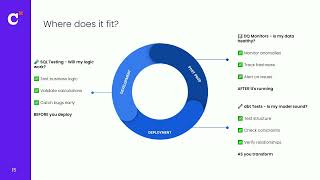
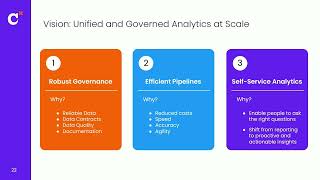
Amazon Bedrock AgentCore Evaluations provides developers with a unified way to test and validate AI agent performance. In this session, you’ll learn how to apply pre-built metrics for key dimensions such as task success, response quality, and tool accuracy, or define custom success criteria tailored to your needs. See how Evaluations integrates into CI/CD pipelines to catch regressions early and supports online evaluation in production by sampling and scoring live traces to surface real-world issues. Finally, learn how Evaluations helps teams deploy reliable agents faster, reduce operational risk, and continuously assess an agent’s performance at scale through practical implementation patterns.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.