Amgen’s Journey To Building a Global 360 View of its Customers with the Lakehouse
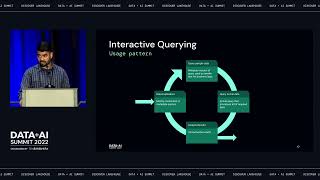
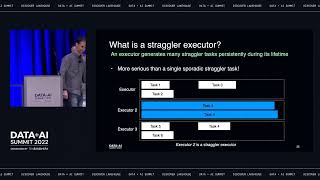
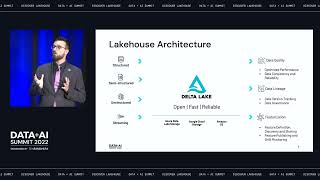
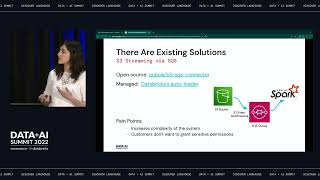
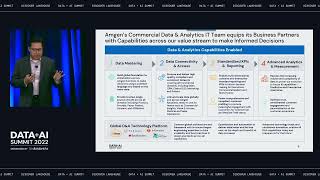
Serving patients in over 100 countries, Amgen is a leading global biotech company focused on developing therapies that have the power to save lives. Delivering on this mission requires our commercial teams to regularly meet with healthcare providers to discuss new treatments that can help patients in need. With the onset of the pandemic, where face-to-face interactions with doctors and other Healthcare Providers (HCPs) were severely impacted, Amgen had to rethink these interactions. With that in mind, the Amgen Commercial Data and Analytics team leveraged a modern data and AI architecture built on the Databricks Lakehouse to help accelerate its digital and data insights capabilities. This foundation enabled Amgen’s teams to develop a comprehensive, customer-centric view to support flexible go-to-market models and provide personalized experiences to our customers. In this presentation, we will share our recent journey of how we took an agile approach to bringing together over 2.2 petabytes of internally generated and externally sourced vendor data , and onboard into our AWS Cloud and Databricks environments to enable a standardized, scalable and robust capabilities to meet the business requirements in our fast-changing life sciences environment. We will share use cases of how we harmonized and managed our diverse sets of data to deliver efficiency, simplification, and performance outcomes for the business. We will cover the following aspects of our journey along with best practices we learned over time: • Our architecture to support Amgen’s Commercial Data & Analytics constant processing around the globe • Engineering best practices for building large scale Data Lakes and Analytics platforms such as Team organization, Data Ingestion and Data Quality Frameworks, DevOps Toolkit and Maturity Frameworks, and more • Databricks capabilities adopted such as Delta Lake, Workspace policies, SQL workspace endpoints, and MLflow for model registry and deployment. Also, various tools were built for Databricks workspace administration • Databricks capabilities being explored for future, such as Multi-task Orchestration, Container-based Apache Spark Processing, Feature Store, Repos for Git integration, etc. • The types of commercial analytics use cases we are building on the Databricks Lakehouse platform Attendees building global and Enterprise scale data engineering solutions to meet diverse sets of business requirements will benefit from learning about our journey. Technologists will learn how we addressed specific Business problems via reusable capabilities built to maximize value.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/