Presentation about contributing to Docling.
 talk-data.com
talk-data.com
Topic
Python
programming_language
data_science
web_development
1446
tagged
Activity Trend
185
peak/qtr
2020-Q1
2026-Q2
Top Events
O'Reilly Data Science Books
220
Data Engineering Podcast
183
O'Reilly Data Engineering Books
151
SciPy 2025
67
PyConDE & PyData Berlin 2023
49
Data + AI Summit 2025
30
Databricks DATA + AI Summit 2023
29
O'Reilly AI & ML Books
27
PyData Seattle 2025
23
PyData Paris 2025
20
O'Reilly Data Visualization Books
20
PyData London 2025
20
Analyzing how patterns evolve over time in multi-dimensional datasets is challenging—traditional time-series methods often struggle with interpretability when comparing multiple entities across different scales. This talk introduces a clustering-based framework that transforms continuous data into categorical trajectories, enabling intuitive visualization and comparison of temporal patterns.What & Why: The method combines quartile-based categorization with modified Hamming distance to create interpretable "trajectory fingerprints" for entities over time. This approach is particularly valuable for policy analysis, economic comparisons, and any domain requiring longitudinal pattern recognition.Who: Data scientists and analysts working with temporal datasets, policy researchers, and anyone interested in comparative analysis across entities with different scales or distributions.Type: Technical presentation with practical implementation examples using Python (pandas, scikit-learn, matplotlib). Moderate mathematical content balanced with intuitive visualizations.Takeaway: Attendees will learn a novel approach to temporal pattern analysis that bridges the gap between complex statistical methods and accessible, policy-relevant insights. You'll see practical implementations analyzing 60+ years of fiscal policy data across 8 countries, with code available for adaptation to your own datasets.

Rivers have long been storytellers of human history. From the Nile to the Yangtze, they have shaped trade, migration, settlement, and the rise of civilizations. They reveal the traces of human ambition... and the costs of it. Today, from the Charles to the Golden Gate, US rivers continue to tell stories, especially through data.
Over the past decades, extensive water quality monitoring efforts have generated vast public datasets: millions of measurements of pH, dissolved oxygen, temperature, and conductivity collected across the country. These records are more than environmental snapshots; they are archives of political priorities, regulatory choices, and ecological disruptions. Ultimately, they are evidence of how societies interact with their environments, often unevenly.
In this talk, I’ll explore how Python and modern data workflows can help us "listen" to these stories at scale. Using the United States Geological Survey (USGS) Water Data APIs and Remote SSH in Positron, I’ll process terabytes of sensor data spanning several years and regions. I’ll demonstrate that, while Parquet and DuckDB enable scalable exploration of historical records, using Remote SSH is paramount in order to enable large-scale data analysis. By doing so, I hope to answer some analytical questions that can surface patterns linked to industrial growth, regulatory shifts, and climate change.
By treating rivers as both ecological systems and social mirrors, we can begin to see how environmental data encodes histories of inequality, resilience, and transformation.
Whether your interest lies in data engineering, environmental analytics, or the human dimensions of climate and infrastructure, this talk will explore topics at the intersection of environmental science, will offer both technical methods and sociological lenses to understand the stories rivers continue to tell.
We all mix pictures, emojis and text freely in our communications. So, why not in our code? This session takes a whimsical look at what mixing emoji with Python and SQL might look like (spoiler alert: a lot like those "rebus" stories in Highlights Magazine for Kids!). We'll discuss the benefits of doing so, challenges that emoji present, and demo a rudimentary Python preprocessor that intercepts Python and SQL code containing emojis submitted from Jupyter notebooks and translates it back into text-only code using an emoji-to-text dictionary before passing it on to Python for execution. This session is intended for all levels of programmers.
AI red teaming is crucial for identifying security and safety vulnerabilities (e.g., jailbreaks, prompt injection, harmful content generation) of Large Language Models. However, manual and brute-force adversarial testing is resource-intensive and often inefficiently consumes time and compute resources exploring low-risk regions of the input space. This talk introduces a practical, Python-based methodology for accelerating red teaming using model uncertainty quantification (UQ).

Python is controlled by the community and that its vast library of packages remain free for anyone to use and open for anyone to add to -- and that's no accident. Open communities that share and learn together are how we will build the kind of future we want to live in. If you've ever wondered who is in charge of Python, how it exists as a perennially free resource and why anyone would do that, this talk is for you!
Many Python users want features that don’t fit within the boundaries of their favorite libraries. Instead of forking or waiting on a pull request, you can build your own wrapper or extender package. This talk introduces the principles of designing companion packages that enhance existing libraries without changing their core code, using gt-extras as a case study. You’ll learn how to structure, document, and distribute your own add-ons to extend the tools you rely on.
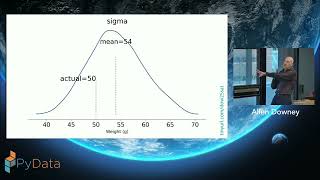
Why do male test takers consistently score about 30 points higher than female test takers on the mathematics section of the SAT? Does this reflect an actual difference in math ability, or is it an artifact of selection bias—if young men with low math ability are less likely to take the test than young women with the same ability?
This talk presents a Bayesian model that estimates how much of the observed difference can be explained by selection effects. We’ll walk through a complete Bayesian workflow, including prior elicitation with PreliZ, model building in PyMC, and validation with ArviZ, showing how Bayesian methods disentangle latent traits from observed outcomes and separate the signal from the noise.
No prior knowledge of Bayesian statistics is required; attendees should be familiar with Python and common probability distributions.
Fantasy basketball involves daily decisions: which players to start, who to pick up from free agency, and how to balance competing objectives across multiple statistical categories. This talk demonstrates how linear programming and integer programming can help solving those problems.
Using Python library PuLP we'll explore when to use linear programming versus integer programming, how to formulate constraints for roster decisions, and how to handle different league formats. Through practical examples, we'll build optimizers for start/sit decisions and free agency streaming.
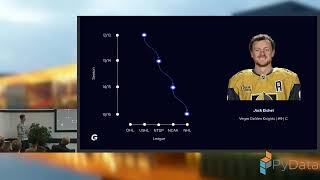
How can data science help young athletes navigate their careers? In this talk, I’ll share my experience building a career path planner for aspiring ice hockey players. The project combines player performance data, career path patterns, and predictive modeling to suggest possible development paths and milestones. Along the way, I’ll discuss the challenges of messy sports data and communicating insights in a way that resonates with non-technical users like coaches, parents, and players.
What if your database could run Python code inside SQL? In this talk, we’ll explore how to extend popular databases using Python, without needing to write a line of C.
We’ll cover three systems—SQLite, DuckDB, and PostgreSQL—and show how Python can be used in each to build custom SQL functions, accelerate data workflows, and prototype analytical logic. Each database offers a unique integration path: - SQLite and DuckDB allow you to register Python functions directly into SQL via sqlite3.create_function, making it easy to inject business logic or custom transformations. - PostgreSQL offers PL/Python, a full-featured procedural language for writing SQL functions in Python. We’ll also touch on advanced use cases, including embedding the Python interpreter directly into a PostgreSQL extension for deeper integration.
By the end of this talk, you’ll understand the capabilities, limitations, and gotchas of Python-powered extensions in each system—and how to choose the right tool depending on your use case, whether you’re analyzing data, building pipelines, or hacking on your own database.
DataBallPy is an open-source Python package that quickly starts your analysis of a football-related question. In the current talk, we will introduce the core features and functionalities of DataBallPy using code examples with compelling visualisations. The second part of the talk will showcase a practical example of how the Royal Belgian Football Association (RBFA) has used components of DataBallPy to analyse the effectiveness and efficiency of pressuring the opponent in over 200 games. Taken together, this talk will give you a clear starting point of how to start answering your football-related questions.

Python is the language of choice for anything to do with AI and ML. While that has made it easy to write code for one machine, it's much more difficult to run workloads across clusters of thousands of nodes. Ray allows you to do just that. I'll demonstrate how to implement this open source tool with a few lines of code. As a demo project, I'll show how I built a RAG for the Wheel of Time series.
Companies today are hungry for external data to stay competitive, but actually getting and making sense of that data isn’t easy. Standard web scraping often produces messy or incomplete results, and modern anti-bot systems make reliable collection even tougher.
In this talk, I’ll share how pairing Python’s scraping frameworks (like Scrapy, Playwright, and Selenium) with AI/ML can turn raw, unstructured data into clear, actionable insights.
We’ll look at:
1) How to build scrapers that still work in 2025.
2) Ways to use AI to automatically clean, enrich, and classify data.
3) Real-world applications of sentiment analysis for reviews and social media.
4) Case studies showing how SMEs have used these pipelines to sharpen marketing and product strategies.
By the end, you’ll see how to design pipelines that don’t just gather data, but deliver real strategic value. The session will focus on practical Python tools, scalable deployment (Airflow, Kubernetes, cloud platforms), and key lessons learned from hands-on projects at the intersection of scraping and AI.

Agentic frameworks make it easy to build and deploy compelling demos. But building robust systems that use LLMs is difficult because of inherent environmental non-determinism. Each user is different, each request is different; the very flexibility that makes LLMs feel magical in-the-small also makes agents difficult to wrangle in-the-large.
Developers who have built large agentic-like systems know the pain. Exceptional cases multiply, prompt libraries grow, instructions are co-mingled with user input. After a few iterations, an elegant agent evolves into a big ball of mud.
This hands-on tutorial introduces participants to Mellea, an open-source Python library for writing structured generative programs. Mellea puts the developer back in control by providing the building blocks needed to circumscribe, control, and mediate essential non-determinism.
In this 90 minute tutorial we'll get anyone with some basic Python and Command Line skills up and running with their own 100% laptop based set of LLMs, and explain some successful patterns for leveraging LLMs in a data analysis environment. We'll also highlight pit-falls waiting to catch you out, and encourage you that your pre-GenAI analytics skills are still relevant today and likely will be for the foreseeable future by demonstrating the limits of LLMs for data analysis tasks.
Learn to build practical LLM agents using LlamaBot and Marimo notebooks. This hands-on tutorial teaches the most important lesson in agent development: start with workflows, not technology.
We'll build a complete back-office automation system through three agents: a receipt processor that extracts data from PDFs, an invoice writer that generates documents, and a coordinator that orchestrates both. This demonstrates the fundamental pattern for agent systems—map your boring workflows first, build focused agents for specific tasks, then compose them so agents can use other agents as tools.
By the end, you'll understand how to identify workflows worth automating, build agents with decision-making loops, compose agents into larger systems, and integrate them into your own work. You'll leave with working code and confidence to automate repetitive tasks.
Prerequisites: Intermediate Python, familiarity with APIs, basic LLM understanding. Participants should have Ollama and models installed beforehand (setup instructions provided).
Materials: GitHub repository with Marimo notebooks. Setup uses Pixi for dependency management.

Unlocking the full potential of AI starts with your data, but real-world documents come in countless formats and levels of complexity. This session will give you hands-on experience with Docling, an open-source Python library designed to convert complex documents into AI-ready formats. Learn how Docling simplifies document processing, enabling you to efficiently harness all your data for downstream AI and analytics applications.
PubMed is a free search interface for biomedical literature, including citations and abstracts from many life science scientific journals. It is maintained by the National Library of Medicine at the NIH. Yet, most users only interact with it through simple keyword searches. In this hands-on tutorial, we will introduce PubMed as a data source for intelligent biomedical research assistants — and build a Health Research AI Agent using modern agentic AI frameworks such as LangChain, LangGraph, and Model Context Protocol (MCP) with minimum hardware requirements and no key tokens. To ensure compatibility, the agent will run in a Docker container which will host all necessary elements.
Participants will learn how to connect language models to structured biomedical knowledge, design context-aware queries, and containerize the entire system using Docker for maximum portability. By the end, attendees will have a working prototype that can read and reason over PubMed abstracts, summarize findings according to a semantic similarity engine, and assist with literature exploration — all running locally on modest hardware.
Expected Audience: Enthusiasts, researchers, and data scientists interested in AI agents, biomedical text mining, or practical LLM integration. Prior Knowledge: Python and Docker familiarity; no biomedical background required. Minimum Hardware Requirements: 8GB RAM (+16GB recommended), 30GB disk space, Docker pre-installed. MacOS, Windows, Linux. Key Takeaway: How to build a lightweight, reproducible research agent that combines open biomedical data with modern agentic AI frameworks.
We'll explore best practices for writing CUDA kernels using Python, empowering developers to harness the full potential of GPU acceleration. Gain a clear understanding of the structure and functionality of CUDA kernels, learning how to effectively implement them within Python applications.