Many companies are trying to solve the challenges of ingesting transactional data in Data lake and dealing with late-arriving updates and deletes.
To address this at Swiggy, we have built CDC(Change Data Capture) system, an incremental processing framework to power all business-critical data pipelines at low latency and high efficiency.
It offers:
Freshness: It operates in near real-time with configurable latency requirements.
Performance: Optimized read and write performance with tuned compaction parameters and partitions and delta table optimization.
Consistency: It supports reconciliation based on transaction types. Basically applying insert, update, and delete on existing data.
To implement this system, AWS DMS helped us with initial bootstrapping and CDC replication for Mysql sources. AWS Lambda and DynamoDB streams helped us to solve the bootstrapping and CDC replication for DynamoDB source.
After setting up the bootstrap and cdc replication process we have used Databricks delta merge to reconcile the data based on the transaction types.
To support the merge we have implemented supporting features -
* Deduplicating multiple mutations of the same record using log offset and time stamp.
* Adding optimal partition of the data set.
* Infer schema and apply proper schema evolutions(Backward compatible schema)
* We have extended the delta table snapshot generation technique to create a consistent partition for partitioned delta tables.
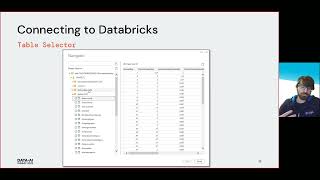
FInally to read the data we are using Spark sql with Hive metastore and Snowflake.
Delta tables read with Spark sql have implicit support for hive metastore.
We have built our own implementation of the snowflake sync process to create external, internal tables and materialized views on Snowflake.
Stats:
500m CDC logs/day
600+ tables
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/data...
Instagram: https://www.instagram.com/databricksinc/