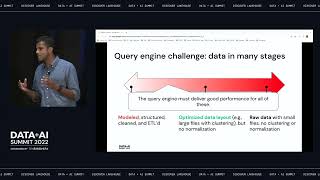
Presto was originally designed to run interactive queries against data warehouses, but now it has evolved into a unified SQL engine on top of open data lake analytics for both interactive and batch workloads. However, Presto doesn't scale to very large and complex batch pipelines. Presto Unlimited was designed to address such scalability challenges but it didn’t fully solve fault tolerance, isolation, and resource management.
Spark is the tool of choice across the industry for running large scale complex batch ETL pipelines. This motivated the development of Presto On Spark. Presto on Spark runs Presto as a library that is submitted with spark-submit to a Spark cluster. It leverages Spark for scaling shuffle, worker execution, and resource management. It thereby eliminates any query conversion between interactive and batch use cases. This solution helps enable a performant and scalable platform with seamless end-to-end experience to explore and process data.
Many analysts at Intuit use Presto to explore data in the Data Lake/S3 and use Spark for batch processing. These analysts would earlier spend several hours converting these exploration SQLs written for Presto to Spark SQL to operationalize/schedule them as data pipelines. Presto On Spark is now used by analysts at Intuit to run thousands of critical jobs. No query conversion is required here, improved analysts' productivity and empowered them to deliver insights at high speed.
Benefits from session: Attendees will learn about Presto On Spark architecture Attendees will learn when To Use Spark's Execution Engine With Presto Attendees will learn how Intuit runs thousands of presto jobs daily leveraging databricks platform which they can apply to their own work
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/