This talk explores EDB’s journey from siloed reporting to a unified data platform, powered by Airflow. We’ll delve into the architectural evolution, showcasing how Airflow orchestrates a diverse range of use cases, from Analytics Engineering to complex MLOps pipelines. Learn how EDB leverages Airflow and Cosmos to integrate dbt for robust data transformations, ensuring data quality and consistency. We’ll provide a detailed case study of our MLOps implementation, demonstrating how Airflow manages training, inference, and model monitoring pipelines for Azure Machine Learning models. Discover the design considerations driven by our internal data governance framework and gain insights into our future plans for AIOps integration with Airflow.
 talk-data.com
talk-data.com
Topic
dbt
dbt (data build tool)
data_transformation
analytics_engineering
sql
758
tagged
Activity Trend
134
peak/qtr
2020-Q1
2026-Q2
Top Events
As a popular open-source library for analytics engineering, dbt is often combined with Airflow. Orchestrating and executing dbt models as DAGs ensures an additional layer of control over tasks, observability, and provides a reliable, scalable environment to run dbt models. This workshop will cover a step-by-step guide to Cosmos , a popular open-source package from Astronomer that helps you quickly run your dbt Core projects as Airflow DAGs and Task Groups, all with just a few lines of code. We’ll walk through: Running and visualising your dbt transformations Managing dependency conflicts Defining database credentials (profiles) Configuring source and test nodes Using dbt selectors Customising arguments per model Addressing performance challenges Leveraging deferrable operators Visualising dbt docs in the Airflow UI Example of how to deploy to production Troubleshooting We encourage participants to bring their dbt project to follow this step-by-step workshop.
OpenLineage has simplified collecting lineage metadata across the data ecosystem by standardizing its representation in an extensible model. It enabled a whole ecosystem improving data pipeline reliability and ease of troubleshooting in production environments. In this talk, we’ll briefly introduce the OpenLineage model and explore how this metadata is collected from Airflow, Spark, dbt, and Flink. We’ll demonstrate how to extract valuable insights and outline practical benefits and common challenges when building ingestion, processing and storage for OpenLineage data. We will also briefly show how OpenLineage events can be used to observe data pipelines exhastively and the benefits that brings.

In this talk, we will dive into the latest tools and ideas dbt Labs has been shipping — what they unlock, how they fit together, and why we built them the way we did.
We’ll start with a walkthrough of the technical setup of dbt at the Port of Antwerp-Bruges, in the context of a migration to Databricks. Then we'll dive into how we handle deploying dbt to multiple targets for the duration of the migration. Finally we'll compare both environments with insights from an analytics engineering perspective.
With data teams' growing ambition to build business automation, AI systems, or customer-facing products, we must shift our mindset about data quality. Mechanically applied testing will not be enough; we need a more robust strategy similar to software engineering. In this talk, I outline a new approach to data testing and observability anchored in the ‘Data Products’ concept and walk through the practical implementation of a production-grade analytics system with dbt as the backbone. The learnings will apply to data practitioners using dbt whether they're just getting started or working in a large enterprise.
In this season of the Analytics Engineering podcast, Tristan is digging deep into the world of developer tools and databases. There are few more widely used developer tools than Docker. From its launch back in 2013, Docker has completely changed how developers ship applications. In this episode, Tristan talks to Solomon Hykes, the founder and creator of Docker. They trace Docker's rise from startup obscurity to becoming foundational infrastructure in modern software development. Solomon explains the technical underpinnings of containerization, the pivotal shift from platform-as-a-service to open-source engine, and why Docker's developer experience was so revolutionary. The conversation also dives into his next venture Dagger, and how it aims to solve the messy, overlooked workflows of software delivery. Bonus: Solomon shares how AI agents are reshaping how CI/CD gets done and why the next revolution in DevOps might already be here. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
Discussion on how dbt powers the AI-ready data lake.
A talk about the latest tools from dbt Labs for builders.
Presentation detailing the latest tools from dbt Labs for builders.
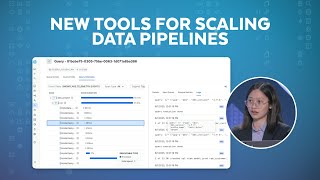
Learn how to efficiently scale and manage data engineering pipelines with Snowflake's latest capabilities for SQL- and Python-based transformations. Join us for new product and feature overviews, best practices and live demos.
In our recent study, an overwhelming majority—80% of respondents—reported using AI in their day-to-day workflows. This marks a significant increase from just a year ago, when only 30% were doing so.
But what about data quality? Can you trust your data?
In this session, we’ll discuss how dbt can help organizations increase trust in their data, improve performance and governance, and control costs more effectively.
dbt is widely regarded as the industry standard for AI on structured data. Its Fusion engine, with deep SQL comprehension, powers the next generation of dbt use cases.

Ludia, a leading mobile gaming company, is empowering its analysts and domain experts by democratizing data engineering with Databricks and dbt. This talk explores how Ludia enabled cross-functional teams to build and maintain production-grade data pipelines without relying solely on centralized data engineering resources—accelerating time to insight, improving data reliability, and fostering a culture of data ownership across the organization.

Riot Games reduced its Databricks compute spend and accelerated development cycles by transforming its data engineering workflows—migrating from bespoke Databricks notebooks and Spark pipelines to a scalable, testable, and developer-friendly dbt-based architecture. In this talk, members of the Developer Experience & Automation (DEA) team will walk through how they designed and operationalized dbt to support Riot’s evolving data needs.

This session will showcase Bosch’s journey in consolidating supply chain information using the Databricks platform. It will dive into how Databricks not only acts as the central data lakehouse but also integrates seamlessly with transformative components such as dbt and Large Language Models (LLMs). The talk will highlight best practices, architectural considerations, and the value of an interoperable platform in driving actionable insights and operational excellence across complex supply chain processes. Key Topics and Sections Introduction & Business Context Brief Overview of Bosch’s Supply Chain Challenges and the Need for a Consolidated Data Platform. Strategic Importance of Data-Driven Decision-Making in a Global Supply Chain Environment. Databricks as the Core Data Platform Integrating dbt for Transformation Leveraging LLM Models for Enhanced Insights

HP Print's data platform team took on a migration from a monolithic, shared resource of AWS Redshift, to a modular and scalable data ecosystem on Databricks lakehouse. The result was 30–40% cost savings, scalable and isolated resources for different data consumers and ETL workloads, and performance optimization for a variety of query types. Through this migration, there were technical challenges and learnings relating to the ETL migrations with DBT, new Databricks features like Liquid Clustering, predictive optimization, Photon, SQL serverless warehouses, managing multiple teams on Unity Catalog, and others. This presentation dives into both the business and technical sides of this migration. Come along as we share our key takeaways from this journey.
by
Nina Anderson
(dbt Labs)
,
Mitch Ertle
(Sigma)
,
David Hrncir
(Fivetran)
,
Pradeep Anandapu
(Databricks)
This hands-on lab guides participants through the complete customer data analytics journey on Databricks, leveraging leading partner solutions - Fivetran, dbt Cloud, and Sigma. Attendees will learn how to:- Seamlessly connect to Fivetran, dbt Cloud, and Sigma using Databricks Partner Connect- Ingest data using Fivetran, transform and model data with dbt Cloud, and create interactive dashboards in Sigma, all on top of the Databricks Data Intelligence Platform- Empower teams to make faster, data-driven decisions by streamlining the entire analytics workflow using an integrated, scalable, and user-friendly platform

In this session, we will share NCS’s approach to implementing a Databricks Lakehouse architecture, focusing on key lessons learned and best practices from our recent implementations. By integrating Databricks SQL Warehouse, the DBT Transform framework and our innovative test automation framework, we’ve optimized performance and scalability, while ensuring data quality. We’ll dive into how Unity Catalog enabled robust data governance, empowering business units with self-serve analytical workspaces to create insights while maintaining control. Through the use of solution accelerators, rapid environment deployment and pattern-driven ELT frameworks, we’ve fast-tracked time-to-value and fostered a culture of innovation. Attendees will gain valuable insights into accelerating data transformation, governance and scaling analytics with Databricks.

Dynamic Insert Overwrite is an important Delta Lake feature that allows fine-grained updates by selectively overwriting specific rows, eliminating the need for full-table rewrites. For examples, this capability is essential for: DBT-Databricks' incremental models/workloads, enabling efficient data transformations by processing only new or updated records ETL Slowly Changing Dimension (SCD) Type 2 In this lightning talk, we will: Introduce Dynamic Insert Overwrite: Understand its functionality and how it works Explore key use cases: Learn how it optimizes performance and reduces costs Share best practices: Discover practical tips for leveraging this feature on Databricks, including on the cutting-edge Serverless SQL Warehouses