To learn more, visit the Databricks Security and Trust Center: https://www.databricks.com/trust
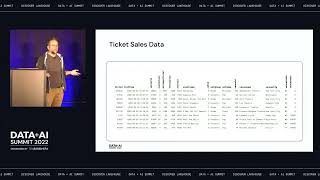
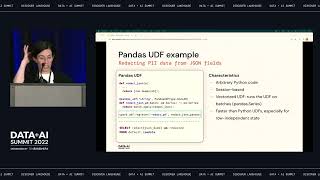
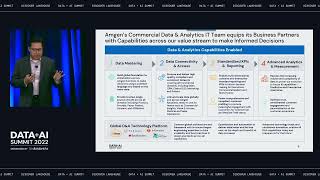
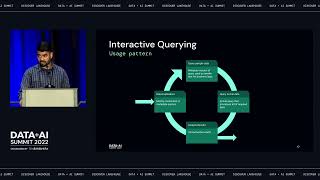
In this session, we will talk about the best practices for setting up Databricks to run at large enterprise scale with thousands of users, departmental security and governance, and end-to-end lineage from ingestion to BI tools. We’ll showcase the power of Unity Catalog and Databricks SQL as the core of your modern data stack and how to achieve both data, environment, and financial governance while empowering your users to quickly find and access the data they need.
Talk by: Siddharth Bhai, Paul Roome, Jeremy Lewallen, and Samrat Ray
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksin