A look inside at the data work happening at a company making some of the most advanced technologies in the industry. Rahul Jain, data engineering manager at Snowflake, joins Tristan to discuss Iceberg, streaming, and all things Snowflake. For full show notes and to read 6+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
 talk-data.com
talk-data.com
Topic
Snowflake
data_warehouse
cloud
analytics
olap
550
tagged
Activity Trend
193
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
146
Snowflake World Tour London
56
Snowflake World Tour Berlin
42
O'Reilly Data Engineering Books
33
Snowflake World Tour - Stockholm
27
Summit 2025 - On Demand
24
Snowflake World Tour - Paris
22
dbt Coalesce 2023
16
Snowflake World Tour Amsterdam
16
Big Data LDN 2025
15
Big Data LDN 2024
13
Data + AI Summit 2025
12

Explore Snowflake’s core concepts and unique features that differentiates it from industry competitors, such as, Azure Synapse and Google BigQuery. This book provides recipes for architecting and developing modern data pipelines on the Snowflake data platform by employing progressive techniques, agile practices, and repeatable strategies. You’ll walk through step-by-step instructions on ready-to-use recipes covering a wide range of the latest development topics. Then build scalable development pipelines and solve specific scenarios common to all modern data platforms, such as, data masking, object tagging, data monetization, and security best practices. Throughout the book you’ll work with code samples for Amazon Web Services, Microsoft Azure, and Google Cloud Platform. There’s also a chapter devoted to solving machine learning problems with Snowflake. Authors Dillon Dayton and John Eipe are both Snowflake SnowPro Core certified, specializing in data and digital services, and understand the challenges of finding the right solution to complex problems. The recipes in this book are based on real world use cases and examples designed to help you provide quality, performant, and secured data to solve business initiatives. What You’ll Learn Handle structured and un- structured data in Snowflake. Apply best practices and different options for data transformation. Understand data application development. Implement data sharing, data governance and security. Who This book Is For Data engineers, scientists and analysts moving into Snowflake, looking to build data apps. This book expects basic knowledge in Cloud (AWS or Azure or GCP), SQL and Python

A practical introduction to data engineering on the powerful Snowflake cloud data platform. Data engineers create the pipelines that ingest raw data, transform it, and funnel it to the analysts and professionals who need it. The Snowflake cloud data platform provides a suite of productivity-focused tools and features that simplify building and maintaining data pipelines. In Snowflake Data Engineering, Snowflake Data Superhero Maja Ferle shows you how to get started. In Snowflake Data Engineering you will learn how to: Ingest data into Snowflake from both cloud and local file systems Transform data using functions, stored procedures, and SQL Orchestrate data pipelines with streams and tasks, and monitor their execution Use Snowpark to run Python code in your pipelines Deploy Snowflake objects and code using continuous integration principles Optimize performance and costs when ingesting data into Snowflake Snowflake Data Engineering reveals how Snowflake makes it easy to work with unstructured data, set up continuous ingestion with Snowpipe, and keep your data safe and secure with best-in-class data governance features. Along the way, you’ll practice the most important data engineering tasks as you work through relevant hands-on examples. Throughout, author Maja Ferle shares design tips drawn from her years of experience to ensure your pipeline follows the best practices of software engineering, security, and data governance. About the Technology Pipelines that ingest and transform raw data are the lifeblood of business analytics, and data engineers rely on Snowflake to help them deliver those pipelines efficiently. Snowflake is a full-service cloud-based platform that handles everything from near-infinite storage, fast elastic compute services, inbuilt AI/ML capabilities like vector search, text-to-SQL, code generation, and more. This book gives you what you need to create effective data pipelines on the Snowflake platform. About the Book Snowflake Data Engineering guides you skill-by-skill through accomplishing on-the-job data engineering tasks using Snowflake. You’ll start by building your first simple pipeline and then expand it by adding increasingly powerful features, including data governance and security, adding CI/CD into your pipelines, and even augmenting data with generative AI. You’ll be amazed how far you can go in just a few short chapters! What's Inside Ingest data from the cloud, APIs, or Snowflake Marketplace Orchestrate data pipelines with streams and tasks Optimize performance and cost About the Reader For software developers and data analysts. Readers should know the basics of SQL and the Cloud. About the Author Maja Ferle is a Snowflake Subject Matter Expert and a Snowflake Data Superhero who holds the SnowPro Advanced Data Engineer and the SnowPro Advanced Data Analyst certifications. Quotes An incredible guide for going from zero to production with Snowflake. - Doyle Turner, Microsoft A must-have if you’re looking to excel in the field of data engineering. - Isabella Renzetti, Data Analytics Consultant & Trainer Masterful! Unlocks the true potential of Snowflake for modern data engineers. - Shankar Narayanan, Microsoft Valuable insights will enhance your data engineering skills and lead to cost-effective solutions. A must read! - Frédéric L’Anglais, Maxa Comprehensive, up-to-date and packed with real-life code examples. - Albert Nogués, Danone

Over the last decade, Big Data was everywhere. Let's set the record straight on what is and isn't Big Data. We have been consumed by a conversation about data volumes when we should focus more on the immediate task at hand: Simplifying our work.
Some of us may have Big Data, but our quest to derive insights from it is measured in small slices of work that fit on your laptop or in your hand. Easy data is here— let's make the most of it.
📓 Resources Big Data is Dead: https://motherduck.com/blog/big-data-is-dead/ Small Data Manifesto: https://motherduck.com/blog/small-data-manifesto/ Small Data SF: https://www.smalldatasf.com/
➡️ Follow Us LinkedIn: https://linkedin.com/company/motherduck X/Twitter : https://twitter.com/motherduck Blog: https://motherduck.com/blog/
Explore the "Small Data" movement, a counter-narrative to the prevailing big data conference hype. This talk challenges the assumption that data scale is the most important feature of every workload, defining big data as any dataset too large for a single machine. We'll unpack why this distinction is crucial for modern data engineering and analytics, setting the stage for a new perspective on data architecture.
Delve into the history of big data systems, starting with the non-linear hardware costs that plagued early data practitioners. Discover how Google's foundational papers on GFS, MapReduce, and Bigtable led to the creation of Hadoop, fundamentally changing how we scale data processing. We'll break down the "big data tax"—the inherent latency and system complexity overhead required for distributed systems to function, a critical concept for anyone evaluating data platforms.
Learn about the architectural cornerstone of the modern cloud data warehouse: the separation of storage and compute. This design, popularized by systems like Snowflake and Google BigQuery, allows storage to scale almost infinitely while compute resources are provisioned on-demand. Understand how this model paved the way for massive data lakes but also introduced new complexities and cost considerations that are often overlooked.
We examine the cracks appearing in the big data paradigm, especially for OLAP workloads. While systems like Snowflake are still dominant, the rise of powerful alternatives like DuckDB signals a shift. We reveal the hidden costs of big data analytics, exemplified by a petabyte-scale query costing nearly $6,000, and argue that for most use cases, it's too expensive to run computations over massive datasets.
The key to efficient data processing isn't your total data size, but the size of your "hot data" or working set. This talk argues that the revenge of the single node is here, as modern hardware can often handle the actual data queried without the overhead of the big data tax. This is a crucial optimization technique for reducing cost and improving performance in any data warehouse.
Discover the core principles for designing systems in a post-big data world. We'll show that since only 1 in 500 users run true big data queries, prioritizing simplicity over premature scaling is key. For low latency, process data close to the user with tools like DuckDB and SQLite. This local-first approach offers a compelling alternative to cloud-centric models, enabling faster, more cost-effective, and innovative data architectures.
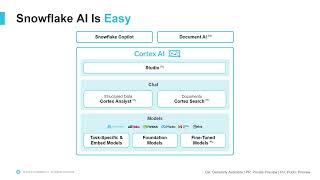
Ready to level up your data pipelines with AI and ML? In this session, we'll dive into key Snowflake AI and ML features and teach you how to easily integrate them into dbt pipelines. You'll explore real-world machine learning and generative AI use cases, and see how dbt and Snowflake together deliver powerful, secure results within Snowflake’s governance and security framework. Plus, discover how data scientists, engineers, and analysts can collaborate seamlessly using these tools. Whether you're scaling ML models or embedding AI into your existing workflows, this session will give you practical strategies for building secure, AI-powered data pipelines with dbt and Snowflake.
Speaker: Randy Pettus Senior Partner Sales Engineer Snowflake
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
There's been a ton of hype surrounding AI for enterprise data, but is anyone actually using it in production? In this talk, we'll explore how Sigma is leveraging, dbt, AI, and Sigma to build propensity models and more—creating a flywheel feedback loop powered by Sigma.
Attendees will learn: - Practical, real-world applications of these tools in AI workflows. - Integration benefits of Snowflake, dbt, and Sigma. - Challenges faced and solutions implemented. - The transformative impact on business outcomes.
Join us to discover actionable takeaways for implementing AI-driven solutions in your organization.
Speaker: Jake Hannan Head of Data Sigma
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

In this talk, data engineers from AB CarVal will discuss how to orchestrate jobs in an efficient and timely manner for business-critical data that arrives on a non-regular cadence, and why Infrastructure-as-Code is important and how to extend this to your dbt Cloud jobs running on Snowflake.
Speaker: Rafael Cohn-Gruenwald Sr. Data Engineer Alliance Bernstein
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
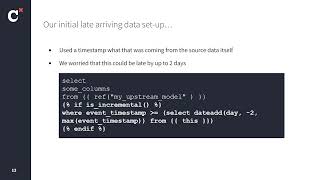
Like many other dbt users, Amplify has some very large data sets. (Their largest model needs to be updated every two hours and would cost $2.6 million to build annually if they fully refreshed it every time). Turning this into an incremental model was a natural choice, and helped a lot. However, they found that simply adding materialized = ‘incremental didn’t solve all of their problems.
Specifically, they still had issues running not_null and unique tests against such a large model, issues sizing their Snowflake warehouse appropriately to accommodate both incremental builds and full-refreshes, and perhaps most importantly, the model was still costing $50,000 annually to build (which can quickly add up when you have dozens of similarly sized models). In this talk they discuss several innovative solutions that they implemented to address these issues, including how they ultimately brought the cost of building this particular model down to just $600 annually!
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
This session will detail Pacific Life’s strategic transition to advanced data platforms, dbt and Snowflake. It will provide a comprehensive overview of the challenges encountered, the strategies employed to overcome them, and the significant advantages gained through this transformation.
Speakers: Trang Do Data Engineer Excellence Pacific Life
Jacob Emerson Data Engineer Pacific Life
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
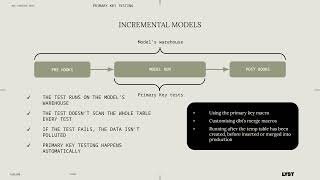
Are you looking to optimize your data workflows and elevate data quality in Snowflake? The analytics engineering team at Lyst achieved just that with innovative dbt macros…and it’s time to share the wealth!
In this session, Naomi will share two game-changing dbt macros that streamline data pipelines, reduce redundant efforts, and ensure robust data quality. Learn how her team’s approach to querying the dbt DAG identifies outdated models and simplifies pipeline migrations by detecting downstream impacts. Plus, uncover a fresh strategy for enhancing primary key testing on incremental models, resulting in instant efficiency and accuracy improvements.
You will walk away with actionable next steps to adopt these macros and best practices in your organization.
Speaker: Naomi Johnson Director of Data Platform Lyst
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Storebrand is a financial institution in Norway with several independent verticals — banking, pensions, insurance, asset management, properties — and horizontals across corporate and personal markets. To meet the matrix of data needs, Storebrand has needed to develop several data warehouses. They're now two years into the journey of building a new data platform, based on Snowflake and dbt, with four people in the platform team — and they're now scaling that central platform to the whole enterprise, with dbt Mesh. This requires automation of infrastructure and permissions to be regulatory compliant, data governance, clear separation of duties between the platform team and the data teams — for example, who has the responsibility for data masking and GDPR deletions? — a great developer experience, and a lot of good will. This presentation will try to answer how they've done it so far, and their plans to scale it from here.
Speaker: Eivind Berg Tech Lead Data Platform Storebrand
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements
The data team at SurveyMonkey, the global leader in survey software, oversees heavy data transformation in dbt Cloud — both to power current business-critical projects, and also to migrate legacy workloads. Much of that transformation work is taking raw data — either from legacy databases or their cloud data warehouse (Snowflake) — and making it accessible and useful for downstream users. And to Samiksha Gour, Senior Data Engineering Manager at SurveyMonkey, each of these projects is not considered complete unless the proper checks, monitors, and alerts are in place.
Join Samiksha in this informative session as she walks through how her team uses dbt and their data observability platform Monte Carlo to ensure proper governance, gain efficiencies by eliminating duplicate testing and monitoring, and use data lineage to ensure upstream and downstream continuity for users and stakeholders.
Speaker: Samiksha Gour Senior Data Engineering Manager SurveyMonkey
Read the blog to learn about the latest dbt Cloud features announced at Coalesce, designed to help organizations embrace analytics best practices at scale https://www.getdbt.com/blog/coalesce-2024-product-announcements

Dive into efficient data handling with 'In-Memory Analytics with Apache Arrow.' This book explores Apache Arrow, a powerful open-source project that revolutionizes how tabular and hierarchical data are processed. You'll learn to streamline data pipelines, accelerate analysis, and utilize high-performance tools for data exchange. What this Book will help me do Understand and utilize the Apache Arrow in-memory data format for your data analysis needs. Implement efficient and high-speed data pipelines using Arrow subprojects like Flight SQL and Acero. Enhance integration and performance in analysis workflows by using tools like Parquet and Snowflake with Arrow. Master chaining and reusing computations across languages and environments with Arrow's cross-language support. Apply in real-world scenarios by integrating Apache Arrow with analytics systems like Dremio and DuckDB. Author(s) Matthew Topol, the author of this book, brings 15 years of technical expertise in the realm of data processing and analysis. Having worked across various environments and languages, Matthew offers insights into optimizing workflows using Apache Arrow. His approachable writing style ensures that complex topics are comprehensible. Who is it for? This book is tailored for developers, data engineers, and data scientists eager to enhance their analytic toolset. Whether you're a beginner or have experience in data analysis, you'll find the concepts actionable and transformative. If you are curious about improving the performance and capabilities of your analytic pipelines or tools, this book is for you.
Snowflake had a big challenge: How do you enable a team of 1,000 sales engineers and field CTOs to successfully deploy over 100 new data products per week and demonstrate every feature and capability in the Snowflake AI Data Cloud tailored to different customer needs?
In this session, Andrew Helgeson, Manager of Technology Platform Alliances at Snowflake, and Guy Adams, CTO at DataOps.live, will explain how Snowflake builds and deploys hundreds of data products using DataOps.live. Join us for a deep dive into Snowflake's innovative approach to automating complex data product deployment — and to learn how Snowflake Solutions Central revolutionizes solution discovery and deployment to drive customer success.
Accor, a world-leading hospitality group offering experiences across more than 110 countries in 5,500 properties, 10,000 food & beverage venues, wellness facilities or flexible workspaces, relies on its more than 45 hotel brands from luxury to economy and its most awarded traveler loyalty program to connect deeply with customers and increase their lifetime value. With a rich store of data centralized in Snowflake, the team set out to enable their marketing and business teams with a platform that would allow them to autonomously deliver hyper-personalized experiences and campaigns.
Join the session to learn about Accor’s CDP journey and how Hightouch, as their Composable CDP, helps them drive customer engagement, loyalty, and revenue.
In his keynote talks at the Snowflake and Databricks Summit this year, Jenson Huang, the Founder CEO at NVIDEA, talked at length about how, to compete today, organizations have to build data flywheels: where they take their proprietary business data, use AI on that data to build proprietary intelligence, use that insight to build proprietary products and services that your customers love and use that to create more proprietary data to feed AIs to build more proprietary intelligence and so on.
But what does this mean in practice? Jenson's example of NVIDEA is intriguing - but how can the rest of us build data flywheels in our own organizations? What practical steps can they take?
In this talk, Yali Sassoon, Snowplow cofounder and CPO, will start to answer these questions, drawing on examples from Snowplow customers in retail, media and technology that have successfully built customer data flywheels on top of their proprietary 1st party customer data.
Join Scott Gamester as he challenges the outdated promises of legacy BI and self-service analytics tools. This session will explore the key issues that have hindered true data-driven decision-making and how modern solutions like Sigma Computing, Databricks, and Snowflake are redefining the landscape. Scott will demonstrate how integrating these platforms empowers business analysts, driving innovation at the edge and enabling AI-enhanced insights. Attendees will learn how these advancements are transforming business empowerment and fostering a new era of creativity and efficiency in analytics.
In today’s data-driven world, organizations are increasingly challenged to extract meaningful insights from both structured and unstructured data. Join Matillion and Snowflake in this exclusive session where we explore the transformative power of generative AI within data pipelines, leveraging Snowflake's robust platform and Cortex's advanced capabilities.
This session will guide you through practical use cases that demonstrate how to integrate unstructured and structured data to unlock new insights seamlessly:
Transforming Unstructured Data into Actionable Intelligence:
Discover how to convert customer reviews into structured data by labeling actionable items, extracting product names, and assessing sentiment. We’ll walk you through creating a BI dashboard and generating reports that highlight actionable defects and desired features, empowering your team to make data-driven decisions.
Generating Executive Summaries from Structured Data:
Learn how to generate insightful commentary from your existing structured data. We’ll show you how to create concise executive summaries and trend analyses, integrating contextual information such as competitor activities or regional updates. Imagine automating a weekly Slack message to your leadership team, complete with key sales trends and strategic insights.
Throughout this session, we will showcase the capabilities of Cortex, demonstrating how it can be seamlessly integrated into your data pipelines to enhance your data processing workflows. Whether you’re looking to improve customer experience, drive operational efficiency, or stay ahead of the competition, this session will provide you with the tools and techniques to harness the full potential of your data.
Join us to learn how to turn data into actionable insights that drive business success.
Discover how Chaucer overcame resistance to change and are implementing Snowflake as their core AI data platform.
When introducing new technologies into any business, resistance is often unavoidable. Connecting the people to the platform & accepting change is a journey Chaucer are very familiar with. Discover how they overcame resistance to change and are implementing Snowflake as their core platform. During this fireside chat, Marion will emphasise the importance of training and development in driving transformation and her passion for empowering girls and women in data. Join us to learn how aligning people with the right platforms can drive meaningful transformation and build a more inclusive future in the data industry.