🌟 Session Overview 🌟
Session Name: Open Source Entity Resolution - Needs and Challenges
Speaker: Sonal Goyal
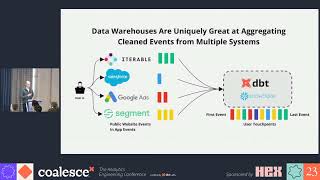
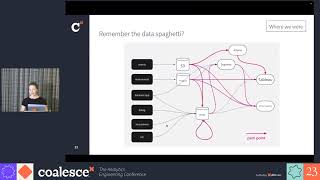
Session Description: Real world data contains multiple records belonging to the same customer. These records can be in single or multiple systems and they have variations across fields, which makes it hard to combine them together, especially with growing data volumes. This hurts customer analytics - establishing lifetime value, loyalty programs, or marketing channels is impossible when the base data is not linked. No AI algorithm for segmentation can produce the right results when there are multiple copies of the same customer lurking in the data. No warehouse can live up to its promise if the dimension tables have duplicates.
With a modern data stack and DataOps, we have established patterns for E and L in ELT for building data warehouses, datalakes and deltalakes. However, the T - getting data ready for analytics still needs a lot of effort. Modern tools like dbt are actively and successfully addressing this. What is also needed is a quick and scalable way to resolve entities to build the single source of truth of core business entities post Extraction and pre or post Loading.
This session would cover the problem of Entity Resolution, its practical applications and challenges in building an entity resolution system. It will also cover Zingg - an Open Source Framework for building Entity Resolution systems. (https://github.com/zinggAI/zingg/)
🚀 About Big Data and RPA 2024 🚀
Unlock the future of innovation and automation at Big Data & RPA Conference Europe 2024! 🌟 This unique event brings together the brightest minds in big data, machine learning, AI, and robotic process automation to explore cutting-edge solutions and trends shaping the tech landscape.
Perfect for data engineers, analysts, RPA developers, and business leaders, the conference offers dual insights into the power of data-driven strategies and intelligent automation. 🚀
Gain practical knowledge on topics like hyperautomation, AI integration, advanced analytics, and workflow optimization while networking with global experts.
Don’t miss this exclusive opportunity to expand your expertise and revolutionize your processes—all from the comfort of your home! 📊🤖✨
📅 Yearly Conferences: Curious about the evolution of QA? Check out our archive of past Big Data & RPA sessions. Watch the strategies and technologies evolve in our videos! 🚀
🔗 Find Other Years' Videos:
2023 Big Data Conference Europe
https://www.youtube.com/playlist?list=PLqYhGsQ9iSEpb_oyAsg67PhpbrkCC59_g
2022 Big Data Conference Europe Online
https://www.youtube.com/playlist?list=PLqYhGsQ9iSEryAOjmvdiaXTfjCg5j3HhT
2021 Big Data Conference Europe Online
https://www.youtube.com/playlist?list=PLqYhGsQ9iSEqHwbQoWEXEJALFLKVDRXiP
💡 Stay Connected & Updated 💡
Don’t miss out on any updates or upcoming event information from Big Data & RPA Conference Europe. Follow us on our social media channels and visit our website to stay in the loop!
🌐 Website: https://bigdataconference.eu/, https://rpaconference.eu/
👤 Facebook: https://www.facebook.com/bigdataconf, https://www.facebook.com/rpaeurope/
🐦 Twitter: @BigDataConfEU, @europe_rpa
🔗 LinkedIn: https://www.linkedin.com/company/73234449/admin/dashboard/, https://www.linkedin.com/company/75464753/admin/dashboard/
🎥 YouTube: http://www.youtube.com/@DATAMINERLT