Opening the Floodgates: Enabling Fast, Unmediated End User Access to Trillion-Row Datasets with SQL
Spreadsheets revolutionized IT by giving end users the ability to create their own analytics. Providing direct end user access to trillion-row datasets generated in financial markets or digital marketing is much harder. New SQL data warehouses like ClickHouse and Druid can provide fixed latency with constant cost on very large datasets, which opens up new possibilities.
Our talk walks through recent experience on analytic apps developed by ClickHouse users that enable end users like market traders to develop their own analytics directly off raw data. We’ll cover the following topics.
-
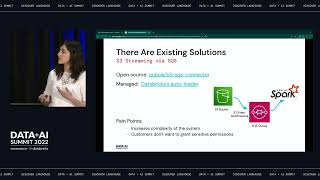
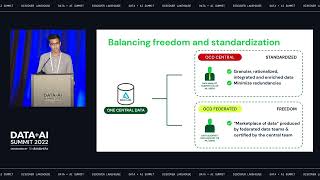
Characteristics of new open source column databases and how they enable low-latency analytics at constant cost.
-
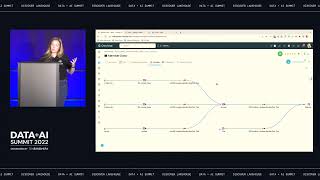
Idiomatic ways to validate new apps by building MVPs that support a wide range of queries on source data including storing source JSON, schema design, applying compression on columns, and building indexes for needle-in-a-haystack queries.
-
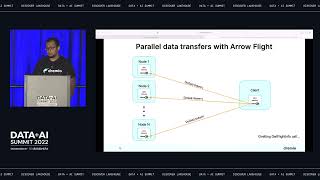
Incrementally identifying hotspots and applying easy optimizations to bring query performance into line with long term latency and cost requirements.
-
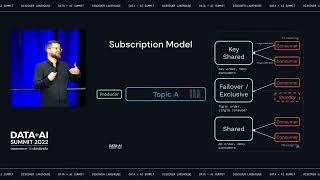
Methods of building accessible interfaces, including traditional dashboards, imitating existing APIs that are already known, and creating app-specific visualizations.
We’ll finish by summarizing a few of the benefits we’ve observed and also touch on ways that analytic infrastructure could be improved to make end user access even more productive. The lessons are as general as possible so that they can be applied across a wide range of analytic systems, not just ClickHouse.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/