Join us for an in-depth Ask Me Anything (AMA) on how Rust is revolutionizing Lakehouse formats like Delta Lake and Apache Iceberg through projects like delta-rs and iceberg-rs! Discover how Rust’s memory safety, zero-cost abstractions and fearless concurrency unlock faster development and higher-performance data operations. Whether you’re a data engineer, Rustacean or Lakehouse enthusiast, bring your questions on how Rust is shaping the future of open table formats!
 talk-data.com
talk-data.com
Topic
Delta
Delta Lake
data_lake
acid_transactions
time_travel
file_format
storage
347
tagged
Activity Trend
117
peak/qtr
2020-Q1
2026-Q2
Top Events
Databricks DATA + AI Summit 2023
119
Data + AI Summit 2025
117
Data Engineering Podcast
50
O'Reilly Data Engineering Books
19
Moody's Talks - Inside Economics
7
Building Delta Live Tables (DLTs) Only with SQL
4
Big Data LDN 2025
4
DATA MINER Big Data Europe Conference 2020
2
Big Data LDN 2024
2
Data Engineering Central Podcast
2
O'Reilly Data Science Books
2
How Music Charts
2

In this presentation, we’ll dive into the power of Liquid Clustering—an innovative, out-of-the-box solution that automatically tunes your data layout to scale effortlessly with your datasets. You’ll get a deep look at how Liquid Clustering works, along with real-world examples of customers leveraging it to unlock blazing-fast query performance on petabyte-scale datasets. We’ll also give you an exciting sneak peek into the roadmap ahead, with upcoming features and enhancements to come.

by
Matthew Houser
(Tealium)
,
Bob Pisani
(Addepar)
,
Adrian Bolosan
(Databricks)
,
Davis Matson
(Health Catalyst)
Join us to discover how leading tech companies accelerate growth using open ecosystems and built-on solutions to foster collaboration, accelerate innovation and create scalable data products. This session will explore how organizations use Databricks to securely share data, integrate with partners and enable teams to build impactful applications powered by AI and analytics. Topics include: Using Delta Sharing for secure, real-time data collaboration across teams and partners Embedding analytics and creating marketplaces to extend product capabilities Building with open standards and governance frameworks to ensure compliance without sacrificing agility Hear real-world examples of how open ecosystems empower organizations to widen the aperture on collaboration, driving better business outcomes. Walk away with insights into how open data sharing and built-on solutions can help your teams innovate faster at scale.

Open table formats are evolving quickly. In this session, we’ll explore the latest features of Delta Lake and Apache Iceberg™ , including a look at the emerging Iceberg v3 specification. Join us to learn about what’s driving format innovation, how interoperability is becoming real, and what it means for the future of data architecture.

In today's fast-paced digital landscape, context is everything. Decisions made without understanding the full picture often lead to missed opportunities or suboptimal outcomes. Powering contextualized intelligence is at the heart of MathCo’s proprietary platform — NucliOS, a Databricks-Native Platform leveraging Databricks features across the data lifecycle like Unity Catalog, Delta Lake, MLFlow, and Notebooks. Join this session to discover how NucliOS reimagines the data journey end-to-end: from data discovery and preparation to advanced analysis, dynamic visualization, and scenario modeling, all the way through to operationalizing insights within business workflows. At every step, intelligent agents act in concert, accelerating innovation and delivering speed at scale.

Matei is a legend of open source: he started the Apache Spark project in 2009, co-founded Databricks, and worked on other widely used data and AI software, including MLflow, Delta Lake, and Dolly. His most recent research is about combining large language models (LLMs) with external data sources, such as search systems, and improving their efficiency and result quality. This will be a conversation coverering the latest and greatest of UC, Data Intelligence, AI Governance, and more.

Hear more on the latest in data collaboration, which is paramount to unlocking business success. Delta Sharing is an open-source approach to share and govern data, AI models, dashboards, and notebooks across clouds and platforms - without the costly need for replication. Databricks Clean Rooms provide safe hosting environments for data collaboration across companies, also without the costly duplication of data. And the Databricks Marketplace is the open marketplace for all your data, analytics, and AI needs.

Traditional streaming works great when your data source is append-only, but what if your data source includes updates and deletes? At 84.51 we used Lakeflow Declarative Pipelines and Delta Lake to build a streaming data flow that consumes inserts, updates and deletes while still taking advantage of streaming checkpoints. We combined this flow with a materialized view and Enzyme incremental refresh for a low-code, efficient and robust end-to-end data flow.We process around 8 million sales transactions each day with 80 million items purchased. This flow not only handles new transactions but also handles updates to previous transactions.Join us to learn how 84.51 combined change data feed, data streaming and materialized views to deliver a “better together” solution.84.51 is a retail insights, media & marketing company. We use first-party retail data from 60 million households sourced through a loyalty card program to drive Kroger’s customer-centric journey.
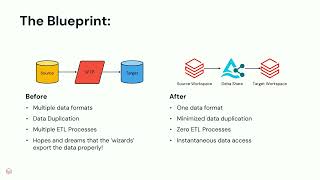
Collaboration is redefining efficiency in insurance. This session explores how technologies such as Databricks Delta Sharing, secure data clean rooms, and data marketplaces are empowering insurers to securely share and analyze data across organizational boundaries—without exposing sensitive information. Discover how these solutions streamline operations, enhance risk modeling with real-time data integration, and enable the creation of tailored products through multi-party collaboration. Learn how insurers are leveraging these collaborative data ecosystems to reduce costs, drive innovation, and deliver better customer outcomes, all while maintaining strong privacy and governance standards. Join us to see how embracing collaborative frameworks is helping insurers operate smarter, faster, and more efficiently.

Bagelcode, a leader in the social casino industry, has utilized Databricks since 2018 and manages over 10,000 tables via Hive Metastore. In 2024, we embarked on a transformative journey to resolve inefficiencies and unlock new capabilities. Over five months, we redesigned ETL pipelines with Delta Lake, optimized partitioned table logs and executed a seamless migration with minimal disruption. This effort improved governance, simplified management and unlocked Unity Catalog’s advanced features. Post-migration, we integrated the Genie Room with Slack to enable natural language queries, accelerating decision-making and operational efficiency. Additionally, a lineage-powered internal tool allowed us to quickly identify and resolve issues like backfill needs or data contamination. Unity Catalog has revolutionized our data ecosystem, elevating governance and innovation. Join us to learn how Bagelcode unlocked its data’s full potential and discover strategies for your own transformation.

Unlock the full potential of Delta Lake, the open-source storage framework for Apache Spark, with this session focused on its latest and most impactful features. Discover how capabilities like Time Travel, Column Mapping, Deletion Vectors, Liquid Clustering, UniForm interoperability, and Change Data Feed (CDF) can transform your data architecture. Learn not just what these features do, but when and how to use them to maximize performance, simplify data management, and enable advanced analytics across your lakehouse environment.

Redox & Databricks direct integration can streamline your interoperability workflows from responding in record time to preauthorization requests to letting attending physicians know about a change in risk for sepsis and readmission in near real time from ADTs. Data engineers will learn how to create fully-streaming ETL pipelines for ingesting, parsing and acting on insights from Redox FHIR bundles delivered directly to Unity Catalog volumes. Once available in the Lakehouse, AI/BI Dashboards and Agentic Frameworks help write FHIR messages back to Redox for direct push down to EMR systems. Parsing FHIR bundle resources has never been easier with SQL combined with the new VARIANT data type in Delta and streaming table creation against Serverless DBSQL Warehouses. We'll also use Databricks accelerators dbignite and redoxwrite for writing and posting FHIR bundles back to Redox integrated EMRs and we'll extend AI/BI with Unity Catalog SQL UDFs and the Redox API for use in Genie.

In the competitive gaming industry, understanding player behavior is key to delivering engaging experiences. Supercell, creators of Clash of Clans and Brawl Stars, faced challenges with fragmented data and limited visibility into user journeys. To address this, they partnered with Snowplow and Databricks to build a scalable, privacy-compliant data platform for real-time insights. By leveraging Snowplow’s behavioral data collection and Databricks’ Lakehouse architecture, Supercell achieved: Cross-platform data unification: A unified view of player actions across web, mobile and in-game Real-time analytics: Streaming event data into Delta Lake for dynamic game balancing and engagement Scalable infrastructure: Supporting terabytes of data during launches and live events AI & ML use cases: Churn prediction and personalized in-game recommendations This session explores Supercell’s data journey and AI-driven player engagement strategies.

Accurate charge time estimation is key to vehicle performance and user experience. We developed a scalable ML model that enhances real-time charge predictions in vehicle controls. Traditional rule-based methods struggle with dynamic factors like environment, vehicle state, and charging conditions. Our adaptive ML solution improves accuracy by 10%. We use Unity Catalog for data governance, Delta Tables for storage, and Liquid Clustering for data layout. Job schedulers manage data processing, while AutoML accelerates model selection. MLflow streamlines tracking, versioning, and deployment. A dedicated serving endpoint enables A/B testing and real-time insights. As our data ecosystem grew, scalability became critical. Our flexible ML framework was integrated into vehicle control systems within months. With live accuracy tracking and software-driven blending, we support 50,000+ weekly charge sessions, improving energy management and user experience.

Learn how Confluent simplifies real-time streaming of your SAP data into AI-ready Delta tables on Databricks. In this session, you'll see how Confluent’s fully managed data streaming platform—with unified Apache Kafka® and Apache Flink®—connects data from SAP S/4HANA, ECC, and 120+ other sources to enable easy development of trusted, real-time data products that fuel highly contextualized AI and analytics. With Tableflow, you can represent Kafka topics as Delta tables in just a few clicks—eliminating brittle batch jobs and custom pipelines. You’ll see a product demo showcasing how Confluent unites your SAP and Databricks environments to unlock ERP-fueled AI, all while reducing the total cost of ownership (TCO) for data streaming by up to 60%.

Change data feeds are a common tool for synchronizing changes between tables and performing data processing in a scalable fashion. Serverless architectures offer a compelling solution for organizations looking to avoid the complexity of managing infrastructure. But how can you bring CDFs into a serverless environment? In this session, we'll explore how to integrate Change Data Feeds into serverless architectures using Delta-rs and Delta-kernel-rs—open-source projects that allow you to read Delta tables and their change data feeds in Rust or Python. We’ll demonstrate how to use these tools with Lakestore’s serverless platform to easily stream and process changes. You’ll learn how to: Leverage Delta tables and CDFs in serverless environments Utilize Databricks and Unity Catalog without needing Apache Spark

PySpark supports many data sources out of the box, such as Apache Kafka, JDBC, ODBC, Delta Lake, etc. However, some older systems, such as systems that use JMS protocol, are not supported by default and require considerable extra work for developers to read from them. One such example is ActiveMQ for streaming. Traditionally, users of ActiveMQ have to use a middle-man in order to read the stream with Spark (such as writing to a MySQL DB using Java code and reading that table with Spark JDBC). With PySpark 4.0’s custom data sources (supported in DBR 15.3+) we are able to cut out the middle-man processing using batch or Spark Streaming and consume the queues directly from PySpark, saving developers considerable time and complexity in getting source data into your Delta Lake and governed by Unity Catalog and orchestrated with Databricks Workflows.

Step into the world of Disney Streaming as we unveil the creation of our Foundational Medallion, a cornerstone in our architecture that redefines how we manage data at scale. In this session, we'll explore how we tackled the multi-faceted challenges of building a consistent, self-service surrogate key architecture — a foundational dataset for every ingested stream powering Disney Streaming's data-driven decisions. Learn how we streamlined our architecture and unlocked new efficiencies by leveraging cutting-edge Databricks features such as liquid clustering, Photon with dynamic file pruning, Delta's identity column, Unity Catalog and more — transforming our implementation into a simpler, more scalable solution. Join us on this thrilling journey as we navigate the twists and turns of designing and implementing a new Medallion at scale — the very heartbeat of our streaming business!

In a world where data collaboration is essential but trust is scarce, Databricks Clean Rooms delivers a game-changing model: no data shared, all value gained. Discover how data providers can unlock new revenue streams by launching subscription-based analytics and “Built-on-Databricks” services that run on customer data — without exposing raw data or violating compliance. Clean Rooms integrates Unity Catalog’s governance, Delta Sharing’s secure exchange and serverless compute to enable true multi-party collaboration — without moving data. See how privacy-preserving models like fraud detection, clinical analytics and ad measurement become scalable, productizable and monetizable across industries. Walk away with a proven pattern to productize analytics, preserve compliance and turn trustless collaboration into recurring revenue.

Coinbase leverages Databricks to scale ML on blockchain data, turning vast transaction networks into actionable insights. This session explores how Databricks’ scalable infrastructure, powered by Delta Lake, enables real-time processing for ML applications like NFT floor price predictions. We’ll show how GraphFrames helps us analyze billion-node transaction graphs (e.g., Bitcoin) for clustering and fraud detection, uncovering structural patterns in blockchain data. But traditional graph analytics has limits. We’ll go further with Graph Neural Networks (GNNs) using Kumo AI, which learn from the transaction network itself rather than relying on hand-engineered features. By encoding relationships directly into the model, GNNs adapt to new fraud tactics, capturing subtle relationships that evolve over time. Join us to see how Coinbase is advancing blockchain ML with Databricks and deep learning on graphs.