Join this session to learn about the Labcorp data platform transformation from on-premises Hadoop to AWS Databricks Lakehouse. We will share best practices and lessons learned from cloud-native data platform selection, implementation, and migration from Hadoop (within six months) with Unity Catalog.
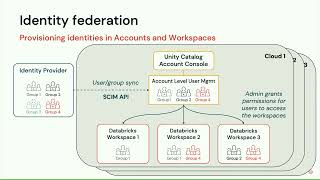
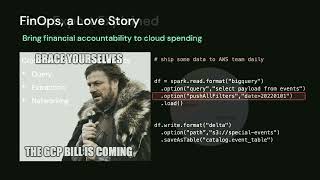
We will share steps taken to retire several legacy on-premises technologies and leverage Databricks native features like Spark streaming, workflows, job pools, cluster policies and Spark JDBC within Databricks platform. Lessons learned in Implementing Unity Catalog and building a security and governance model that scales across applications. We will show demos that walk you through batch frameworks, streaming frameworks, data compare tools used across several applications to improve data quality and speed of delivery.
Discover how we have improved operational efficiency, resiliency and reduced TCO, and how we scaled building workspaces and associated cloud infrastructure using Terraform provider.
Talk by: Mohan Kolli and Sreekanth Ratakonda
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc