Retour d'expérience sur les deux jours de la conférence Scala.IO à Nantes et les nouvelles de la communauté Scala.
 talk-data.com
talk-data.com
Topic
Scala
programming_language
functional_programming
jvm
110
tagged
Activity Trend
12
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Engineering Books
34
Data Engineering Podcast
33
Databricks DATA + AI Summit 2023
11
ADSP: Algorithms + Data Structures = Programs
3
Scala Talks: Hands-On Capture Checking & Scala Native live-coding ☀️
2
Scala Talks: A deep dive into streaming with fs2 & Scala Meets GenAI
2
Data + AI Summit 2025
2
Scala Talks: Tour of error handling & Functional Programming at Huge Companies
2
Women in Scala: From Paradigms to Percussion & Hands On with Creative Scala
2
Meetup Paris Scala User Group (PSUG) – Hébergé par DataDome!
2
Scala Talks: Write a book about Scala during Covid & AI tooling for developers
2
DataDome x PSUG #116 : My First Year in Scala! + TBA
2

Data Engineering with Scala and Spark guides you through building robust data pipelines that process massive datasets efficiently. You will learn practical techniques leveraging Scala and Spark with a hands-on approach to mastering data engineering tasks including ingestion, transformation, and orchestration. What this Book will help me do Set up a data pipeline development environment using Scala Utilize Spark APIs like DataFrame and Dataset for effective data processing Implement CI/CD and testing strategies for pipeline maintainability Optimize pipeline performance through tuning techniques Apply data profiling and quality enforcement using tools like Deequ Author(s) Eric Tome, Rupam Bhattacharjee, and David Radford bring decades of combined experience in data engineering and distributed systems. Their work spans cutting-edge data processing solutions using Scala and Spark. They aim to help professionals excel in building reliable, scalable pipelines. Who is it for? This book is tailored for working data engineers familiar with data workflow processes who desire to enhance their expertise in Scala and Spark. If you aspire to build scalable, high-performance data solutions or transition raw data into strategic assets, this book is ideal.
Build tools for Scala help you to compile projects as fast as possible. How does this work so we aren’t waiting all day for a one-line-change to rebuild? You will learn about the process of incremental compilation; the steps that you can take to optimise build times; and other developments in the Scala ecosystem to improve build times, from pipelined compilation to even batched parallel compilation.
Navigating the world of Scala and functional programming as a beginner can feel daunting and intimidating. A year ago, I was thrown into the deep end of Scala. Having come out on the other side, I want to share my experience to show newcomers that they’re not alone and can do this too! I started my Scala journey in a junior developer role at a corporate bank after graduating with a degree in Physics. So, not only did I have the challenge of learning Scala from scratch, but I also had to apply these concepts to a domain I had no prior knowledge of. Initially, I experienced a lot of confusion and frustration, such as when my implicit encoder did not behave as I expected. However, my experienced Scala colleagues were always there to help me and quickly ease my frustrations. As a result, I want to help others avoid these pitfalls that led to a lot of wasted time for me in the beginning. During this talk, we will cover the main Scala concepts that I have learned in the past year: what are Algebraic Data Types and how can I use them? Implicits and the issues I faced, and finally, starting out with SBT. I also want to discuss the different ways of learning Scala that I have experienced. Hopefully, after listening to me, other newcomers will feel less alone and more optimistic about diving into the exciting world of Scala!

Instacart has gone through immense growth during the pandemic and the trend continues. Instacart ads is no exception in this growth story. We have launched many new product lines including display and video ads covering the full advertising funnel to address the increasing demand of our retail partners. We have built advanced models to auto-suggest optimal bidding to increase the ROI for our CPG partners. Advertisers’ trust is the utmost priority and thus the quest to build a top-class ads measurement platform.
Ads data processing requires complex data verifications to update ads serving stats. In ETL pipelines these were implemented through files containing thousands of lines of raw SQL which were hard to scale, test, and iterate upon. Our data engineers used to spend hours testing small changes due to a lack of local testing mechanisms. These pain points stress our need for better tools. After some research, we chose Apache Spark™ as our preferred tool to rebuild ETLs, and the Databricks platform made this move easier. In this session, We'll share our journey to move our pipelines to Spark and Delta Lake on Databricks. With Spark, Scala, and Delta we solved many problems which were slowing the team’s productivity. Some key areas that will be covered include:
- Modular and composable code
- Unit testing framework
- Incremental event processing with spark structured streaming
- Granular resource tuning for better performance and cost efficacy
Other than the domain business logic, the problems discussed here are quite common for performing data processing at scale. We hope that sharing our learnings will benefit others who are going through similar growth challenges or migrating to Lakehouse.
Talk by: Devlina Das and Arthur Li
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc
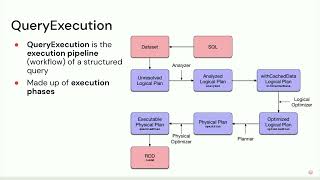
A client recently asked to optimize their batch and streaming workloads. It happened to be aggregations using DataFrame.groupby operation with a custom Scala UDAF over a data stream from Kafka. Just a single simple-looking request that turned itself up into a a-few-month-long hunt to find a more performant query execution planning than ObjectHashAggregateExec that kept falling back to a sort-based aggregation (i.e., the worst possible aggregation runtime performance). It quickly taught us that an aggregation using a custom Scala UDAF cannot be planned other than ObjectHashAggregateExec but at least tasks don't always have to fall back. And that's just batch workloads. When you throw in streaming semantics and think of the different output modes, windowing and streaming watermark optimizing aggregation can take a long time to do right.
Talk by: Jacek Laskowski
Here’s more to explore: Big Book of Data Engineering: 2nd Edition: https://dbricks.co/3XpPgNV The Data Team's Guide to the Databricks Lakehouse Platform: https://dbricks.co/46nuDpI
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc

Unity Catalog provides fully automated data lineage for all workloads in SQL, R, Python, Scala and across all asset types at Databricks. The aggregated view has been available to end users through data explorer and API. In this session, we are excited to share that lineage is available via delta table in their UC metastore. It stores full history of recent lineage records and it is near real time. Additionally, customers can query it through standard SQL interface. With that, customers can get significant operational insights about their workload for impact analysis, troubleshooting, quality assurance, data discovery, and data governance.
Together with the system table platform effort, which provides query history, job run operational data, audit logs and more, lineage table will be a critical piece to link all the data asset and entity asset together, providing better lakehouse observability and unification to customers.
Talk by: Menglei Sun
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc

Let’s face it -- data is messy. And your company’s business requirements? Even messier. You’re staring at your screen, knowing there is a tool that will let you give your business partners the information they need as quickly as they need it. There’s even a Python version of it now. But…it looks kind of scary. You’ve never used it before, and you don’t know where to start. Yes, we’re talking about the dreaded flatMapGroupsWithState. But fear not - we’ve got you covered.
In this session, we’ll take a real-word use case and use it to show you how to break down flatMapGroupsWithState into its basic building blocks. We’ll explain each piece in both Scala and the newly-released Python, and at the end we’ll illustrate how it all comes together to enable the implementation of arbitrary stateful operations with Spark Structured Streaming.
Talk by: Angela Chu
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc
In this talk, we will explore the use of Python's typing.Protocol, Scala's Typeclasses, and Rust's Traits.
They all offer a very powerful & elegant mechanism for abstracting over various concepts (such as Serialization) in a modular manner.
We will compare and contrast the syntax and implementation of these constructs in each language and discuss their strengths and weaknesses. We will also look at real-world examples of how these features are used in each language to specify behavior, and consider differences in terms of type system expressiveness and effectiveness. By the end of the talk, attendees will have a better understanding of the differences and similarities between these three language features, and will be able to make informed decisions about which one is best suited for their needs.
Summary The problems that are easiest to fix are the ones that you prevent from happening in the first place. Sifflet is a platform that brings your entire data stack into focus to improve the reliability of your data assets and empower collaboration across your teams. In this episode CEO and founder Salma Bakouk shares her views on the causes and impacts of "data entropy" and how you can tame it before it leads to failures.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. By the time errors have made their way into production, it’s often too late and damage is done. Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. No more shipping and praying, you can now know exactly what will change in your database! Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Salma Bakouk about achieving data reliability and reducing entropy within your data stack with sifflet
Interview
Introduction How did you get involved in the area of data management? Can you describe what Sifflet is and the st
Summary CreditKarma builds data products that help consumers take advantage of their credit and financial capabilities. To make that possible they need a reliable data platform that empowers all of the organization’s stakeholders. In this episode Vishnu Venkataraman shares the journey that he and his team have taken to build and evolve their systems and improve the product offerings that they are able to support.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. By the time errors have made their way into production, it’s often too late and damage is done. Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. No more shipping and praying, you can now know exactly what will change in your database! Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Vishnu Venkataraman about building the data platform at CreditKarma and the forces that shaped the design
Interview
Introduction How did you get involved in the area of data management? Can you describe what CreditKarma is and the role
Summary Despite the best efforts of data engineers, data is as messy as the real world. Entity resolution and fuzzy matching are powerful utilities for cleaning up data from disconnected sources, but it has typically required custom development and training machine learning models. Sonal Goyal created and open-sourced Zingg as a generalized tool for data mastering and entity resolution to reduce the effort involved in adopting those practices. In this episode she shares the story behind the project, the details of how it is implemented, and how you can use it for your own data projects.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. By the time errors have made their way into production, it’s often too late and damage is done. Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. No more shipping and praying, you can now know exactly what will change in your database! Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Sonal Goyal about Zingg, an open source entity resolution frame
Summary One of the most impactful technologies for data analytics in recent years has been dbt. It’s hard to have a conversation about data engineering or analysis without mentioning it. Despite its widespread adoption there are still rough edges in its workflow that cause friction for data analysts. To help simplify the adoption and management of dbt projects Nandam Karthik helped create Optimus. In this episode he shares his experiences working with organizations to adopt analytics engineering patterns and the ways that Optimus and dbt were combined to let data analysts deliver insights without the roadblocks of complex pipeline management.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. By the time errors have made their way into production, it’s often too late and damage is done. Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. No more shipping and praying, you can now know exactly what will change in your database! Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Nand
Summary The database market has seen unprecedented activity in recent years, with new options addressing a variety of needs being introduced on a nearly constant basis. Despite that, there are a handful of databases that continue to be adopted due to their proven reliability and robust features. MariaDB is one of those default options that has continued to grow and innovate while offering a familiar and stable experience. In this episode field CTO Manjot Singh shares his experiences as an early user of MySQL and MariaDB and explains how the suite of products being built on top of the open source foundation address the growing needs for advanced storage and analytical capabilities.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced features with a 14-day free trial. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when
Summary The "data lakehouse" architecture balances the scalability and flexibility of data lakes with the ease of use and transaction support of data warehouses. Dremio is one of the companies leading the development of products and services that support the open lakehouse. In this episode Jason Hughes explains what it means for a lakehouse to be "open" and describes the different components that the Dremio team build and contribute to.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced features with a 14-day free trial. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Jason Hughes about the work that Dremio is doing to support the open lakehouse
Interview
Introduction How did you get involved in the area of data management? Can you d
Summary For any business that wants to stay in operation, the most important thing they can do is understand their customers. American Express has invested substantial time and effort in their Customer 360 product to achieve that understanding. In this episode Purvi Shah, the VP of Enterprise Big Data Platforms at American Express, explains how they have invested in the cloud to power this visibility and the complex suite of integrations they have built and maintained across legacy and modern systems to make it possible.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced features with a 14-day free trial. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Purvi Shah about building the Customer 360 data product for American Express and mig
Summary Data lineage is something that has grown from a convenient feature to a critical need as data systems have grown in scale, complexity, and centrality to business. Alvin is a platform that aims to provide a low effort solution for data lineage capabilities focused on simplifying the work of data engineers. In this episode co-founder Martin Sahlen explains the impact that easy access to lineage information can have on the work of data engineers and analysts, and how he and his team have designed their platform to offer that information to engineers and stakeholders in the places that they interact with data.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced features with a 14-day free trial. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Martin Sahlen about his work on data lineage at Alvin and how it factors into the day-to-day work of data engineers
Interview
Introduction How did you get involved in the area of data management? Can you describe what Alvin is and the story behind it? What is the core problem that you are trying to solve at Alvin? Data lineage has quickly become an overloaded term. What are the elements of lineage that you are focused on addressing?
What are some of the other sources/pieces of information that you integrate into the lineage graph?
How does data lineage show up in the work of data engineers?
In what ways does your focus on data engineers inform the way that you model the lineage information?
As with every data asset/product, the lineage graph is only as useful as the data that it stores. What are some of the ways that you focus on establishing and ensuring a complete view of lineage?
How do you account for assets (e.g. tables, dashboards, exports, etc.) that are created outside of the "officially supported" methods? (e.g. someone manually runs a SQL create statement, etc.)
Can you describe how you have implemented the Alvin platform?
How have the design and goals shifted from when you first started exploring the problem?
What are the types of data systems/assets that you are focused on supporting? (e.g. data warehouses vs. lakes, structured vs. unstructured, which BI tools, etc.) How does Alvin fit into the workflow of data engineers and their downstream customers/collaborators?
What are some of the design choices (both visual and functional) that you focused on to avoid friction in the data engineer’s workflow?
What are some of the open questions/areas for investigation/improvement in the space of data lineage?
What are the factors that contribute to the difficulty of a truly holistic and complete view of lineage across an organization?
What are the most interesting, innovative, or unexpected ways that you have seen Alvin used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Alvin? When is Alvin the wrong choice? What do you have planned for the future of Alvin?
Contact Info
LinkedIn @martinsahlen on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don’t forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you’ve learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Alvin Unacast sqlparse Python library Cython
Podcast.init Episode
Antlr Kotlin programming language PostgreSQL
Podcast Episode
OpenSearch ElasticSearch Redis Kubernetes Airflow BigQuery Spark Looker Mode
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Support Data Engineering Podcast
Summary Data integration from source systems to their downstream destinations is the foundational step for any data product. With the increasing expecation for information to be instantly accessible, it drives the need for reliable change data capture. The team at Fivetran have recently introduced that functionality to power real-time data products. In this episode Mark Van de Wiel explains how they integrated CDC functionality into their existing product, discusses the nuances of different approaches to change data capture from various sources.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced features with a 14-day free trial. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. Your host is Tobias Macey and today I’m interviewing Mark Van de Wiel about Fivetran’s implementation of chang
Summary In order to improve efficiency in any business you must first know what is contributing to wasted effort or missed opportunities. When your business operates across multiple locations it becomes even more challenging and important to gain insights into how work is being done. In this episode Tommy Yionoulis shares his experiences working in the service and hospitality industries and how that led him to found OpsAnalitica, a platform for collecting and analyzing metrics on multi location businesses and their operational practices. He discusses the challenges of making data collection purposeful and efficient without distracting employees from their primary duties and how business owners can use the provided analytics to support their staff in their duties.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to dataengineeringpodcast.com/ascend and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $5,000 when you become a customer. You wake up to a Slack message from your CEO, who’s upset because the company’s revenue dashboard is broken. You’re told to fix it before this morning’s board meeting, which is just minutes away. Enter Metaplane, the industry’s only self-serve data observability tool. In just a few clicks, you identify the issue’s root cause, conduct an impact analysis—and save the day. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. You can literally get up and running with Metaplane by the end of this podcast. Sign up for a free-forever plan at dataengineeringpodcast.com/metaplane, or try out their most advanced
Summary The global climate impacts everyone, and the rate of change introduces many questions that businesses need to consider. Getting answers to those questions is challenging, because the climate is a multidimensional and constantly evolving system. Sust Global was created to provide curated data sets for organizations to be able to analyze climate information in the context of their business needs. In this episode Gopal Erinjippurath discusses the data engineering challenges of building and serving those data sets, and how they are distilling complex climate information into consumable facts so you don’t have to be an expert to understand it.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Data stacks are becoming more and more complex. This brings infinite possibilities for data pipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Sifflet solves this problem by acting as an overseeing layer to the data stack – observing data and ensuring it’s reliable from ingestion all the way to consumption. Whether the data is in transit or at rest, Sifflet can detect data quality anomalies, assess business impact, identify the root cause, and alert data teams’ on their preferred channels. All thanks to 50+ quality checks, extensive column-level lineage, and 20+ connectors across the Data Stack. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses. Listeners of the podcast will get $2000 to use as platform credits when signing up to use Sifflet. Sifflet also offers a 2-week free trial. Find out more at dataengineeringpodcast.com/sifflet today! The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it. Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest. Go to dataengineeringpodcast.com/selectstar today to double the length of your free trial and get a swag package when you convert to a paid plan. Data teams are increasingly under pressure to deliver. According to a recent survey by Ascend.io, 95% in fact reported being at or over capacity. With 72% of data experts reporting demands on their team going up faster than they can hire, it’s no surprise they are increasingly turning to automation. In fact, while only 3.5% report having current investments in automation, 85% of data teams plan on investing in automation in the next 12 months. 85%!!! That’s where our friends at Ascend.io come in. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend automates workloads on Snowflake, Databricks, BigQuery, and open source Spark, and can be deployed in AWS, Azure, or GCP. Go to datae