On today’s episode, we’re joined by Lee Blakemore, Chief Executive Officer of Introhive, the leading Client Intelligence Platform. We talk about: Building a culture that’s data-oriented & encouraging autonomy Resisting unproductive fads, such as pushing for metrics that don't correlate to profit & revenueBeing pragmatic – without killing opportunitiesAmusing anecdotes about the early cloud daysIf startups should invest more in marketing or sales
 talk-data.com
talk-data.com
Topic
SaaS
Software as a Service (SaaS)
cloud_computing
software_delivery
subscription
310
tagged
Activity Trend
23
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
107
SaaS Scaled - Interviews about SaaS Startups, Analytics, & Operations
69
The Pragmatic Engineer
19
Experiencing Data w/ Brian T. O’Neill (AI & data product management leadership—powered by UX design)
14
DataFramed
8
Google Cloud Next '24
7
Microsoft Ignite 2025
6
Google Cloud Next '25
6
O'Reilly Data Engineering Books
6
Data + AI Summit 2025
5
Data Product Management in Action: The Practitioner's Podcast
5
Databricks DATA + AI Summit 2023
5
Summary
Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data projects are notoriously complex. With multiple stakeholders to manage across varying backgrounds and toolchains even simple reports can become unwieldy to maintain. Miro is your single pane of glass where everyone can discover, track, and collaborate on your organization's data. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro. Your first three Miro boards are free when you sign up today at dataengineeringpodcast.com/miro. That’s three free boards at dataengineeringpodcast.com/miro. Your host is Tobias Macey and today I'm interviewing Tanya Bragin about her views on the database products market
Interview
Introduction How did you get involved in the area of data management? What are the aspects of the database market that keep you interested as a VP of product?
How have your experiences at Elastic informed your current work at Clickhouse?
What are the main product categories for databases today?
What are the industry trends that have the most impact on the development and growth of different product categories? Which categories do you see growing the fastest?
When a team is selecting a database technology for a given task, what are the types of questions that they should be asking? Transactional engines like Postgres, SQL Server, Oracle, etc. were long used
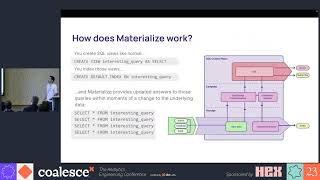
Traditional data warehouses excel at churning through terabytes of data for historical analysis. But for real-time, business-critical use cases, traditional data warehouses can’t produce results fast enough—and they still rack up a huge bill in the process.
So when Ramp’s data engineering team needed to serve complex analytics queries on the critical path of their production application, they knew they needed a new tool for the job. Enter Materialize, the first operational data warehouse. Like a traditional data warehouse, Materialize centralizes the data from all of a business’s production systems, from application databases to SaaS tools. But unlike a traditional data warehouse, Materialize enables taking immediate and automatic action when that data changes. Queries that once took hours or minutes to run are up-to-date in Materialize within seconds.
This talk presents how Ramp is unlocking new real-time use cases using Materialize as their operational data warehouse. The best part? The team still uses dbt for data modeling and deployment management, just like they are able to with their traditional batch workloads.
Speakers: Nikhil Benesch, CTO, Materialize; Ryan Delgado, Staff Software Engineer, Data Platform, Ramp
Register for Coalesce at https://coalesce.getdbt.com
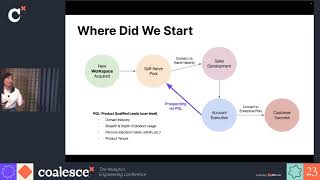
Prioritizing the right sales opportunities is pivotal for any SaaS company's growth, but what happens after your initial success? Jessica Zhang, Data Science Manager at Notion, traces Notion's footsteps from its foundational days to its present-day lead scoring techniques. Learn how modern tools like dbt, Census, and Snowflake enable the Notion team to iterate quickly. More than a journey, this session is a lesson on evolving a data science model in response to changing business assumptions and fresh user insights.
Speakers: Jessica Zhang, Data Science Manager, Notion; Jeff Sloan, Sr. Data Community Advocate, Census
Register for Coalesce at https://coalesce.getdbt.com
Summary
The primary application of data has moved beyond analytics. With the broader audience comes the need to present data in a more approachable format. This has led to the broad adoption of data products being the delivery mechanism for information. In this episode Ranjith Raghunath shares his thoughts on how to build a strategy for the development, delivery, and evolution of data products.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! As more people start using AI for projects, two things are clear: It’s a rapidly advancing field, but it’s tough to navigate. How can you get the best results for your use case? Instead of being subjected to a bunch of buzzword bingo, hear directly from pioneers in the developer and data science space on how they use graph tech to build AI-powered apps. . Attend the dev and ML talks at NODES 2023, a free online conference on October 26 featuring some of the brightest minds in tech. Check out the agenda and register today at Neo4j.com/NODES. This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Ranjith Raghunath about tactical elements of a data product strategy
Interview
Introduction How did you get involved in the area of data management? Can you describe what is encompassed by the idea of a data product strategy?
Which roles in an organization need to be involved in the planning and implementation of that strategy?
order of operations:
strategy -> platform design -> implementation/adoption platform implementation -> product strategy -> interface development
managing grain of data in products team organization to support product development/deployment customer communications - what questions to ask? requirements gathering, helping to understand "the art of the possible" What are the most interesting, innovative, or unexpected ways that you have seen organizations approach data product strategies? What are the most interesting, unexpected, or challenging lessons that you have learned while working on
Summary
Building streaming applications has gotten substantially easier over the past several years. Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. In this episode Eric Sammer discusses why more companies are including real-time capabilities in their products and the ways that Decodable makes it faster and easier.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! As more people start using AI for projects, two things are clear: It’s a rapidly advancing field, but it’s tough to navigate. How can you get the best results for your use case? Instead of being subjected to a bunch of buzzword bingo, hear directly from pioneers in the developer and data science space on how they use graph tech to build AI-powered apps. . Attend the dev and ML talks at NODES 2023, a free online conference on October 26 featuring some of the brightest minds in tech. Check out the agenda and register today at Neo4j.com/NODES. Your host is Tobias Macey and today I'm interviewing Eric Sammer about starting your stream processing journey with Decodable
Interview
Introduction How did you get involved in the area of data management? Can you describe what Decodable is and the story behind it?
What are the notable changes to the Decodable platform since we last spoke? (October 2021) What are the industry shifts that have influenced the product direction?
What are the problems that customers are trying to solve when they come to Decodable? When you launched your focus was on SQL transformations of streaming data. What was the process for adding full Java support in addition to SQL? What are the developer experience challenges that are particular to working with streaming data?
How have you worked to address that in the Decodable platform and interfaces?
As you evolve the technical and product direction, what is your heuristic for balancing the unification of interfaces and system integration against the ability to swap different components or interfaces as new technologies are introduced? What are the most interesting, innovative, or unexpected ways that you have seen Decodable used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Decodable? When is Decodable the wrong choice? What do you have planned for the future of Decodable?
Contact Info
esammer on GitHub LinkedIn
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Decodable
Podcast Episode
Understanding the Apache Flink Journey Flink
Podcast Episode
Debezium
Podcast Episode
Kafka Redpanda
Podcast Episode
Kinesis PostgreSQL
Podcast Episode
Snowflake
Podcast Episode
Databricks Startree Pinot
Podcast Episode
Rockset
Podcast Episode
Druid InfluxDB Samza Storm Pulsar
Podcast Episode
ksqlDB
Podcast Episode
dbt GitHub Actions Airbyte Singer Splunk Outbox Pattern
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Neo4J: 
NODES 2023 is a free online conference focused on graph-driven innovations with content for all skill levels. Its 24 hours are packed with 90 interactive technical sessions from top developers and data scientists across the world covering a broad range of topics and use cases. The event tracks: - Intelligent Applications: APIs, Libraries, and Frameworks – Tools and best practices for creating graph-powered applications and APIs with any software stack and programming language, including Java, Python, and JavaScript - Machine Learning and AI – How graph technology provides context for your data and enhances the accuracy of your AI and ML projects (e.g.: graph neural networks, responsible AI) - Visualization: Tools, Techniques, and Best Practices – Techniques and tools for exploring hidden and unknown patterns in your data and presenting complex relationships (knowledge graphs, ethical data practices, and data representation)
Don’t miss your chance to hear about the latest graph-powered implementations and best practices for free on October 26 at NODES 2023. Go to Neo4j.com/NODES today to see the full agenda and register!Rudderstack: 
Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstackMaterialize: 
You shouldn't have to throw away the database to build with fast-changing data. Keep the familiar SQL, keep the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date.
That is Materialize, the only true SQL streaming database built from the ground up to meet the needs of modern data products: Fresh, Correct, Scalable — all in a familiar SQL UI. Built on Timely Dataflow and Differential Dataflow, open source frameworks created by cofounder Frank McSherry at Microsoft Research, Materialize is trusted by data and engineering teams at Ramp, Pluralsight, Onward and more to build real-time data products without the cost, complexity, and development time of stream processing.
Go to materialize.com today and get 2 weeks free!Datafold: 
This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare…
Summary
The insurance industry is notoriously opaque and hard to navigate. Max Cho found that fact frustrating enough that he decided to build a business of making policy selection more navigable. In this episode he shares his journey of data collection and analysis and the challenges of automating an intentionally manual industry.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold As more people start using AI for projects, two things are clear: It’s a rapidly advancing field, but it’s tough to navigate. How can you get the best results for your use case? Instead of being subjected to a bunch of buzzword bingo, hear directly from pioneers in the developer and data science space on how they use graph tech to build AI-powered apps. . Attend the dev and ML talks at NODES 2023, a free online conference on October 26 featuring some of the brightest minds in tech. Check out the agenda and register today at Neo4j.com/NODES. You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Max Cho about the wild world of insurance companies and the challenges of collecting quality data for this opaque industry
Interview
Introduction How did you get involved in the area of data management? Can you describe what CoverageCat is and the story behind it? What are the different sources of data that you work with?
What are the most challenging aspects of collecting that data? Can you describe the formats and characteristics (3 Vs) of that data?
What are some of the ways that the operational model of insurance companies have contributed to its opacity as an industry from a data perspective? Can you describe how you have architected your data platform?
How have the design and goals changed since you first started working on it? What are you optimizing for in your selection and implementation process?
What are the sharp edges/weak points that you worry about in your existing data flows?
How do you guard against those flaws in your day-to-day operations?
What are the
On today’s episode, we’re joined by Devvret Rishi, CEO & Co-Founder at Predibase, the low-code AI platform for developers. We talk about:
Progress towards democratization of LLM & AITackling the main challenges of machine learningWill LLM apps replace or enhance SaaS apps?Insights from Predibase’s survey of 150 executives, data scientists, & developersWhy people will stop trying to use a cannon when they need a scalpel
Summary
Artificial intelligence applications require substantial high quality data, which is provided through ETL pipelines. Now that AI has reached the level of sophistication seen in the various generative models it is being used to build new ETL workflows. In this episode Jay Mishra shares his experiences and insights building ETL pipelines with the help of generative AI.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! As more people start using AI for projects, two things are clear: It’s a rapidly advancing field, but it’s tough to navigate. How can you get the best results for your use case? Instead of being subjected to a bunch of buzzword bingo, hear directly from pioneers in the developer and data science space on how they use graph tech to build AI-powered apps. . Attend the dev and ML talks at NODES 2023, a free online conference on October 26 featuring some of the brightest minds in tech. Check out the agenda and register at Neo4j.com/NODES. Your host is Tobias Macey and today I'm interviewing Jay Mishra about the applications for generative AI in the ETL process
Interview
Introduction How did you get involved in the area of data management? What are the different aspects/types of ETL that you are seeing generative AI applied to?
What kind of impact are you seeing in terms of time spent/quality of output/etc.?
What kinds of projects are most likely to benefit from the application of generative AI? Can you describe what a typical workflow of using AI to build ETL workflows looks like?
What are some of the types of errors that you are likely to experience from the AI? Once the pipeline is defined, what does the ongoing maintenance look like? Is the AI required to operate within the pipeline in perpetuity?
For individuals/teams/organizations who are experimenting with AI in their data engineering workflows, what are the concerns/questions that they are trying to address? What are the most interesting, innovative, or unexpected w
Summary
The rapid growth of machine learning, especially large language models, have led to a commensurate growth in the need to store and compare vectors. In this episode Louis Brandy discusses the applications for vector search capabilities both in and outside of AI, as well as the challenges of maintaining real-time indexes of vector data.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! If you’re a data person, you probably have to jump between different tools to run queries, build visualizations, write Python, and send around a lot of spreadsheets and CSV files. Hex brings everything together. Its powerful notebook UI lets you analyze data in SQL, Python, or no-code, in any combination, and work together with live multiplayer and version control. And now, Hex’s magical AI tools can generate queries and code, create visualizations, and even kickstart a whole analysis for you – all from natural language prompts. It’s like having an analytics co-pilot built right into where you’re already doing your work. Then, when you’re ready to share, you can use Hex’s drag-and-drop app builder to configure beautiful reports or dashboards that anyone can use. Join the hundreds of data teams like Notion, AllTrails, Loom, Mixpanel and Algolia using Hex every day to make their work more impactful. Sign up today at dataengineeringpodcast.com/hex to get a 30-day free trial of the Hex Team plan! Your host is Tobias Macey and today I'm interviewing Louis Brandy about building vector indexes in real-time for analytics and AI applications
Interview
Introduction How did you get involved in the area of data management? Can you describe what vector search is and how it differs from other search technologies?
What are the technical challenges related to providing vector search? What are the applications for vector search that merit the added complexity?
Vector databases have been gaining a lot of attention recently with the proliferation of LLM applicati
Summary
A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. In this episode Brian Platz explains how JSON-LD can be used as a shared representation of linked data for building semantic data products.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! If you’re a data person, you probably have to jump between different tools to run queries, build visualizations, write Python, and send around a lot of spreadsheets and CSV files. Hex brings everything together. Its powerful notebook UI lets you analyze data in SQL, Python, or no-code, in any combination, and work together with live multiplayer and version control. And now, Hex’s magical AI tools can generate queries and code, create visualizations, and even kickstart a whole analysis for you – all from natural language prompts. It’s like having an analytics co-pilot built right into where you’re already doing your work. Then, when you’re ready to share, you can use Hex’s drag-and-drop app builder to configure beautiful reports or dashboards that anyone can use. Join the hundreds of data teams like Notion, AllTrails, Loom, Mixpanel and Algolia using Hex every day to make their work more impactful. Sign up today at dataengineeringpodcast.com/hex to get a 30-day free trial of the Hex Team plan! Your host is Tobias Macey and today I'm interviewing Brian Platz about using JSON-LD for building linked-data products
Interview
Introduction How did you get involved in the area of data management? Can you describe what the term "linked data product" means and some examples of when you might build one?
What is the overlap between knowledge graphs and "linked data products"?
What is JSON-LD?
What are the domains in which it is typically used? How does it assist in developing linked data products?
what are the characterist
Summary
Data systems are inherently complex and often require integration of multiple technologies. Orchestrators are centralized utilities that control the execution and sequencing of interdependent operations. This offers a single location for managing visibility and error handling so that data platform engineers can manage complexity. In this episode Nick Schrock, creator of Dagster, shares his perspective on the state of data orchestration technology and its application to help inform its implementation in your environment.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm welcoming back Nick Schrock to talk about the state of the ecosystem for data orchestration
Interview
Introduction How did you get involved in the area of data management? Can you start by defining what data orchestration is and how it differs from other types of orchestration systems? (e.g. container orchestration, generalized workflow orchestration, etc.) What are the misconceptions about the applications of/need for/cost to implement data orchestration?
How do those challenges of customer education change across roles/personas?
Because of the multi-faceted nature of data in an organization, how does that influence the capabilities and interfaces that are needed in an orchestration engine? You have been working on Dagster for five years now. How have the requirements/adoption/application for orchestrators changed in that time? One of the challenges for any orchestration engine is to balance the need for robust and extensible core capabilities with a rich suite of integrations to the broader data ecosystem. What are the factors that you have seen make the most influence in driving adoption of a given engine? What are the most interesting, innovative, or unexpected ways that you have seen data orchestration implemented and/or used? What are the most interesting, unexpected, or challenging lessons that you have learned while working o
On today’s episode, we’re joined by Ben Johnson Founder, CEO of Particle41, a provider of software and product development solutions crafted by world-class app development, DevOps, and data science teams. We talk about:
What components the CTO owns in a SaaS companyOptimizing the efficiency of dev teamsHow much of the CTO role is internal vs. externalHow to interview & identify a great CTO candidate
Summary
Cloud data warehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. The challenge is that most of those options are complex to operate and exist in their own silo. The dlt project was created to eliminate overhead and bring data integration into your full control as a library component of your overall data system. In this episode Adrian Brudaru explains how it works, the benefits that it provides over other data integration solutions, and how you can start building pipelines today.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Adrian Brudaru about dlt, an open source python library for data loading
Interview
Introduction How did you get involved in the area of data management? Can you describe what dlt is and the story behind it?
What is the problem you want to solve with dlt? Who is the target audience?
The obvious comparison is with systems like Singer/Meltano/Airbyte in the open source space, or Fivetran/Matillion/etc. in the commercial space. What are the complexities or limitations of those tools that leave an opening for dlt? Can you describe how dlt is implemented? What are the benefits of building it in Python? How have the design and goals of the project changed since you first started working on it? How does that language choice influence the performance and scaling characteristics? What problems do users solve with dlt? What are the interfaces available for extending/customizing/integrating with dlt? Can you talk through the process of adding a new source/destination? What is the workflow for someone building a pipeline with dlt? How does the experience scale when supporting multiple connections? Given the limited scope of extract and load, and the composable design of dlt it seems like a purpose built companion to dbt (down to th
Summary
Data persistence is one of the most challenging aspects of computer systems. In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? In this episode Vignesh Ravichandran explains how his team at Cloudflare provides PostgreSQL as a service to their developers for low latency and high uptime services at global scale. This is an interesting and insightful look at pragmatic engineering for reliability and scale.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Vignesh Ravichandran about building an internal database as a service platform at Cloudflare
Interview
Introduction How did you get involved in the area of data management? Can you start by describing the different database workloads that you have at Cloudflare?
What are the different methods that you have used for managing database instances?
What are the requirements and constraints that you had to account for in designing your current system? Why Postgres? optimizations for Postgres
simplification from not supporting multiple engines
limitations in postgres that make multi-tenancy challenging scale of operation (data volume, request rate What are the most interesting, innovative, or unexpected ways that you have seen your DBaaS used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on your internal database platform? When is an internal database as a service the wrong choice? What do you have planned for the future of Postgres hosting at Cloudflare?
Contact Info
LinkedIn Website
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Mac
On today’s episode, we’re joined by Jason Kruger, President & Founder at Signature Analytics, a provider of expert-level accounting and business advisory solutions to small and middle-market businesses throughout Southern California and beyond.
We talk about: Accounting mistakes commonly made by SaaS foundersThe challenges of balancing CEO optimism with necessary pragmatismAreas successful SaaS CEOs spend the most time onThe collaborative process of developing KPIsThe trouble with viewing accounting as a necessary evil
Summary
Generative AI has unlocked a massive opportunity for content creation. There is also an unfulfilled need for experts to be able to share their knowledge and build communities. Illumidesk was built to take advantage of this intersection. In this episode Greg Werner explains how they are using generative AI as an assistive tool for creating educational material, as well as building a data driven experience for learners.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. Whether it’s real-time dashboarding and analytics, personalization and segmentation or automation and alerting, Materialize gives you the ability to work with fresh, correct, and scalable results — all in a familiar SQL interface. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free! Your host is Tobias Macey and today I'm interviewing Greg Werner about building IllumiDesk, a data-driven and AI powered online learning platform
Interview
Introduction How did you get involved in the area of data management? Can you describe what Illumidesk is and the story behind it? What are the challenges that educators and content creators face in developing and maintaining digital course materials for their target audiences? How are you leaning on data integrations and AI to reduce the initial time investment required to deliver courseware? What are the opportunities for collecting and collating learner interactions with the course materials to provide feedback to the instructors? What are some of the ways that you are incorporating pedagogical strategies into the measurement and evaluation methods that you use for reports? What are the different categories of insights that you need to provide across the different stakeholders/personas who are interacting with the platform and learning content? Can you describe how you have architected the Illumidesk platform? How have the design and goals shifted since you first began working on it? What are the strategies that you have used to allow for evolution and adaptation of the system in order to keep pace with the ecosystem of generative AI capabilities? What are the failure modes of the content generation that you need to account for? What are the most interesting, innovative, or unexpected ways that you have seen Illumidesk us
Summary
Data pipelines are the core of every data product, ML model, and business intelligence dashboard. If you're not careful you will end up spending all of your time on maintenance and fire-fighting. The folks at Rivery distilled the seven principles of modern data pipelines that will help you stay out of trouble and be productive with your data. In this episode Ariel Pohoryles explains what they are and how they work together to increase your chances of success.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack This episode is brought to you by Datafold – a testing automation platform for data engineers that finds data quality issues before the code and data are deployed to production. Datafold leverages data-diffing to compare production and development environments and column-level lineage to show you the exact impact of every code change on data, metrics, and BI tools, keeping your team productive and stakeholders happy. Datafold integrates with dbt, the modern data stack, and seamlessly plugs in your data CI for team-wide and automated testing. If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Your host is Tobias Macey and today I'm interviewing Ariel Pohoryles about the seven principles of modern data pipelines
Interview
Introduction How did you get involved in the area of data management? Can you start by defining what you mean by a "modern" data pipeline? At Rivery you published a white paper identifying seven principles of modern data pipelines:
Zero infrastructure management ELT-first mindset Speaks SQL and Python Dynamic multi-storage layers Reverse ETL & operational analytics Full transparency Faster time to value
What are the applications of data that you focused on while identifying these principles? How do the application of these principles influence the ability of organizations and their data teams to encourage and keep pace with the use of data in the business? What are the technical components of a pipeline infrastructure that are necessary to support a "modern" workflow? How do the technologies involved impact the organizational involvement with how data is applied throughout the business? When using managed services, what are the ways that the pricing model acts to encourage/discourage experimentation/exploration with data? What are the most interesting, innovative, or unexpected ways that you have seen these seven principles implemented/applied? What are the most interesting, unexpected, or challenging lessons that you have learned while working with customers to adapt to these principles? What are the cases where some/all of these principles are undesirable/impractical to implement? What are the opportunities for further advancement/sophistication in the ways that teams work with and gain value from data?
Contact Info
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned somethi
On today’s episode, we’re joined by Dan Balcauski, Founder and Chief Pricing Officer of Product Tranquility, a consulting firm in Austin, Texas focused on helping high-volume B2B SaaS CEOs define pricing and packaging for new products.
We talk about: What people often get wrong about pricingPricing questions you should never askWhat to ask instead The right way for companies to raise pricesHow to determine if you should publish pricing online
Summary
As businesses increasingly invest in technology and talent focused on data engineering and analytics, they want to know whether they are benefiting. So how do you calculate the return on investment for data? In this episode Barr Moses and Anna Filippova explore that question and provide useful exercises to start answering that in your company.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. You specify the customer traits, then Profiles runs the joins and computations for you to create complete customer profiles. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack Your host is Tobias Macey and today I'm interviewing Barr Moses and Anna Filippova about how and whether to measure the ROI of your data team
Interview
Introduction How did you get involved in the area of data management? What are the typical motivations for measuring and tracking the ROI for a data team?
Who is responsible for collecting that information? How is that information used and by whom?
What are some of the downsides/risks of tracking this metric? (law of unintended consequences) What are the inputs to the number that constitutes the "investment"? infrastructure, payroll of employees on team, time spent working with other teams? What are the aspects of data work and its impact on the business that complicate a calculation of the "return" that is generated? How should teams think about measuring data team ROI? What are some concrete ROI metrics data teams can use?
What level of detail is useful? What dimensions should be used for segmenting the calculations?
How can visibility into this ROI metric be best used to inform the priorities and project scopes of the team? With so many tools in the modern data stack today, what is the role of technology in helping drive or measure this impact? How do your respective solutions, Monte Carlo and dbt, help teams measure and scale data value? With generative AI on the upswing of the hype cycle, what are the impacts that you see it having on data teams?
What are the unrealistic expectations that it will produce? How can it speed up time to delivery?
What are the most interesting, innovative, or unexpected ways that you have seen data team ROI calculated and/or used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on measuring the ROI of data teams? When is measuring ROI the wrong choice?
Contact Info
Barr
Anna
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Monte Carlo
Podcast Episode
dbt
Podcast Episode
JetBlue Snowflake Con Presentation Generative AI Large Language Models
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Rudderstack:
Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guessw