 talk-data.com
talk-data.com
Topic
Analytics
4552
tagged
Activity Trend
Top Events
Help us become the #1 Data Podcast by leaving a rating & review! We are 67 reviews away! I built you a free tool that matches you to open data jobs! I built it using a low-code analytics tool called KNIME. Learn how I built it & how you can build your own! 👔 Try the Resume to Job Match App: https://apps.hub.knime.com/d/AI_Job_Search~data-app:c0cff571-721d-4cd2-aca7-5f19505d7537/run?authToken=cVZoMmVVZmF3RkM4eG9HdXVDdWltWTlZbFJDdzRCTjc0TXBLaFIzY3JYSTpmT3FYZ3VWZ19OTHgwZExxMGZ1Ty1XMUxySFF0QmdYRXBOWllaSVVQRnZmbnRHdGlnWlJ1cS1lM2hlQk0tM3k0TE0taHk3b0ZyQTh2S0t2YWV4QkREdw== 💻 Download KNIME: https://www.knime.com/start?utm_source=youtube&utm_medium=influencer&utm_term=avery_smith&utm_content=video&utm_campaign=kapsquad 📈 Download the KNIME Workflow: https://hub.knime.com/knime/spaces/Data%20Apps/AI_Job_Search~IkoQH5UBhidlxnEt/current-state?utm_source=youtube&utm_medium=influencer&utm_term=avery_smith&utm_content=video&utm_campaign=kapsquad 💌 Join 30k+ aspiring data analysts & get my tips in your inbox weekly 👉 https://www.datacareerjumpstart.com/newsletter 🆘 Feeling stuck in your data journey? Come to my next free "How to Land Your First Data Job" training 👉 https://www.datacareerjumpstart.com/training 👩💻 Want to land a data job in less than 90 days? 👉 https://www.datacareerjumpstart.com/daa 👔 Ace The Interview with Confidence 👉 https://www.datacareerjumpstart.com//interviewsimulator ⌚ TIMESTAMPS 0:00 - Avery's notes about episode (audio only) 7:33 - Use this free tool to find data jobs 09:36 - What is low-code analytics & why is it important? 13:20 - How I built this tool (& you can too) 16:47 - The future of low-code data tools 🔗 CONNECT WITH AVERY 🎥 YouTube Channel 🤝 LinkedIn 📸 Instagram 🎵 TikTok 💻 Website Mentioned in this episode: Join the last cohort of 2025! The LAST cohort of The Data Analytics Accelerator for 2025 kicks off on Monday, December 8th and enrollment is officially open!
To celebrate the end of the year, we’re running a special End-of-Year Sale, where you’ll get: ✅ A discount on your enrollment 🎁 6 bonus gifts, including job listings, interview prep, AI tools + more
If your goal is to land a data job in 2026, this is your chance to get ahead of the competition and start strong.
👉 Join the December Cohort & Claim Your Bonuses: https://DataCareerJumpstart.com/daa https://www.datacareerjumpstart.com/daa
Today, we’re turning the tables and interviewing our host, Arman Eshraghi, Founding CEO at Qrvey, the only embedded analytics solution purpose-built for SaaS. Arman tells us about:
What inspired him to start the SaaS Scaled podcastHow the vision of the podcast has changed since its inception in 2021How the fundamental objective remains: unscripted discussions in which experts share their knowledgeGetting comfortable and having sincere, authentic, organic discussionsWhat makes SaaS Scaled stand out among other podcasts
Does size matter? When it comes to datasets, the conventional wisdom seems to be a resounding, "Yes!" But what about small datasets? Small- and mid-sized businesses and nonprofits, especially, often have limited web traffic, small email lists, CRM systems that can comfortably operate under the free tier, and lead and order counts that don't lend themselves to "big data" descriptors. Even large enterprises have scenarios where some datasets easily fit into Google Sheets with limited scrolling required. Should this data be dismissed out of hand, or should it be treated as what it is: potentially useful? Joe Domaleski from Country Fried Creative works with a lot of businesses that are operating in the small data world, and he was so intrigued by the potential of putting data to use on behalf of his clients that he's mid-way through getting a Master's degree in Analytics from Georgia Tech! He wrote a really useful article about the ins and outs of small data, so we brought him on for a discussion on the topic! This episode's Measurement Bite from show sponsor Recast is an explanation of synthetic controls and how they can be used as counterfactuals from Michael Kaminsky! For complete show notes, including links to items mentioned in this episode and a transcript of the show, visit the show page.

Overcome challenges in building transactional guarantees on rapidly changing data by using Apache Hudi. With this practical guide, data engineers, data architects, and software architects will discover how to seamlessly build an interoperable lakehouse from disparate data sources and deliver faster insights using your query engine of choice. Authors Shiyan Xu, Prashant Wason, Bhavani Sudha Saktheeswaran, and Rebecca Bilbro provide practical examples and insights to help you unlock the full potential of data lakehouses for different levels of analytics, from batch to interactive to streaming. You'll also learn how to evaluate storage choices and leverage built-in automated table optimizations to build, maintain, and operate production data applications. Understand the need for transactional data lakehouses and the challenges associated with building them Explore data ecosystem support provided by Apache Hudi for popular data sources and query engines Perform different write and read operations on Apache Hudi tables and effectively use them for various use cases, including batch and stream applications Apply different storage techniques and considerations such as indexing and clustering to maximize your lakehouse performance Build end-to-end incremental data pipelines using Apache Hudi for faster ingestion and fresher analytics

Seasoned experts Jeroen ter Heerdt, Madzy Stikkelorum, and Marc Lelijveld help you master visual calculations in Power BI for transformative data insights Microsoft Power BI Visual Calculations: Simplifying DAX is a comprehensive guide that demystifies the innovative feature of visual calculations in Power BI. Jeroen, a Principal Product Manager at Microsoft, Madzy, a Data Analytics Consultant, and Marc, a Microsoft Data Platform MVP, bring their extensive expertise to this book, offering you a practical approach to mastering visual calculations. The book is designed to simplify DAX, making it accessible to beginners and empowering you to transform raw data into actionable insights. You will learn to implement visual calculations, understand their benefits, and apply them effectively in real-world scenarios, ultimately enhancing your ability to make data-driven decisions. By reading this book, you will: Understand the fundamentals of visual calculations in Power BI Create your first visual calculation with step-by-step guidance Explore advanced concepts like resetting context in visual calculations Compare visual calculations with other Power BI calculation options Master the performance characteristics of visual calculations Utilize specific functions designed for visual calculations Implement practical use cases like running sums and moving averages Enhance visual calculations with regular DAX expressions Optimize operational processes using data-driven insights Unlock the full potential of Power BI for strategic decision-making About This Book For Power BI users who want to simplify DAX and unlock the full potential of visual calculations without the usual complexities For business executives, managers, and data enthusiasts looking to transform raw data into actionable insights for strategic decision-making
Claudia Sahm, Chief Economist at New Century Advisors, joins Inside Economics to discuss a bevy of topics, including today’s belated Consumer Price Index release, the lack of other government data, AI and the labor market, stock market valuations, and the risks to the economy that are top of mind for her. Mark teases a new esoteric vocabulary word but fails to reveal it…stay tuned. Guest: Claudia Sahm – Chief Economist, New Century Advisors For more from Claudia Sahm, check out her Substack here: https://substack.com/@stayathomemacro Guest: Matt Colyar – Assistant Director, Moody's Analytics Hosts: Mark Zandi – Chief Economist, Moody’s Analytics, Cris deRitis – Deputy Chief Economist, Moody’s Analytics, and Marisa DiNatale – Senior Director - Head of Global Forecasting, Moody’s Analytics Follow Mark Zandi on 'X' and BlueSky @MarkZandi, Cris deRitis on LinkedIn, and Marisa DiNatale on LinkedIn
Questions or Comments, please email us at [email protected]. We would love to hear from you. To stay informed and follow the insights of Moody's Analytics economists, visit Economic View.
Hosted by Simplecast, an AdsWizz company. See pcm.adswizz.com for information about our collection and use of personal data for advertising.
In this talk, Sebastian, a bioinformatics researcher and software engineer, shares his inspiring journey from wet lab biotechnology to computational bioinformatics. Hosted by Data Talks Club, this session explores how data science, AI, and open-source tools are transforming modern biological research — from DNA sequencing to metagenomics and protein structure prediction.
You’ll learn about: - The difference between wet lab and dry lab workflows in biotechnology - How bioinformatics enables faster insights through data-driven modeling - The MCW2 Graph Project and its role in studying wastewater microbiomes - Using co-abundance networks and the CC Lasso algorithm to map microbial interactions - How AlphaFold revolutionized protein structure prediction - Building scientific knowledge graphs to integrate biological metadata - Open-source tools like VueGen and VueCore for automating reports and visualizations - The growing impact of AI and large language models (LLMs) in research and documentation - Key differences between R (BioConductor) and Python ecosystems for bioinformatics
This talk is ideal for data scientists, bioinformaticians, biotech researchers, and AI enthusiasts who want to understand how data science, AI, and biology intersect. Whether you work in genomics, computational biology, or scientific software, you’ll gain insights into real-world tools and workflows shaping the future of bioinformatics.
Links: - MicW2Graph: https://zenodo.org/records/12507444 - VueGen: https://github.com/Multiomics-Analytics-Group/vuegen - Awesome-Bioinformatics: https://github.com/danielecook/Awesome-Bioinformatics
TIMECODES00:00 Sebastian’s Journey into Bioinformatics06:02 From Wet Lab to Computational Biology08:23 Wet Lab vs Dry Lab Explained12:35 Bioinformatics as Data Science for Biology15:30 How DNA Sequencing Works19:29 MCW2 Graph and Wastewater Microbiomes23:10 Building Microbial Networks with CC Lasso26:54 Protein–Ligand Simulation Basics29:58 Predicting Protein Folding in 3D33:30 AlphaFold Revolution in Protein Prediction36:45 Inside the MCW2 Knowledge Graph39:54 VueGen: Automating Scientific Reports43:56 VueCore: Visualizing OMIX Data47:50 Using AI and LLMs in Bioinformatics50:25 R vs Python in Bioinformatics Tools53:17 Closing Thoughts from Ecuador Connect with Sebastian Twitter - https://twitter.com/sayalaruanoLinkedin - https://linkedin.com/in/sayalaruano Github - https://github.com/sayalaruanoWebsite - https://sayalaruano.github.io/ Connect with DataTalks.Club: Join the community - https://datatalks.club/slack.htmlSubscribe to our Google calendar to have all our events in your calendar - https://calendar.google.com/calendar/r?cid=ZjhxaWRqbnEwamhzY3A4ODA5azFlZ2hzNjBAZ3JvdXAuY2FsZW5kYXIuZ29vZ2xlLmNvbQCheck other upcoming events - https://lu.ma/dtc-eventsGitHub: https://github.com/DataTalksClubLinkedIn - https://www.linkedin.com/company/datatalks-club/Twitter - https://twitter.com/DataTalksClub - Website - https://datatalks.club/
Help us become the #1 Data Podcast by leaving a rating & review! We are 67 reviews away! Data meets music 🎶 — Avery sits down with Chris Reba, a data analyst who’s studied over 1 million songs, to reveal what the numbers say about how hits are made. From uncovering Billboard chart fraud to exploring how TikTok reshaped music, this episode breaks down the art and science behind every beat. 💌 Join 30k+ aspiring data analysts & get my tips in your inbox weekly 👉 https://www.datacareerjumpstart.com/newsletter 🆘 Feeling stuck in your data journey? Come to my next free "How to Land Your First Data Job" training 👉 https://www.datacareerjumpstart.com/training 👩💻 Want to land a data job in less than 90 days? 👉 https://www.datacareerjumpstart.com/daa 👔 Ace The Interview with Confidence 👉 https://www.datacareerjumpstart.com//interviewsimulator ⌚ TIMESTAMPS 00:00 - Intro: How Chris analyzed 1M+ songs using data 01:10 - What data reveals about hit songs and music trends 03:30 - Combining qualitative and quantitative analysis 07:00 - The 1970s Billboard chart fraud explained 10:45 - Why key changes disappeared from modern pop 13:30 - How hip-hop changed song structure and sound 14:10 - TikTok’s influence on the music industry 16:10 - Inside Chris’s open-source music dataset 22:10 - Best tools for music data analysis (SQL, Python, Datawrapper) 27:45 - Advice for aspiring music data analysts 🔗 CONNECT WITH CHRIS 📕 Order Chris's Book: https://www.bloomsbury.com/us/uncharted-territory-9798765149911 📊 Check out Chris's Music Dataset: https://docs.google.com/spreadsheets/d/1j1AUgtMnjpFTz54UdXgCKZ1i4bNxFjf01ImJ-BqBEt0/edit?gid=1974823090#gid=1974823090 💌 Subscribe to Chris's' Newsletter: https://www.cantgetmuchhigher.com 📲 Follow Chris on TikTok: https://www.tiktok.com/@cdallarivamusic 🔗 CONNECT WITH AVERY 🎥 YouTube Channel 🤝 LinkedIn 📸 Instagram 🎵 TikTok 💻 Website Mentioned in this episode: Join the last cohort of 2025! The LAST cohort of The Data Analytics Accelerator for 2025 kicks off on Monday, December 8th and enrollment is officially open!
To celebrate the end of the year, we’re running a special End-of-Year Sale, where you’ll get: ✅ A discount on your enrollment 🎁 6 bonus gifts, including job listings, interview prep, AI tools + more
If your goal is to land a data job in 2026, this is your chance to get ahead of the competition and start strong.
👉 Join the December Cohort & Claim Your Bonuses: https://DataCareerJumpstart.com/daa https://www.datacareerjumpstart.com/daa

AI-Driven Software Testing explores how Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing quality engineering (QE), making testing more intelligent, efficient, and adaptive. The book begins by examining the critical role of QE in modern software development and the paradigm shift introduced by AI/ML. It traces the evolution of software testing, from manual approaches to AI-powered automation, highlighting key innovations that enhance accuracy, speed, and scalability. Readers will gain a deep understanding of quality engineering in the age of AI, comparing traditional and AI-driven testing methodologies to uncover their advantages and challenges. Moving into practical applications, the book delves into AI-enhanced test planning, execution, and defect management. It explores AI-driven test case development, intelligent test environments, and real-time monitoring techniques that streamline the testing lifecycle. Additionally, it covers AI’s impact on continuous integration and delivery (CI/CD), predictive analytics for failure prevention, and strategies for scaling AI-driven testing across cloud platforms. Finally, it looks ahead to the future of AI in software testing, discussing emerging trends, ethical considerations, and the evolving role of QE professionals in an AI-first world. With real-world case studies and actionable insights, AI-Driven Software Testing is an essential guide for QE engineers, developers, and tech leaders looking to harness AI for smarter, faster, and more reliable software testing. What you will learn: • What are the key principles of AI/ML-driven quality engineering • What is intelligent test case generation and adaptive test automation • Explore predictive analytics for defect prevention and risk assessment • Understand integration of AI/ML tools in CI/CD pipelines Who this book is for: Quality Engineers looking to enhance software testing with AI-driven techniques. Data Scientists exploring AI applications in software quality assurance and engineering. Software Developers – Engineers seeking to integrate AI/ML into testing and automation workflows.
Ryan Dolley, VP of Product Strategy at GoodData and co-host of Super Data Brothers podcast, joined Yuliia and Dumke to discuss the DBT-Fivetran merger and what it signals about the modern data stack's consolidation phase. After 16 years in BI and analytics, Ryan explains why BI adoption has been stuck at 27% for a decade and why simply adding AI chatbots won't solve it. He argues that at large enterprises, purchasing new software is actually the only viable opportunity to change company culture - not because of the features, but because it forces operational pauses and new ways of working. Ryan shares his take that AI will struggle with BI because LLMs are trained to give emotionally satisfying answers rather than accurate ones. Ryan Dolley linkedin
Summary In this episode Kate Shaw, Senior Product Manager for Data and SLIM at SnapLogic, talks about the hidden and compounding costs of maintaining legacy systems—and practical strategies for modernization. She unpacks how “legacy” is less about age and more about when a system becomes a risk: blocking innovation, consuming excess IT time, and creating opportunity costs. Kate explores technical debt, vendor lock-in, lost context from employee turnover, and the slippery notion of “if it ain’t broke,” especially when data correctness and lineage are unclear. Shee digs into governance, observability, and data quality as foundations for trustworthy analytics and AI, and why exit strategies for system retirement should be planned from day one. The discussion covers composable architectures to avoid monoliths and big-bang migrations, how to bridge valuable systems into AI initiatives without lock-in, and why clear success criteria matter for AI projects. Kate shares lessons from the field on discovery, documentation gaps, parallel run strategies, and using integration as the connective tissue to unlock data for modern, cloud-native and AI-enabled use cases. She closes with guidance on planning migrations, defining measurable outcomes, ensuring lineage and compliance, and building for swap-ability so teams can evolve systems incrementally instead of living with a “bowl of spaghetti.”
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData teams everywhere face the same problem: they're forcing ML models, streaming data, and real-time processing through orchestration tools built for simple ETL. The result? Inflexible infrastructure that can't adapt to different workloads. That's why Cash App and Cisco rely on Prefect. Cash App's fraud detection team got what they needed - flexible compute options, isolated environments for custom packages, and seamless data exchange between workflows. Each model runs on the right infrastructure, whether that's high-memory machines or distributed compute. Orchestration is the foundation that determines whether your data team ships or struggles. ETL, ML model training, AI Engineering, Streaming - Prefect runs it all from ingestion to activation in one platform. Whoop and 1Password also trust Prefect for their data operations. If these industry leaders use Prefect for critical workflows, see what it can do for you at dataengineeringpodcast.com/prefect.Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Kate Shaw about the true costs of maintaining legacy systemsInterview IntroductionHow did you get involved in the area of data management?What are your crtieria for when a given system or service transitions to being "legacy"?In order for any service to survive long enough to become "legacy" it must be serving its purpose and providing value. What are the common factors that prompt teams to deprecate or migrate systems?What are the sources of monetary cost related to maintaining legacy systems while they remain operational?Beyond monetary cost, economics also have a concept of "opportunity cost". What are some of the ways that manifests in data teams who are maintaining or migrating from legacy systems?How does that loss of productivity impact the broader organization?How does the process of migration contribute to issues around data accuracy, reliability, etc. as well as contributing to potential compromises of security and compliance?Once a system has been replaced, it needs to be retired. What are some of the costs associated with removing a system from service?What are the most interesting, innovative, or unexpected ways that you have seen teams address the costs of legacy systems and their retirement?What are the most interesting, unexpected, or challenging lessons that you have learned while working on legacy systems migration?When is deprecation/migration the wrong choice?How have evolutionary architecture patterns helped to mitigate the costs of system retirement?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links SnapLogicSLIM == SnapLogic Intelligent ModernizerOpportunity CostSunk Cost FallacyData GovernanceEvolutionary ArchitectureThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Colleague Matt Colyar joins Cris and Mark on the podcast to discuss the prospects for inflation and the threat posed by subprime consumer credit problems to the banking system and broader economy. They discuss all of this through the prism of concerns raised by clients in their travels this past week: Mark was out West, Matt in Texas, and Cris in Bermuda. Guest: Matt Colyar - Assistan Director, Economist, Moody's Analytics Hosts: Mark Zandi – Chief Economist, Moody’s Analytics, Cris deRitis – Deputy Chief Economist, Moody’s Analytics, and Marisa DiNatale – Senior Director - Head of Global Forecasting, Moody’s Analytics Follow Mark Zandi on 'X' and BlueSky @MarkZandi, Cris deRitis on LinkedIn, and Marisa DiNatale on LinkedIn
Questions or Comments, please email us at [email protected]. We would love to hear from you. To stay informed and follow the insights of Moody's Analytics economists, visit Economic View.
Hosted by Simplecast, an AdsWizz company. See pcm.adswizz.com for information about our collection and use of personal data for advertising.
A inteligência de dados está remodelando indústrias inteiras, e o jornalismo é um dos exemplos mais fascinantes dessa transformação! Neste episódio, contamos como a EPTV, uma das maiores afiliadas da Rede Globo, está reinventando a forma de produzir notícia com a criação de um Núcleo de Jornalismo de Dados em parceria com a Snowflake. Um projeto que combina tecnologia, inteligência artificial e análise de dados para transformar informações públicas em reportagens mais precisas, ágeis e relevantes. Exploramos como essa estrutura nasceu, os desafios de implementar uma cultura orientada a dados e o papel da Snowflake na automatização do acesso a informações, integração de fontes e uso de IA contextual para antecipar tendências e apoiar decisões editoriais. Se você quer entender como dados e IA estão moldando o futuro do jornalismo e inspirando novas formas de contar histórias, esse episódio é para você! Lembrando que você pode encontrar todos os podcasts da comunidade Data Hackers no Spotify, iTunes, Google Podcast, Castbox e muitas outras plataformas. Convidados: Marcelo Manzano - Gerente do time de Solutions Engineering na Snowflake Brasil Bruno Woth - Gerente de Dados e Desenvolvimento na EPTV Nossa Bancada Data Hackers: Monique Femme — Head of Community Management na Data Hackers Gabriel Lages — Co-founder da Data Hackers e Data & Analytics Sr. Director na Hotmart. Referências: GRUPO EP - Empresas Pioneiras Snowflake
AI isn't just accelerating productivity, it's reshaping how we structure power, make decisions, and define what "value" means in our organizations. In this episode, Felicia Newhouse — a data leader, AI strategist, and advocate for ethical, human-centered innovation — brings deep insight into how power structures in business are being reimagined in the age of AI. We dive into why so-called soft skills like communication, critical thinking, and emotional intelligence are becoming core differentiators in data and AI teams. With research showing that companies deploying AI without leadership transformation risk ethical blind spots and cultural misalignment, we ask: What kind of leaders do we need now? And how can data professionals step into that shift? What You'll Learn: Why soft skills are no longer optional in data and AI roles How leadership, ethics, and communication shape responsible AI outcomes Real-world examples of companies gaining trust and performance by elevating human-centered skills 🤝 Follow Felicia on LinkedIn! Register for free to be part of the next live session: https://bit.ly/3XB3A8b Follow us on Socials: LinkedIn YouTube Instagram (Mavens of Data) Instagram (Maven Analytics) TikTok Facebook Medium X/Twitter
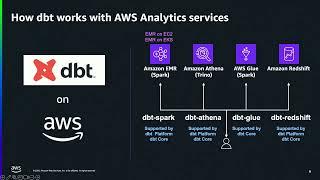
As organizations increasingly adopt modern data stacks, the combination of dbt and AWS Analytics services emerged as a powerful pairing for analytics engineering at scale. This session will explore proven strategies and hard-learned lessons for optimizing this technology stack to use dbt-athena, dbt-redshift, and dbt-glue to deliver reliable, performant data transformations. We will also cover case studies, best practices, and modern lakehouse scenarios with Apache Iceberg and Amazon S3 Tables.

AI is transforming data teams - maybe you're anxious, excited, or kind of bummed. I'll share how I went from AI skeptic to enthusiast, how analytics engineering is evolving, and how data teams can finally deliver on promises we've been making for years.
In this session we will cover the strategic and intentional tools that Workday took a bet on to create a true AI focused roadmap for data and analytics. You’ll learn about the strategy, alignment, tooling, and architecture put in place, covering both the journey & the technology.
Get certified at Coalesce! Choose from two certification exams: The dbt Analytics Engineering Certification Exam is designed to evaluate your ability to: Build, test, and maintain models to make data accessible to others Use dbt to apply engineering principles to analytics infrastructure We recommend that you have at least SQL proficiency and have had 6+ months of experience working in dbt (self-hosted dbt or the dbt platform) before attempting the exam. The dbt Architect Certification Exam assesses your ability to: Design secure, scalable dbt implementations, with a focus on environment orchestration Role-based access control Integrations with other tools Collaborative development workflows aligned with best practices What to expect Your purchase includes sitting for one attempt at one of the two in-person exams at Coalesce You will let the proctor know which certification you are sitting for Please arrive on time, this is a closed-door certification, and attendees will not be let in after the doors are closed What to bring You will need to bring your own laptop to take the exam Duration: 2 Hours Fee: $100 Trainings and certifications are not offered separately and must be purchased with a Coalesce pass Trainings and certifications are not available for Coalesce Online passes If you no-show for your certification, you will not be refunded
Come see how dbt empowers teams to harness Apache Iceberg and Snowflake Open Catalog for reliable, scalable, and agile analytics pipelines