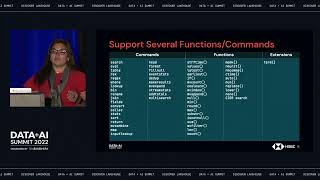
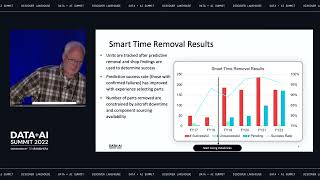
Hear from three guests. Harrison Chase (CEO, LangChain) and Nicolas Palaez (Sr. Technical Marketing Manager, Databricks) on LLMs and generative AI. Third guest, Drew Banin (co-founder, dbt Labs), discusses analytics engineering workflow with his company dbt Labs, how he started the company, and how they provide value with the Databricks partnership. Hosted by Ari Kaplan (Head of Evangelism, Databricks) and Pearl Ubaru (Sr Technical Marketing Engineer, Databricks)
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc