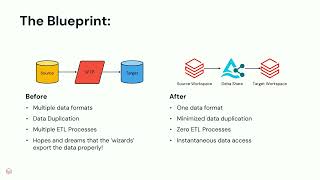
Bagelcode, a leader in the social casino industry, has utilized Databricks since 2018 and manages over 10,000 tables via Hive Metastore. In 2024, we embarked on a transformative journey to resolve inefficiencies and unlock new capabilities. Over five months, we redesigned ETL pipelines with Delta Lake, optimized partitioned table logs and executed a seamless migration with minimal disruption. This effort improved governance, simplified management and unlocked Unity Catalog’s advanced features. Post-migration, we integrated the Genie Room with Slack to enable natural language queries, accelerating decision-making and operational efficiency. Additionally, a lineage-powered internal tool allowed us to quickly identify and resolve issues like backfill needs or data contamination. Unity Catalog has revolutionized our data ecosystem, elevating governance and innovation. Join us to learn how Bagelcode unlocked its data’s full potential and discover strategies for your own transformation.