Summary The rapid growth of generative AI applications has prompted a surge of investment in vector databases. While there are numerous engines available now, Lance is designed to integrate with data lake and lakehouse architectures. In this episode Weston Pace explains the inner workings of the Lance format for table definitions and file storage, and the optimizations that they have made to allow for fast random access and efficient schema evolution. In addition to integrating well with data lakes, Lance is also a first-class participant in the Arrow ecosystem, making it easy to use with your existing ML and AI toolchains. This is a fascinating conversation about a technology that is focused on expanding the range of options for working with vector data. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementImagine catching data issues before they snowball into bigger problems. That’s what Datafold’s new Monitors do. With automatic monitoring for cross-database data diffs, schema changes, key metrics, and custom data tests, you can catch discrepancies and anomalies in real time, right at the source. Whether it’s maintaining data integrity or preventing costly mistakes, Datafold Monitors give you the visibility and control you need to keep your entire data stack running smoothly. Want to stop issues before they hit production? Learn more at dataengineeringpodcast.com/datafold today!Your host is Tobias Macey and today I'm interviewing Weston Pace about the Lance file and table format for column-oriented vector storageInterview IntroductionHow did you get involved in the area of data management?Can you describe what Lance is and the story behind it?What are the core problems that Lance is designed to solve?What is explicitly out of scope?The README mentions that it is straightforward to convert to Lance from Parquet. What is the motivation for this compatibility/conversion support?What formats does Lance replace or obviate?In terms of data modeling Lance obviously adds a vector type, what are the features and constraints that engineers should be aware of when modeling their embeddings or arbitrary vectors?Are there any practical or hard limitations on vector dimensionality?When generating Lance files/datasets, what are some considerations to be aware of for balancing file/chunk sizes for I/O efficiency and random access in cloud storage?I noticed that the file specification has space for feature flags. How has that aided in enabling experimentation in new capabilities and optimizations?What are some of the engineering and design decisions that were most challenging and/or had the biggest impact on the performance and utility of Lance?The most obvious interface for reading and writing Lance files is through LanceDB. Can you describe the use cases that it focuses on and its notable features?What are the other main integrations for Lance?What are the opportunities or roadblocks in adding support for Lance and vector storage/indexes in e.g. Iceberg or Delta to enable its use in data lake environments?What are the most interesting, innovative, or unexpected ways that you have seen Lance used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on the Lance format?When is Lance the wrong choice?What do you have planned for the future of Lance?Contact Info LinkedInGitHubParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Links Lance FormatLanceDBSubstraitPyArrowFAISSPineconePodcast EpisodeParquetIcebergPodcast EpisodeDelta LakePodcast EpisodePyLanceHilbert CurvesSIFT VectorsS3 ExpressWekaDataFusionRay DataTorch Data LoaderHNSW == Hierarchical Navigable Small Worlds vector indexIVFPQ vector indexGeoJSONPolarsThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
 talk-data.com
talk-data.com
Topic
AI/ML
Artificial Intelligence/Machine Learning
9014
tagged
Activity Trend
Top Events
A number of recent developments serve to reduce downside growth risks globally. In part this reflects strong US demand indicators and substantial front-loaded China policy supports, which serve to materially raise our current quarter global growth forecast.
Speakers:
Bruce Kasman
Joseph Lupton
This podcast was recorded on October 18, 2024.
This communication is provided for information purposes only. Institutional clients please visit www.jpmm.com/research/disclosures for important disclosures. © 2024 JPMorgan Chase & Co. All rights reserved. This material or any portion hereof may not be reprinted, sold or redistributed without the written consent of J.P. Morgan. It is strictly prohibited to use or share without prior written consent from J.P. Morgan any research material received from J.P. Morgan or an authorized third-party (“J.P. Morgan Data”) in any third-party artificial intelligence (“AI”) systems or models when such J.P. Morgan Data is accessible by a third-party. It is permissible to use J.P. Morgan Data for internal business purposes only in an AI system or model that protects the confidentiality of J.P. Morgan Data so as to prevent any and all access to or use of such J.P. Morgan Data by any third-party.
What are the risks to your organization's data? What are some considerations when thinking about data security? How susceptible are companies to hacking and malware? Jonathan Bloch, CEO of Exchange Data, joins us on this podcast episode of Data Unchained to discuss these topics and everything data security. Tune in and enjoy! To find our more about Jonathan's company, Exchange Data, check out his website: https://www.exchange-data.com/ You contact Jonathan's team by reaching out via email at: [email protected]
cybersecurity #podcast #ai #edgecomputing #data #innovation #edgetocloud #datascience #crypto #datastorage #datacloudtechnology #global #hacking #hacker #hack #malware
Cyberpunk by jiglr | https://soundcloud.com/jiglrmusic Music promoted by https://www.free-stock-music.com Creative Commons Attribution 3.0 Unported License https://creativecommons.org/licenses/by/3.0/deed.en_US Hosted on Acast. See acast.com/privacy for more information.
coming soon.

Making use of AI in the dbt development lifecycle has the potential to be a massive productivity unlock for your team. In this talk, explore how AI-driven approaches can improve your development process with Michiel De Smet from Altimate AI and Anton Goncharuk from Hubspot. Discover practical strategies to automate your work, prevent issues earlier, and embed best practices. Along the way, you'll also get to hear some real-life examples from how the team at HubSpot streamlined their dbt Cloud development workflow and enhanced collaboration within the team.
Speakers: Michiel De Smet Founding Engineer Altimate AI
Anton Goncharuk Principal Analytics Engineer HubSpot
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Are you a dbt Cloud customer aiming to fast-track your company’s journey to GenAI and speed up data development? You can't deploy AI applications without trusting the data that feeds them. Rule-based data quality approaches are a dead end that leaves you in a never-ending maintenance cycle. Join us to learn how modern machine learning approaches to data quality overcome the limits of rules and checks, helping you escape the reactive doom loop and unlock high-quality data for your whole company.
Speakers: Amy Reams VP Business Development Anomalo
Jonathan Karon Partner Innovation Lead Anomalo
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Riot Games, creator of hit titles like League of Legends and Valorant, is building an ultimate gaming experience by using data and AI to deliver the most optimal player journeys. In this session, you'll learn how Riot's data platform team paired with analytics engineering, machine learning, and insights teams to integrate Databricks Data Intelligence Platform and dbt Cloud to significantly mature its data capabilities. The outcome: a scalable, collaborative analytics environment that serves millions of players worldwide.
You’ll hear how Riot Games: - Centralized petabytes of game telemetry on Databricks for fast processing and analytics - Modernized their data platform by integrating dbt Cloud, unlocking governance for modular, version-controlled data transformations and testing for a diverse set of user personas - Uses Generative AI to automate the enforcement of good documentation and quality code and plans to use Databricks AI to further speed up its ability to unlock the value of data - Deployed machine learning models for personalized recommendations and player behavior analysis
You'll come away with practical insights on architecting a modern data stack that can handle massive scale while empowering teams across the organization. Whether you're in gaming or any data-intensive industry, you'll learn valuable lessons from Riot's journey to build a world-class data platform.
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

AWS offers the most scalable, highest performing data services to keep up with the growing volume and velocity of data to help organizations to be data-driven in real-time. AWS helps customers unify diverse data sources by investing in a zero ETL future and enable end-to-end data governance so your teams are free to move faster with data. Data teams running dbt Cloud are able to deploy analytics code, following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. In this session, we will dive deeper into how to get near real-time insight on petabytes of transaction data using Amazon Aurora zero-ETL integration with Amazon Redshift and dbt Cloud for your Generative AI workloads.
Speakers: Neela Kulkarni Solutions Architect AWS
Neeraja Rentachintala Director, Product Management Amazon
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
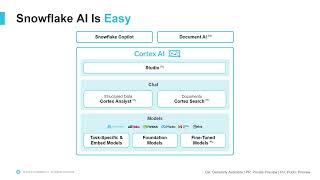
Ready to level up your data pipelines with AI and ML? In this session, we'll dive into key Snowflake AI and ML features and teach you how to easily integrate them into dbt pipelines. You'll explore real-world machine learning and generative AI use cases, and see how dbt and Snowflake together deliver powerful, secure results within Snowflake’s governance and security framework. Plus, discover how data scientists, engineers, and analysts can collaborate seamlessly using these tools. Whether you're scaling ML models or embedding AI into your existing workflows, this session will give you practical strategies for building secure, AI-powered data pipelines with dbt and Snowflake.
Speaker: Randy Pettus Senior Partner Sales Engineer Snowflake
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Espresso AI uses two main techniques to run dbt workloads substantially faster and cheaper on data warehouses: better job scheduling and automatically incrementalizing queries. This talk will dive into the technical details behind both approaches.
Speaker: Ben Lerner Co-founder and CEO Espresso AI
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Join us for an insightful session where we delve into the innovative ways the NBA is leveraging Generative AI (GenAI) to revolutionize data insights and transform the world of sports and entertainment analytics.
Speakers: Keelan Smithers Data Product Manager, Analytics Engineering NBA
Mark Hay CTO & Co-Founder TextQL
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
There's been a ton of hype surrounding AI for enterprise data, but is anyone actually using it in production? In this talk, we'll explore how Sigma is leveraging, dbt, AI, and Sigma to build propensity models and more—creating a flywheel feedback loop powered by Sigma.
Attendees will learn: - Practical, real-world applications of these tools in AI workflows. - Integration benefits of Snowflake, dbt, and Sigma. - Challenges faced and solutions implemented. - The transformative impact on business outcomes.
Join us to discover actionable takeaways for implementing AI-driven solutions in your organization.
Speaker: Jake Hannan Head of Data Sigma
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
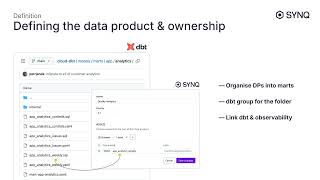
With analytics teams' growing ambition to build business automation, foundational AI systems, or customer-facing products, we must shift our mindset about data quality. Mechanically applied testing will not be enough; we need a more robust strategy akin to software engineering.
We outline a new approach to data testing and observability anchored in the ‘Data Products’ concept and walk through the practical implementation of a production-grade analytics system at SYNQ, powered by ClickHouse and dbt.
Speaker: Petr Janda Founder SYNQ
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

In this session, Gleb Mezhanskiy, CEO of Datafold, will share innovative strategies for automating the conversion of legacy transformation code (i.e., stored procedures) to dbt models, a crucial step in modernizing your data infrastructure. He will also delve into techniques for automating the data reconciliation between legacy and new systems with cross-database data diffing, ensuring data integrity and accelerating migration timelines. Additionally, Gleb will demonstrate how data teams can adopt a proactive approach to data quality post-migration by leveraging a "shift-left" approach to data testing and monitoring.
Speaker: Gleb Mezhanskiy Datafold
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Send us a text Welcome to the cozy corner of the tech world where ones and zeros mingle with casual chit-chat. Datatopics Unplugged is your go-to spot for relaxed discussions around tech, news, data, and society. Dive into conversations that flow as smoothly as your morning coffee, where industry insights meet laid-back banter. Whether you're a data aficionado or just someone curious about the digital age, pull up a chair, relax, and let's get into the heart of data, unplugged style! In today's episode: Remote work and hybrid challenges: Insights from the IMF on remote productivity, plus the challenges of work-life balance and Amazon’s office return with other companies' strategies for bringing employees back to the office.The fall of Zapata AI: A look at the shutdown of Zapata AI and the struggles in building successful quantum computing ventures.WTF Python: Exploring Python’s type hints, overloads, and those confusing "WTF" moments. Check out WTFPython.Data profiling tools: A dive into YData Profiling and Sweetviz for detailed data analysis.GifCities and personal websites: Reflecting on the fall of GifCities, the retro GIF hub, and discussing Murilo’s blog journey.Rust’s complexity debate: Discussing the blog post My Negative Views on Rust and whether Rust is too complex or simply misunderstood..io domain controversy: Examining the future of the .io domain as the British Indian Ocean Territory transfers sovereignty. Read more on Every.to and MIT Technology Review.Ducks or AI? A fun challenge to distinguish real ducks from AI-generated ones in the Duck Imposter Game.Adobe's AI video generator: A discussion on Adobe Firefly’s AI-powered video generator and its potential impact on content creation.
Building a robust data infrastructure is crucial for any organization looking to leverage AI and data-driven insights. But as your data ecosystem grows, so do the challenges of managing, securing, and scaling it. How do you ensure that your data infrastructure not only meets today’s needs but is also prepared for the rapid changes in technology tomorrow? What strategies can you adopt to keep your organization agile, while ensuring that your data investments continue to deliver value and support business goals? Saad Siddiqui is a venture capitalist for Titanium Ventures. Titanium focus on enterprise technology investments, particularly focusing on next generation enterprise infrastructure and applications. In his career, Saad has deployed over $100M in venture capital in over a dozen companies. In previous roles as a corporate development executive, he has executed M&A transactions valued at over $7 billion in aggregate. Prior to Titanium Ventures he was in corporate development at Informatica and was a member of Cisco's venture investing and acquisitions team covering cloud, big data and virtualization. In the episode, Richie and Saad explore the business impacts of data infrastructure, getting started with data infrastructure, the roles and teams you need to get started, scalability and future-proofing, implementation challenges, continuous education and flexibility, automation and modernization, trends in data infrastructure, and much more. Links Mentioned in the Show: Titanium VenturesConnect with SaadCourse - Artificial Intelligence (AI) StrategyRelated Episode: How are Businesses Really Using AI? With Tathagat Varma, Global TechOps Leader at Walmart Global TechRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
In this episode, host Jason Foster sits down with Cassandra Vukorep, Chief Data Officer at Lloyds of London. The discussion delves into the critical role of data literacy and how fostering a culture of data engagement can benefit a diverse range of organisations across various industries. They also explore Cassandra's current role at Lloyds and the exciting data opportunities that can be applied to the insurance industry. ***** Cynozure is a leading data, analytics and AI company that helps organisations to reach their data potential. It works with clients on data and AI strategy, data management, data architecture and engineering, analytics and AI, data culture and literacy, and data leadership. The company was named one of The Sunday Times' fastest-growing private companies in both 2022 and 2023, and recognised as The Best Place to Work in Data by DataIQ in 2023 and 2024.

For decades, siloed data modeling has been the norm: applications, analytics, and machine learning/AI. However, the emergence of AI, streaming data, and “shifting left" are changing data modeling, making siloed data approaches insufficient for the diverse world of data use cases. Today's practitioners must possess an end-to-end understanding of the myriad techniques for modeling data throughout the data lifecycle. This presentation covers "mixed model arts," which advocates converging various data modeling methods and the innovations of new ones.
Speaker: Joe Reis Author Nerd Herd
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

AI is changing software engineering, and it will change analytics too. Come for a glimpse of the day-to-day job of an analyst in the future, and some strategies for how to maximally benefit from AI.
Speaker: Bryan Bischof Head of AI Hex
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

In this talk, we will make the case that the success of enterprise AI depends on an investment in semantics and knowledge, not just data. Our LLM Accuracy benchmark research provided evidence that by layering semantic layers/knowledge graphs on enterprise SQL databases increases the accuracy of LLMs at least 4X for question answering. This work has been reproduced and validated by many others, including dbt labs. It's fantastic that semantics and knowledge are getting the attention it deserves. We need more.
This talk is targeted to 1) those who believe AI accuracy can be improved by simply adding more data to fine-tune/train models, and 2) the believers in semantics and knowledge who need help getting executive buy-in.
We will dive into: - the knowledge engineering work that needs to be done - who should be leading this work (hint: analytics engineers) - what companies lose by not doing this knowledge engineering work
Speaker: Juan Sequeda Principal Scientist and Head of AI Lab data.world
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements