Meta has been at the absolute edge of the open-source AI ecosystem, and with the recent release of Llama 3.1, they have officially created the largest open-source model to date. So, what's the secret behind the performance gains of Llama 3.1? What will the future of open-source AI look like? Thomas Scialom is a Senior Staff Research Scientist (LLMs) at Meta AI, and is one of the co-creators of the Llama family of models. Prior to joining Meta, Thomas worked as a Teacher, Lecturer, Speaker and Quant Trading Researcher. In the episode, Adel and Thomas explore Llama 405B it’s new features and improved performance, the challenges in training LLMs, best practices for training LLMs, pre and post-training processes, the future of LLMs and AI, open vs closed-sources models, the GenAI landscape, scalability of AI models, current research and future trends and much more. Links Mentioned in the Show: Meta - Introducing Llama 3.1: Our most capable models to dateDownload the Llama Models[Course] Working with Llama 3[Skill Track] Developing AI ApplicationsRelated Episode: Creating Custom LLMs with Vincent Granville, Founder, CEO & Chief Al Scientist at GenAltechLab.comRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
 talk-data.com
talk-data.com
Topic
GenAI
Generative AI
1517
tagged
Activity Trend
Top Events
Ready for more ideas about UX for AI and LLM applications in enterprise environments? In part 2 of my topic on UX considerations for LLMs, I explore how an LLM might be used for a fictitious use case at an insurance company—specifically, to help internal tools teams to get rapid access to primary qualitative user research. (Yes, it’s a little “meta”, and I’m also trying to nudge you with this hypothetical example—no secret!) ;-) My goal with these episodes is to share questions you might want to ask yourself such that any use of an LLM is actually contributing to a positive UX outcome Join me as I cover the implications for design, the importance of foundational data quality, the balance between creative inspiration and factual accuracy, and the never-ending discussion of how we might handle hallucinations and errors posing as “facts”—all with a UX angle. At the end, I also share a personal story where I used an LLM to help me do some shopping for my favorite product: TRIP INSURANCE! (NOT!)
Highlights/ Skip to:
(1:05) I introduce a hypothetical internal LLM tool and what the goal of the tool is for the team who would use it (5:31) Improving access to primary research findings for better UX (10:19) What “quality data” means in a UX context (12:18) When LLM accuracy maybe doesn’t matter as much (14:03) How AI and LLMs are opening the door for fresh visioning work (15:38) Brian’s overall take on LLMs inside enterprise software as of right now (18:56) Final thoughts on UX design for LLMs, particularly in the enterprise (20:25) My inspiration for these 2 episodes—and how I had to use ChatGPT to help me complete a purchase on a website that could have integrated this capability right into their website
Quotes from Today’s Episode “If we accept that the goal of most product and user experience research is to accelerate the production of quality services, products, and experiences, the question is whether or not using an LLM for these types of questions is moving the needle in that direction at all. And secondly, are the potential downsides like hallucinations and occasional fabricated findings, is that all worth it? So, this is a design for AI problem.” - Brian T. O’Neill (8:09) “What’s in our data? Can the right people change it when the LLM is wrong? The data product managers and AI leaders reading this or listening know that the not-so-secret path to the best AI is in the foundational data that the models are trained on. But what does the word quality mean from a product standpoint and a risk reduction one, as seen from an end-users’ perspective? Somebody who’s trying to get work done? This is a different type of quality measurement.” - Brian T. O’Neill (10:40)
“When we think about fact retrieval use cases in particular, how easily can product teams—internal or otherwise—and end-users understand the confidence of responses? When responses are wrong, how easily, if at all, can users and product teams update the model’s responses? Errors in large language models may be a significant design consideration when we design probabilistic solutions, and we no longer control what exactly our products and software are going to show to users. If bad UX can include leading people down the wrong path unknowingly, then AI is kind of like the team on the other side of the tug of war that we’re playing.” - Brian T. O’Neill (11:22) “As somebody who writes a lot for my consulting business, and composes music in another, one of the hardest parts for creators can be the zero-to-one problem of getting started—the blank page—and this is a place where I think LLMs have great potential. But it also means we need to do the proper research to understand our audience, and when or where they’re doing truly generative or creative work—such that we can take a generative UX to the next level that goes beyond delivering banal and obviously derivative content.” - Brian T. O’Neill (13:31) “One thing I actually like about the hype, investment, and excitement around GenAI and LLMs in the enterprise is that there is an opportunity for organizations here to do some fresh visioning work. And this is a place that designers and user experience professionals can help data teams as we bring design into the AI space.” - Brian T. O’Neill (14:04)
“If there was ever a time to do some new visioning work, I think now is one of those times. However, we need highly skilled design leaders to help facilitate this in order for this to be effective. Part of that skill is knowing who to include in exercises like this, and my perspective, one of those people, for sure, should be somebody who understands the data science side as well, not just the engineering perspective. And as I posited in my seminar that I teach, the AI and analytical data product teams probably need a fourth member. It’s a quartet and not a trio. And that quartet includes a data expert, as well as that engineering lead.” - Brian T. O’Neill (14:38)
Links Perplexity.ai: https://perplexity.ai Ideaflow: https://www.amazon.com/Ideaflow-Only-Business-Metric-Matters/dp/0593420586 My article that inspired this episode
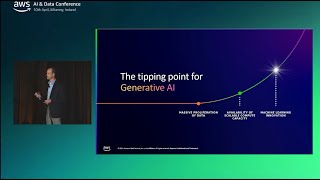
In this session, Rick Sears, General Manager of Amazon Athena, EMR, and Lake Formation at AWS, explores how generative AI is revolutionizing businesses and the critical role data plays in this transformation. He discusses the evolution of AI models and the importance of a comprehensive data management strategy encompassing availability, quality, and protection of data.
Mark Greville, Vice President of Architecture at Workhuman, shares insights from Workhuman's journey in building a robust cloud-based data strategy, emphasizing the significance of storytelling, demonstrating value, and gaining executive support.
Kamal Sampathkumar, Senior Manager of Data Architecture at Workhuman, delves into the technical aspects, detailing the architecture of Workhuman's data platform and showcasing solutions like Data API and self-service reporting that deliver substantial value to customers.
Learn more at: https://go.aws/3x2mha0
Learn more about AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world’s most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSEvents #awsaianddataconference #generativeaiconference #genaiconference #genaievent #AWSgenerativeai #AWSgenai
Excel often gets unfair criticism from data practitioners, many of us will remember a time when Excel was looked down upon—why would anyone use Excel when we have powerful tools like Python, R, SQL, or BI tools? However, like it or not, Excel is here to stay, and there’s a meme, bordering on reality, that Excel is carrying a large chunk of the world’s GDP. But when it really comes down to it, can you do data science in Excel? Jordan Goldmeier is an entrepreneur, a consultant, a best-selling author of four books on data, and a digital nomad. He started his career as a data scientist in the defense industry for Booz Allen Hamilton and The Perduco Group, before moving into consultancy with EY, and then teaching people how to use data at Excel TV, Wake Forest University, and now Anarchy Data. He also has a newsletter called The Money Making Machine, and he's on a mission to create 100 entrepreneurs. In the episode, Adel and Jordan explore excel in data science, excel’s popularity, use cases for Excel in data science, the impact of GenAI on Excel, Power Query and data transformation, advanced Excel features, Excel for prototyping and generating buy-in, the limitations of Excel and what other tools might emerge in its place, and much more. Links Mentioned in the Show: Data Smart: Using Data Science to Transform Information Into Insight by Jordan Goldmeier[Webinar] Developing a Data Mindset: How to Think, Speak, and Understand Data[Course] Data Analysis in ExcelRelated Episode: Do Spreadsheets Need a Rethink? With Hjalmar Gislason, CEO of GRIDRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Summary Generative AI has rapidly gained adoption for numerous use cases. To support those applications, organizational data platforms need to add new features and data teams have increased responsibility. In this episode Lior Gavish, co-founder of Monte Carlo, discusses the various ways that data teams are evolving to support AI powered features and how they are incorporating AI into their work. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.Your host is Tobias Macey and today I'm interviewing Lior Gavish about the impact of AI on data engineersInterview IntroductionHow did you get involved in the area of data management?Can you start by clarifying what we are discussing when we say "AI"?Previous generations of machine learning (e.g. deep learning, reinforcement learning, etc.) required new features in the data platform. What new demands is the current generation of AI introducing?Generative AI also has the potential to be incorporated in the creation/execution of data pipelines. What are the risk/reward tradeoffs that you have seen in practice?What are the areas where LLMs have proven useful/effective in data engineering?Vector embeddings have rapidly become a ubiquitous data format as a result of the growth in retrieval augmented generation (RAG) for AI applications. What are the end-to-end operational requirements to support this use case effectively?As with all data, the reliability and quality of the vectors will impact the viability of the AI application. What are the different failure modes/quality metrics/error conditions that they are subject to?As much as vectors, vector databases, RAG, etc. seem exotic and new, it is all ultimately shades of the same work that we have been doing for years. What are the areas of overlap in the work required for running the current generation of AI, and what are the areas where it diverges?What new skills do data teams need to acquire to be effective in supporting AI applications?What are the most interesting, innovative, or unexpected ways that you have seen AI impact data engineering teams?What are the most interesting, unexpected, or challenging lessons that you have learned while working with the current generation of AI?When is AI the wrong choice?What are your predictions for the future impact of AI on data engineering teams?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your Links Monte CarloPodcast EpisodeNLP == Natural Language ProcessingLarge Language ModelsGenerative AIMLOpsML EngineerFeature StoreRetrieval Augmented Generation (RAG)LangchainThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
In this session, we'll learn how developers of all skill levels can use the Gemini API to build cutting-edge AI applications, regardless of programming language. Discover how to leverage Gemini's unique features for responsible AI, Google Search integration, custom data grounding, and more and the benefits and trade-offs for each model.
In this session, we will explore the architecture of Diffusers models and discuss components such as VAE and UNet. An example will be presented of how to combine text-to-image and image-to-image into one data pipeline with the Cloudera Data Platform (CDP). Specific emphasis will be placed on using ControlNet, PyTorch, and metadata persistence within CDP for editing images.
Session on exploring Amazon BedRock and Amazon Q within GenAI on AWS.
This special episode of DataFramed was made in collaboration with Analytics on Fire! Nowadays, the hype around generative AI is only the tip of the iceberg. There are so many ideas being touted as the next big thing that it’s difficult to keep up. More importantly, it’s challenging to discern which ideas will become the next ChatGPT and which will end up like the next NFT. How do we cut through the noise? Mico Yuk is the Community Manager at Acryl Data and Co-Founder at Data Storytelling Academy. Mico is also an SAP Mentor Alumni, and the Founder of the popular weblog, Everything Xcelsius and the 'Xcelsius Gurus’ Network. She was named one of the Top 50 Analytics Bloggers to follow, as-well-as a high-regarded BI influencer and sought after global keynote speaker in the Analytics ecosystem. In the episode, Richie and Mico explore AI and productivity at work, the future of work and AI, GenAI and data roles, AI for training and learning, training at scale, decision intelligence, soft skills for data professionals, genAI hype and much more. Links Mentioned in the Show: Analytics on Fire PodcastData Visualization for Dummies by Mico Yuk and Stephanie DiamondConnect with Miko[Skill Track] AI FundamentalsRelated Episode: What to Expect from AI in 2024 with Craig S. Smith, Host of the Eye on A.I PodcastRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
Send us a text Mastering SEO and Consumer Insights with Sam Torres, CDO of Gray Dot Company. And getting educated on gaming. Sam Torres is the Chief Digital Officer and co-founder of The Gray Dot Company, Gray Dot Company is a consulting firm that specializes in search engine optimization. Sam outlines expertise in complex digital analytics and consumer insights data. 03:40 Meet Sam Torres05:57 Marketing Platforms07:49 Digital Consumer Intelligence14:55 Defining Success17:55 AIs Impact on Google22:07 Should I Trust Sponsored Adds?23:58 GenAI Positives LinkedIn: linkedin.com/in/samantha-torres-seo Website: https://thegray.company, https://legendarypodcasts.com/sam-torres/ Want to be featured as a guest on Making Data Simple? Reach out to us [email protected] and tell us why you should be next. The MakingData Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, wherewe explore trending technologies, business innovation, and leadership ... whilekeeping it simple & fun. Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun. Want to be featured as a guest on Making Data Simple? Reach out to us at [email protected] and tell us why you should be next. The Making Data Simple Podcast is hosted by Al Martin, WW VP Technical Sales, IBM, where we explore trending technologies, business innovation, and leadership ... while keeping it simple & fun.
Despite GPT, Claude, Gemini, LLama and the other host of LLMs that we have access to, a variety of organizations are still exploring their options when it comes to custom LLMs. Logging in to ChatGPT is easy enough, and so is creating a 'custom' openAI GPT, but what does it take to create a truly custom LLM? When and why might this be useful, and will it be worth the effort? Vincent Granville is a pioneer in the AI and machine learning space, he is Co-Founder of Data Science Central, Founder of MLTechniques.com, former VC-funded executive, author, and patent owner. Vincent’s corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. He is also a former post-doc at Cambridge University and the National Institute of Statistical Sciences. Vincent has published in the Journal of Number Theory, Journal of the Royal Statistical Society, and IEEE Transactions on Pattern Analysis and Machine Intelligence. He is the author of multiple books, including “Synthetic Data and Generative AI”. In the episode, Richie and Vincent explore why you might want to create a custom LLM including issues with standard LLMs and benefits of custom LLMs, the development and features of custom LLMs, architecture and technical details, corporate use cases, technical innovations, ethics and legal considerations, and much more. Links Mentioned in the Show: Read Articles by VincentSynthetic Data and Generative AI by Vincent GranvilleConnect with Vincent on Linkedin[Course] Developing LLM Applications with LangChainRelated Episode: The Power of Vector Databases and Semantic Search with Elan Dekel, VP of Product at PineconeRewatch sessions from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business

At this year's event, over 250 customers shared their data and AI journies. They showcased a wide variety of use cases, best practices and lessons from their leadership and innovation with the latest data and AI technologies.
See how enterprises are leveraging generative AI in their data operations and how innovative data management and data governance are fueling organizations as they race to develop GenAI applications. https://www.databricks.com/blog/how-real-world-enterprises-are-leveraging-generative-ai
To see more real-world use cases and customer success stories, visit: https://www.databricks.com/customers
Data analytics is a balance of flexibility for innovation and governance to control risks. This blog discusses its implications for artificial intelligence (AI), including machine learning (ML) and generative AI (GenAI). Published at: https://www.eckerson.com/articles/ai-ml-innovation-requires-a-flexible-yet-governed-data-architecture
Focus Sessions run by our host and sponsors: Protecting the planet from Generative AI (Capgemini Invent); Integrating FinOps & Sustainability (Apptio/IBM); Emissions Data - what can you believe? (GreenPixie); Kick-starting action on Sustainability (FinOps Ninja)
Let’s talk about design for AI (which more and more, I’m agreeing means GenAI to those outside the data space). The hype around GenAI and LLMs—particularly as it relates to dropping these in as features into a software application or product—seems to me, at this time, to largely be driven by FOMO rather than real value. In this “part 1” episode, I look at the importance of solid user experience design and outcome-oriented thinking when deploying LLMs into enterprise products. Challenges with immature AI UIs, the role of context, the constant game of understanding what accuracy means (and how much this matters), and the potential impact on human workers are also examined. Through a hypothetical scenario, I illustrate the complexities of using LLMs in practical applications, stressing the need for careful consideration of benchmarks and the acceptance of GenAI's risks.
I also want to note that LLMs are a very immature space in terms of UI/UX design—even if the foundation models continue to mature at a rapid pace. As such, this episode is more about the questions and mindset I would be considering when integrating LLMs into enterprise software more than a suggestion of “best practices.”
Highlights/ Skip to:
(1:15) Currently, many LLM feature initiatives seem to mostly driven by FOMO (2:45) UX Considerations for LLM-enhanced enterprise applications (5:14) Challenges with LLM UIs / user interfaces (7:24) Measuring improvement in UX outcomes with LLMs (10:36) Accuracy in LLMs and its relevance in enterprise software (11:28) Illustrating key consideration for implementing an LLM-based feature (19:00) Leadership and context in AI deployment (19:27) Determining UX benchmarks for using LLMs (20:14) The dynamic nature of LLM hallucinations and how we design for the unknown (21:16) Closing thoughts on Part 1 of designing for AI and LLMs
Quotes from Today’s Episode
“While many product teams continue to race to deploy some sort of GenAI and especially LLMs into their products—particularly this is in the tech sector for commercial software companies—the general sense I’m getting is that this is still more about FOMO than anything else.” - Brian T. O’Neill (2:07) “No matter what the technology is, a good user experience design foundation starts with not doing any harm, and hopefully going beyond usable to be delightful. And adding LLM capabilities into a solution is really no different. So, we still need to have outcome-oriented thinking on both our product and design teams when deploying LLM capabilities into a solution. This is a cornerstone of good product work.” - Brian T. O’Neill (3:03)
“So, challenges with LLM UIs and UXs, right, user interfaces and experiences, the most obvious challenge to me right now with large language model interfaces is that while we’ve given users tremendous flexibility in the form of a Google search-like interface, we’ve also in many cases, limited the UX of these interactions to a text conversation with a machine. We’re back to the CLI in some ways.” - Brian T. O’Neill (5:14) “Before and after we insert an LLM into a user’s workflow, we need to know what an improvement in their life or work actually means.”- Brian T. O’Neill (7:24) "If it would take the machine a few seconds to process a result versus what might take a day for a worker, what’s the role and purpose of that worker going forward? I think these are all considerations that need to be made, particularly if you’re concerned about adoption, which a lot of data product leaders are." - Brian T. O’Neill (10:17)
“So, there’s no right or wrong answer here. These are all range questions, and they’re leadership questions, and context really matters. They are important to ask, particularly when we have this risk of reacting to incorrect information that looks plausible and believable because of how these LLMs tend to respond to us with a positive sheen much of the time.” - Brian T. O’Neill (19:00)
Links
View Part 1 of my article on UI/UX design considerations for LLMs in enterprise applications: https://designingforanalytics.com/resources/ui-ux-design-for-enterprise-llms-use-cases-and-considerations-for-data-and-product-leaders-in-2024-part-1/
Your generative AI applications can deliver better responses by incorporating organization-specific data. In this session, we will talk about how you can use your organization’s data with Generative AI and how you can simplify the process using Knowledge Bases for Amazon Bedrock. This session is suitable for either business or technical individuals wanting to achieve the best outcomes from their Generative AI applications.
Send us a text Welcome to the cozy corner of the tech world where ones and zeros mingle with casual chit-chat. Datatopics Unplugged is your go-to spot for relaxed discussions around tech, news, data, and society. Dive into conversations that should flow as smoothly as your morning coffee (but don’t), where industry insights meet laid-back banter. Whether you're a data aficionado or just someone curious about the digital age, pull up a chair, relax, and let's get into the heart of data, unplugged style! In this episode, we explore: LLMs Gaming the System: Uncover how LLMs are using political sycophancy and tool-using flattery to game the system. Dive deeper: paper, chain of thought prompting & post on x.Recording Industry Association of America (RIAA) Sue AI Music Generators: They are taking on Suno and Udio for using copyrighted music to train their models. Some ai generated music that is very similar to existing songs: song 1, song 2, song 3. More on GenAI: midjourney creating copyrighted images, and chatGPT reciting email-adresses.AI-Powered Olympic Recaps: NBC’s personalized daily recaps with Al Michaels' voice offer a new way to catch up on the Olympics.Figma’s AI Redesign: Discover Figma’s new AI tools that speed up design and creativity. We debate the tool's value and its application in the design process. Rabbit R1 Security Flaws: Hackers exposed hardcoded API keys in Rabbit R1’s source code, leading to major security issues. Find out more.Pyinstrument for Python: Meet Pyinstrument, the easy-to-use Python profiler that optimizes code performance. Explore it on GitHub.The Ultimate Font - Bart’s dreams come true: Explore the groundbreaking integration of True Type Fonts with AI for dynamic text rendering. Discover more here.Hot Takes on AI Competition: Google claims no one has a moat in AI, sparking debate on open-source models' future. We also explore Ladybird Browser Project, an independently funded browser project aiming to build a cutting-edge browser engine.
Generative AI is here to stay, fundamentally altering our relationship with technology. But what does its future hold? In this session, Tom Tunguz, General Partner at Theory Ventures, Edo Liberty, CEO at Pinecone, and Nick Elprin, CEO at Domino Data Lab, explore how generative AI tools & technologies will evolve in the months and years to come. They navigate through emerging trends, potential breakthrough applications, and the strategic implications for businesses poised to capitalize on this technological wave. Links Mentioned in the Show: Rewatch Session from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile appEmpower your business with world-class data and AI skills with DataCamp for business
The Data Product Management In Action podcast, brought to you by Soda and executive producer Scott Hirleman, is a platform for data product management practitioners to share insights and experiences. In Season 01, Episode 06, host Frannie Helforoush (Senior Digital Product Manager at RBC Global Asset Management) and guest Nathan Worrell (Senior Product Manager, Data Analytics at Cortland) explore areas that are crucial to successfully realizing data product management and delivering value. With Nathan's experience and passion, he shares his thoughts on applying product thinking to data products and emphasizes the often-forgotten core soft skills necessary to augment success. They leave no stone unturned as they dive into the detail of product thinking. Nathan provides practical, concrete examples that are easy for anyone to take away and implement, including the strategic use of Generative AI. About our host Frannie Helforoush: Frannie's journey began as a software engineer and evolved into a strategic product manager. Now, as a data product manager, she leverages her expertise in both fields to create impactful solutions. Frannie thrives on making data accessible and actionable, driving product innovation, and ensuring product thinking is integral to data management. Connect with Frannie on LinkedIn. About our guest Nathan Worrell: Nathan is a dynamic product manager with a passion for AI, data, and process optimization. He has a proven track record of success across multiple industries, leading complex initiatives and building products from the ground up. Nathan thrives on working with diverse teams with the goal of driving businesses to become more data-driven. Connect with Nathan on LinkedIn. All views and opinions expressed are those of the individuals and do not necessarily reflect their employers or anyone else. Join the conversation on LinkedIn. Apply to be a guest or nominate someone that you know.
Generative AI's transformative power underscores the critical need for high-quality data. In this session, Barr Moses, CEO of Monte Carlo Data, Prukalpa Sankar, Cofounder at Atlan, and George Fraser, CEO at Fivetran, discuss the nuances of scaling data quality for generative AI applications, highlighting the unique challenges and considerations that come into play. Throughout the session, they share best practices for data and AI leaders to navigate these challenges, ensuring that governance remains a focal point even amid the AI hype cycle. Links Mentioned in the Show: Rewatch Session from RADAR: AI Edition New to DataCamp? Learn on the go using the DataCamp mobile app Empower your business with world-class data and AI skills with DataCamp for business