A look inside at the data work happening at a company making some of the most advanced technologies in the industry. Rahul Jain, data engineering manager at Snowflake, joins Tristan to discuss Iceberg, streaming, and all things Snowflake. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
 talk-data.com
talk-data.com
Topic
dbt
dbt (data build tool)
data_transformation
analytics_engineering
sql
758
tagged
Activity Trend
134
peak/qtr
2020-Q1
2026-Q2
Top Events
Hamilton Ulmer is working at the intersection of UI, Exploratory Data Analysis, and SQL at MotherDuck, and he's built a long career in EDA. Hamilton and Tristan dive deep into the history of exploratory data analysis. Even if you spend most of your time below the frontend layer of the stack, it is important to understand the trends in both the practice of data visualization and the technologies that underlie that practice. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
Fivetran recently passed $300 million ARR and has over 7,000 customers globally. Taylor Brown, the cofounder and COO of Fivetran, joins the show to talk about Fivetran's moat, the impact of AI on the data ingestion space, and open table formats and catalogs. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
Summary In this episode of the Data Engineering Podcast the inimitable Max Beauchemin talks about reusability in data pipelines. The conversation explores the "write everything twice" problem, where similar pipelines are built without code reuse, and discusses the challenges of managing different SQL dialects and relational databases. Max also touches on the evolving role of data engineers, drawing parallels with front-end engineering, and suggests that generative AI could facilitate knowledge capture and distribution in data engineering. He encourages the community to share reference implementations and templates to foster collaboration and innovation, and expresses hopes for a future where code reuse becomes more prevalent.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm joined again by Max Beauchemin to talk about the challenges of reusability in data pipelinesInterview IntroductionHow did you get involved in the area of data management?Can you start by sharing your current thesis on the opportunities and shortcomings of code and component reusability in the data context?What are some ways that you think about what constitutes a "component" in this context?The data ecosystem has arguably grown more varied and nuanced in recent years. At the same time, the number and maturity of tools has grown. What is your view on the current trend in productivity for data teams and practitioners?What do you see as the core impediments to building more reusable and general-purpose solutions in data engineering?How can we balance the actual needs of data consumers against their requests (whether well- or un-informed) to help increase our ability to better design our workflows for reuse?In data engineering there are two broad approaches; code-focused or SQL-focused pipelines. In principle one would think that code-focused environments would have better composability. What are you seeing as the realities in your personal experience and what you hear from other teams?When it comes to SQL dialects, dbt offers the option of Jinja macros, whereas SDF and SQLMesh offer automatic translation. There are also tools like PRQL and Malloy that aim to abstract away the underlying SQL. What are the tradeoffs across those options that help or hinder the portability of transformation logic?Which layers of the data stack/steps in the data journey do you see the greatest opportunity for improving the creation of more broadly usable abstractions/reusable elements?low/no code systems for code reuseimpact of LLMs on reusability/compositionimpact of background on industry practices (e.g. DBAs, sysadmins, analysts vs. SWE, etc.)polymorphic data models (e.g. activity schema)What are the most interesting, innovative, or unexpected ways that you have seen teams address composability and reusability of data components?What are the most interesting, unexpected, or challenging lessons that you have learned while working on data-oriented tools and utilities?What are your hopes and predictions for sharing of code and logic in the future of data engineering?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links Max's Blog PostAirflowSupersetTableauLookerPowerBICohort AnalysisNextJSAirbytePodcast EpisodeFivetranPodcast EpisodeSegmentdbtSQLMeshPodcast EpisodeSparkLAMP StackPHPRelational AlgebraKnowledge GraphPython MarshmallowData Warehouse Lifecycle Toolkit (affiliate link)Entity Centric Data Modeling Blog PostAmplitudeOSACon presentationol-data-platform Tobias' team's data platform codeThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA

🌟 Session Overview 🌟
Session Name: Data Engineers: Respect the Resiliency of SQL Speaker: Rui Machado Session Description: In the ever-evolving data landscape, SQL's resilience shines, powering critical systems across all industries. Despite new technologies, SQL's core definition and manipulation language remains indispensable, evolving to meet modern demands. This talk explores why SQL endures, spotlighting its integration in innovative tools like dbt and DuckDB, which leverage SQL interfaces for advanced data processing. It will reveal some of the secrets behind SQL's lasting popularity and its pivotal role in the future of data engineering.
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT

🌟 Session Overview 🌟
Session Name: Open Source Entity Resolution - Needs and Challenges Speaker: Sonal Goyal Session Description: Real world data contains multiple records belonging to the same customer. These records can be in single or multiple systems and they have variations across fields, which makes it hard to combine them together, especially with growing data volumes. This hurts customer analytics - establishing lifetime value, loyalty programs, or marketing channels is impossible when the base data is not linked. No AI algorithm for segmentation can produce the right results when there are multiple copies of the same customer lurking in the data. No warehouse can live up to its promise if the dimension tables have duplicates.
With a modern data stack and DataOps, we have established patterns for E and L in ELT for building data warehouses, datalakes and deltalakes. However, the T - getting data ready for analytics still needs a lot of effort. Modern tools like dbt are actively and successfully addressing this. What is also needed is a quick and scalable way to resolve entities to build the single source of truth of core business entities post Extraction and pre or post Loading.
This session would cover the problem of Entity Resolution, its practical applications and challenges in building an entity resolution system. It will also cover Zingg - an Open Source Framework for building Entity Resolution systems. (https://github.com/zinggAI/zingg/) 🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape. Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀 Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts. Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀 🔗 Find Other Years' Videos: 2023 Big Data Conference Europe https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g 2022 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT 2021 Big Data Conference Europe Online https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/ 👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/ 🐦 Twitter: @BigDataConfEU, @europe_rpa 🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/ 🎥 YouTube: http://www.youtube.com/@DATAMINERLT
Cedric Chin runs Commoncog—a publication about accelerating business expertise. He joins Tristan to talk about the analytics development lifecycle, how organizations value (or misvalue) data, and why "data teams are not some IT helpdesk to be ignored." For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.

A highlight reel of all the major dbt product announcements at Coalesce 2024.
Read the blog to learn more about dbt product announcements: https://www.getdbt.com/blog/coalesce-2024-product-announcements
This meeting will focus on real-world use cases. HelloPrint, an online platform for printed products with over 10 million SKUs, leveraged a modern data stack—including DBT, Airflow, and OpenAI—to streamline its product catalog. Our team’s solution reduced manual tasks by 80%, showcasing the power of automation and data-driven processes.
Erik Bernhardsson, the CEO and co-founder of Modal Labs, joins Tristan to talk about Gen AI, the lack of GPUs, the future of cloud computing, and egress fees. They also discuss whether the job title of data engineer is something we should want more or less of in the future. Erik's not afraid of a spicy take, so this is a fun one. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.

Adopting dbt marks a significant leap towards governed data transformations. But with every game-changer, big questions arise: Where do data transformations end? Should they touch the BI layer? What roles do data engineers, analytics engineers, and business analysts play in data modeling? And, is centralizing metrics truly beneficial? Spoiler: It's about finding the balance between freedom and governance.
Our expert panelists will share best practices for scaling dbt to handle transformations and metrics without stifling analyst freedom or causing team burnout. You'll learn how to build a robust metrics layer in dbt and manage business logic as your data operation grows, all by establishing a solid foundation with dbt.
Speakers: Mark Nelson, Silja Mardla, Patrick Vinton, Sarah Levy
Learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
Show description: Scott Breitenother, founder of data consultancy Brooklyn Data Co., joins Tristan at Coalesce 2024 in Las Vegas to discuss the early days of dbt, the evolution of data teams, and what's next for the dbt community. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
As organizations evolve, many still rely on legacy SQL queries and stored procedures that can become bottlenecks in scaling data infrastructure. In this talk, we will explore how to modernize these workflows by migrating legacy SQL and stored procedures into dbt models, enabling more efficient, scalable, and version-controlled data transformations. We’ll discuss practical strategies for refactoring complex logic, ensuring data lineage, data quality and unit testing benefits, and improving collaboration among teams. This session is ideal for data and analytics engineers, analysts, and anyone looking to optimize their ETL workflows using dbt.
Speaker: Bishal Gupta
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Dive into the technical evolution of Bilt’s data infrastructure as they moved from fragmented, slow, and costly analytics to a streamlined, scalable, and holistic solution with dbt Cloud. In this session, the Bilt team will share how they implemented data modeling practices, established a robust CI/CD pipeline, and leveraged dbt’s Semantic Layer to enable a more efficient and trusted analytics environment. Attendees will gain a deep understanding of Bilt’s approach to data including: cost optimization, enhancing data accessibility and reliability, and most importantly, supporting scale and growth.
Speakers: Ben Kramer Director, Data & Analytics Bilt Rewards
James Dorado VP, Data Analytics Bilt Rewards
Nick Heron Senior Manager, Data Analytics Bilt Rewards
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

by
Neha Hystad
Are you making the most of your dbt Cloud deployment? This session is targeted to Admins and will provide guidance on how to leverage dbt Cloud features and workflows to maximize your team’s ability to efficiently deliver quality data products to the broader organization.
Speaker: Neha Hystad
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Making use of AI in the dbt development lifecycle has the potential to be a massive productivity unlock for your team. In this talk, explore how AI-driven approaches can improve your development process with Michiel De Smet from Altimate AI and Anton Goncharuk from Hubspot. Discover practical strategies to automate your work, prevent issues earlier, and embed best practices. Along the way, you'll also get to hear some real-life examples from how the team at HubSpot streamlined their dbt Cloud development workflow and enhanced collaboration within the team.
Speakers: Michiel De Smet Founding Engineer Altimate AI
Anton Goncharuk Principal Analytics Engineer HubSpot
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Are you a dbt Cloud customer aiming to fast-track your company’s journey to GenAI and speed up data development? You can't deploy AI applications without trusting the data that feeds them. Rule-based data quality approaches are a dead end that leaves you in a never-ending maintenance cycle. Join us to learn how modern machine learning approaches to data quality overcome the limits of rules and checks, helping you escape the reactive doom loop and unlock high-quality data for your whole company.
Speakers: Amy Reams VP Business Development Anomalo
Jonathan Karon Partner Innovation Lead Anomalo
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
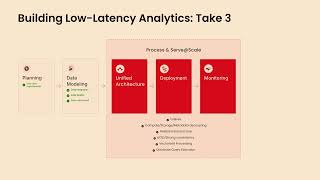
In this session Connor will dive into optimizing compute resources, accelerating query performance, and simplifying data transformations with dbt and cover in detail: - SQL-based data transformation, and why is it gaining traction as the preferred language with data engineers - Life cycle management for native objects like fact tables, dimension tables, primary indexes, aggregating indexes, join indexes, and others. - Declarative, version-controlled data modeling - Auto-generated data lineage and documentation
Learn about incremental models, custom materializations, and column-level lineage. Discover practical examples and real-world use cases how Firebolt enables data engineers to efficiently manage complex tasks and optimize data operations while achieving high efficiency and low latency on their data warehouse workloads.
Speaker: Connor Carreras Solutions Architect Firebolt
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
They say lightning never strikes the same place twice... but what does the data say?
Ever wonder if all those widely accepted "truths" about the world are actually true? In this myth-busting session, we'll leverage public datasets and Hex to challenge common beliefs about everything from human behavior to scientific "facts." We'll do a live walkthrough of he entire process: finding the right data, cleaning it up, analyzing it to separate fact from fiction, and making results easily available to explore and use.
We'll tackle myths across crime, sports, society, and of course, lightning, using real data from crowdsourced and government sources. By the end, we'll have set the record straight on those "truths," and you'll have learned new ways to explore data and make it friendlier non-data folks to engage with.
Speakers: Izzy Miller Hex
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Riot Games, creator of hit titles like League of Legends and Valorant, is building an ultimate gaming experience by using data and AI to deliver the most optimal player journeys. In this session, you'll learn how Riot's data platform team paired with analytics engineering, machine learning, and insights teams to integrate Databricks Data Intelligence Platform and dbt Cloud to significantly mature its data capabilities. The outcome: a scalable, collaborative analytics environment that serves millions of players worldwide.
You’ll hear how Riot Games: - Centralized petabytes of game telemetry on Databricks for fast processing and analytics - Modernized their data platform by integrating dbt Cloud, unlocking governance for modular, version-controlled data transformations and testing for a diverse set of user personas - Uses Generative AI to automate the enforcement of good documentation and quality code and plans to use Databricks AI to further speed up its ability to unlock the value of data - Deployed machine learning models for personalized recommendations and player behavior analysis
You'll come away with practical insights on architecting a modern data stack that can handle massive scale while empowering teams across the organization. Whether you're in gaming or any data-intensive industry, you'll learn valuable lessons from Riot's journey to build a world-class data platform.
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements