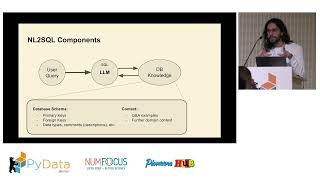
Go deep into how AgentCore works under the hood. This technical deep-dive session breaks down the ReAct loop—how agents iteratively reason, plan, and perform tool calls to accomplish complex goals. Learn how context management, memory, and data grounding shape each reasoning step and response. Explore how AgentCore operationalizes this loop with modular services: Runtime for scalable execution, Gateway for dynamic tool and data access, Policy for deterministic controls, Observability for monitoring agent behavior, and Evaluations for continuous quality improvements. Understand how AgentCore’s architecture enables reliable, secure, and production-ready deployment of autonomous, data-driven AI agents.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.