this study, we investigate the potential for Large Language Models (LLMs) to streamline representation analysis.
We find that LLMs have the potential to significantly reduce the time and effort required to analyse representations, with simulations on historical Local Plans projecting a reduction in processing time by over 30%, and experiments showing classification accuracy of up to 90%.
In this presentation, we discuss our experimental process which used a distributed experimentation environment with Jupyter Lab and cloud resources to evaluate the performance of the BERT, RoBERTa, DistilBERT, and XLNet models. We also discuss the design and prototyping of web applications to support the aided processing of representations using Voilà, FastAPI, and React. Finally, we highlight successes and challenges encountered and suggest areas for future improvement.