by
Brad Davis
(Red Hat)
,
Matthew Simontacchi
(Red Hat)
,
Jesse Barker
(IIS)
,
Sudhir Prasad
(Red Hat)
,
Steven Huels
(Red Hat)
 talk-data.com
talk-data.com
Topic
Cloud Computing
infrastructure
saas
iaas
4055
tagged
Activity Trend
471
peak/qtr
2020-Q1
2026-Q2
Top Events
Google Cloud Next '24
911
Google Cloud Next '25
662
O'Reilly Data Engineering Books
499
AWS re:Invent 2024
341
Data Engineering Podcast
237
Microsoft Ignite 2025
227
Databricks DATA + AI Summit 2023
99
O'Reilly Data Science Books
96
Data + AI Summit 2025
86
Dbt Coalesce 2024
86
Making Data Simple
49
Secrets of Data Analytics Leaders
30
Join Kirk and Scott as they delve into a fascinating discussion with Scott, CEO of Caddis Cloud Solutions, exploring his journey from military service to leading the data center industry. Scott shares his background from a military family, his transition from the Marine Corps to corporate project management, and his insights into the evolving data center landscape. We discuss the industry's shift toward higher density systems, the rise of renewable and nuclear energy solutions, and the increasing demand for data-driven infrastructure. Scott highlights his company's role in bridging gaps between landowners and tech operators, emphasizes the need for innovative power solutions, and addresses the impact of emerging technologies like AI on the workforce. His vision for the future includes collaboration, sustainability, and advancing the tech sector with a focus on both innovation and societal responsibility.
For more about us: https://linktr.ee/overwatchmissioncritical

From Tableau Conference 2024, watch this recording of one of the popular Hands-on Training Sessions.
Navigating your Tableau Cloud Migration Journey Dive deeper into the benefits, challenges, and best practices for a successful Tableau Cloud migration. Note: Not a step-by-step guide, but covers resources and strategies to consider.

From Tableau Conference 2024, watch this recording of one of the popular Hands-on Training Sessions. Learn how to navigate your Tableau Cloud site essentials: configure settings, manage permissions, explore admin capabilities, and publish.

Master Amazon DynamoDB, the serverless NoSQL database designed for lightning-fast performance and scalability, with this definitive guide. You'll delve into its features, learn advanced concepts, and acquire practical skills to harness DynamoDB for modern application development. What this Book will help me do Understand AWS DynamoDB fundamentals for real-world applications. Model and optimize NoSQL databases with advanced techniques. Integrate DynamoDB into scalable, high-performance architectures. Utilize DynamoDB indexing, caching, and analytical features effectively. Plan and execute RDBMS to NoSQL data migrations successfully. Author(s) None Dhingra, an AWS DynamoDB solutions expert, and None Mackay, a seasoned NoSQL architect, bring their combined expertise straight from Amazon Web Services to guide you step-by-step in mastering DynamoDB. Combining comprehensive technical knowledge with approachable explanations, they empower readers to implement practical and efficient data strategies. Who is it for? This book is ideal for software developers and architects seeking to deepen their knowledge about AWS solutions like DynamoDB, engineering managers aiming to incorporate scalable NoSQL solutions into their projects, and data professionals transitioning from RDBMS towards a serverless data approach. Individuals with basic knowledge in cloud computing or database systems and those ready to advance in DynamoDB will find this book particularly beneficial.

Dive into the world of data analysis with the Polars Cookbook. This book, ideal for data professionals, covers practical recipes to manipulate, transform, and analyze data using the Python Polars library. You'll learn both the fundamentals and advanced techniques to build efficient and scalable data workflows. What this Book will help me do Master the basics of Python Polars including installation and setup. Perform complex data manipulation like pivoting, grouping, and joining. Handle large-scale time series data for accurate analysis. Understand data integration with libraries like pandas and numpy. Optimize workflows for both on-premise and cloud environments. Author(s) Yuki Kakegawa is an experienced data analytics consultant who has collaborated with companies such as Microsoft and Stanford Health Care. His passion for data led him to create this detailed guide on Polars. His expertise ensures you gain real-world, actionable insights from every chapter. Who is it for? This book is perfect for data analysts, engineers, and scientists eager to enhance their efficiency with Python Polars. If you are familiar with Python and tools like pandas but are new to Polars, this book will upskill you. Whether handling big data or optimizing code for performance, the Polars Cookbook has the guidance you need to succeed.

Dive into DuckDB and start processing gigabytes of data with ease—all with no data warehouse. DuckDB is a cutting-edge SQL database that makes it incredibly easy to analyze big data sets right from your laptop. In DuckDB in Action you’ll learn everything you need to know to get the most out of this awesome tool, keep your data secure on prem, and save you hundreds on your cloud bill. From data ingestion to advanced data pipelines, you’ll learn everything you need to get the most out of DuckDB—all through hands-on examples. Open up DuckDB in Action and learn how to: Read and process data from CSV, JSON and Parquet sources both locally and remote Write analytical SQL queries, including aggregations, common table expressions, window functions, special types of joins, and pivot tables Use DuckDB from Python, both with SQL and its "Relational"-API, interacting with databases but also data frames Prepare, ingest and query large datasets Build cloud data pipelines Extend DuckDB with custom functionality Pragmatic and comprehensive, DuckDB in Action introduces the DuckDB database and shows you how to use it to solve common data workflow problems. You won’t need to read through pages of documentation—you’ll learn as you work. Get to grips with DuckDB's unique SQL dialect, learning to seamlessly load, prepare, and analyze data using SQL queries. Extend DuckDB with both Python and built-in tools such as MotherDuck, and gain practical insights into building robust and automated data pipelines. About the Technology DuckDB makes data analytics fast and fun! You don’t need to set up a Spark or run a cloud data warehouse just to process a few hundred gigabytes of data. DuckDB is easily embeddable in any data analytics application, runs on a laptop, and processes data from almost any source, including JSON, CSV, Parquet, SQLite and Postgres. About the Book DuckDB in Action guides you example-by-example from setup, through your first SQL query, to advanced topics like building data pipelines and embedding DuckDB as a local data store for a Streamlit web app. You’ll explore DuckDB’s handy SQL extensions, get to grips with aggregation, analysis, and data without persistence, and use Python to customize DuckDB. A hands-on project accompanies each new topic, so you can see DuckDB in action. What's Inside Prepare, ingest and query large datasets Build cloud data pipelines Extend DuckDB with custom functionality Fast-paced SQL recap: From simple queries to advanced analytics About the Reader For data pros comfortable with Python and CLI tools. About the Authors Mark Needham is a blogger and video creator at @LearnDataWithMark. Michael Hunger leads product innovation for the Neo4j graph database. Michael Simons is a Java Champion, author, and Engineer at Neo4j. Quotes I use DuckDB every day, and I still learned a lot about how DuckDB makes things that are hard in most databases easy! - Jordan Tigani, Founder, MotherDuck An excellent resource! Unlocks possibilities for storing, processing, analyzing, and summarizing data at the edge using DuckDB. - Pramod Sadalage, Director, Thoughtworks Clear and accessible. A comprehensive resource for harnessing the power of DuckDB for both novices and experienced professionals. - Qiusheng Wu, Associate Professor, University of Tennessee Excellent! The book all we ducklings have been waiting for! - Gunnar Morling, Decodable
Join Kirk and Emil Sayegh as they discuss Emil's remarkable journey from an immigrant from Lebanon to proudly becoming a U.S. citizen and serving the country through his leadership in the tech industry. Emil shares his path from mechanical engineering to product management, ultimately leading three Data Center and Managed Services companies as CEO. The conversation delves into the evolution and challenges of the data center industry, highlighting the critical need for sustainable energy solutions to address power consumption and efficiency issues.
They explore the importance of smart algorithms, the evolution of managed services, and customer-centric approaches, with insights from Emil's experience at Rackspace. Key topics include capital management, talent acquisition, cloud services, AI integration, and robust security practices, along with reflections on software glitches and outdated systems. The discussion underscores the balance between technological progress and ethical governance, emphasizing the role of human values and optimism in addressing global challenges through technology.
Utilizing a Hailo AI Acceleration Module with a Raspberry Pi 5 device we will process real-time video streams from an edge camera and store real-time results in a vector database and send messages to Slack channels. We will show you how to build Edge AI applications that can stream unstructured data to the cloud or store it locally in a local Vector database. We will run a live demo of a neural network inference accelerator capable of 13 tera-operations per second (TOPS).
0:00
hi everyone Welcome to our event this event is brought to you by data dos club which is a community of people who love
0:06
data and we have weekly events and today one is one of such events and I guess we
0:12
are also a community of people who like to wake up early if you're from the states right Christopher or maybe not so
0:19
much because this is the time we usually have uh uh our events uh for our guests
0:27
and presenters from the states we usually do it in the evening of Berlin time but yes unfortunately it kind of
0:34
slipped my mind but anyways we have a lot of events you can check them in the
0:41
description like there's a link um I don't think there are a lot of them right now on that link but we will be
0:48
adding more and more I think we have like five or six uh interviews scheduled so um keep an eye on that do not forget
0:56
to subscribe to our YouTube channel this way you will get notified about all our future streams that will be as awesome
1:02
as the one today and of course very important do not forget to join our community where you can hang out with
1:09
other data enthusiasts during today's interview you can ask any question there's a pin Link in live chat so click
1:18
on that link ask your question and we will be covering these questions during the interview now I will stop sharing my
1:27
screen and uh there is there's a a message in uh and Christopher is from
1:34
you so we actually have this on YouTube but so they have not seen what you wrote
1:39
but there is a message from to anyone who's watching this right now from Christopher saying hello everyone can I
1:46
call you Chris or you okay I should go I should uh I should look on YouTube then okay yeah but anyways I'll you don't
1:53
need like you we'll need to focus on answering questions and I'll keep an eye
1:58
I'll be keeping an eye on all the question questions so um
2:04
yeah if you're ready we can start I'm ready yeah and you prefer Christopher
2:10
not Chris right Chris is fine Chris is fine it's a bit shorter um
2:18
okay so this week we'll talk about data Ops again maybe it's a tradition that we talk about data Ops every like once per
2:25
year but we actually skipped one year so because we did not have we haven't had
2:31
Chris for some time so today we have a very special guest Christopher Christopher is the co-founder CEO and
2:37
head chef or hat cook at data kitchen with 25 years of experience maybe this
2:43
is outdated uh cuz probably now you have more and maybe you stopped counting I
2:48
don't know but like with tons of years of experience in analytics and software engineering Christopher is known as the
2:55
co-author of the data Ops cookbook and data Ops Manifesto and it's not the
3:00
first time we have Christopher here on the podcast we interviewed him two years ago also about data Ops and this one
3:07
will be about data hops so we'll catch up and see what actually changed in in
3:13
these two years and yeah so welcome to the interview well thank you for having
3:19
me I'm I'm happy to be here and talking all things related to data Ops and why
3:24
why why bother with data Ops and happy to talk about the company or or what's changed
3:30
excited yeah so let's dive in so the questions for today's interview are prepared by Johanna berer as always
3:37
thanks Johanna for your help so before we start with our main topic for today
3:42
data Ops uh let's start with your ground can you tell us about your career Journey so far and also for those who
3:50
have not heard have not listened to the previous podcast maybe you can um talk
3:55
about yourself and also for those who did listen to the previous you can also maybe give a summary of what has changed
4:03
in the last two years so we'll do yeah so um my name is Chris so I guess I'm
4:09
a sort of an engineer so I spent about the first 15 years of my career in
4:15
software sort of working and building some AI systems some non- AI systems uh
4:21
at uh Us's NASA and MIT linol lab and then some startups and then um
4:30
Microsoft and then about 2005 I got I got the data bug uh I think you know my
4:35
kids were small and I thought oh this data thing was easy and I'd be able to go home uh for dinner at 5 and life
4:41
would be fine um because I was a big you started your own company right and uh it didn't work out that way
4:50
and um and what was interesting is is for me it the problem wasn't doing the
4:57
data like I we had smart people who did data science and data engineering the act of creating things it was like the
5:04
systems around the data that were hard um things it was really hard to not have
5:11
errors in production and I would sort of driving to work and I had a Blackberry at the time and I would not look at my
5:18
Blackberry all all morning I had this long drive to work and I'd sit in the parking lot and take a deep breath and
5:24
look at my Blackberry and go uh oh is there going to be any problems today and I'd be and if there wasn't I'd walk and
5:30
very happy um and if there was I'd have to like rce myself um and you know and
5:36
then the second problem is the team I worked for we just couldn't go fast enough the customers were super
5:42
demanding they didn't care they all they always thought things should be faster and we are always behind and so um how
5:50
do you you know how do you live in that world where things are breaking left and right you're terrified of making errors
5:57
um and then second you just can't go fast enough um and it's preh Hadoop era
6:02
right it's like before all this big data Tech yeah before this was we were using
6:08
uh SQL Server um and we actually you know we had smart people so we we we
6:14
built an engine in SQL Server that made SQL Server a column or
6:20
database so we built a column or database inside of SQL Server um so uh
6:26
in order to make certain things fast and and uh yeah it was it was really uh it's not
6:33
bad I mean the principles are the same right before Hadoop it's it's still a database there's still indexes there's
6:38
still queries um things like that we we uh at the time uh you would use olap
6:43
engines we didn't use those but you those reports you know are for models it's it's not that different um you know
6:50
we had a rack of servers instead of the cloud um so yeah and I think so what what I
6:57
took from that was uh it's just hard to run a team of people to do do data and analytics and it's not
7:05
really I I took it from a manager perspective I started to read Deming and
7:11
think about the work that we do as a factory you know and in a factory that produces insight and not automobiles um
7:18
and so how do you run that factory so it produces things that are good of good
7:24
quality and then second since I had come from software I've been very influenced
7:29
by by the devops movement how you automate deployment how you run in an agile way how you
7:35
produce um how you how you change things quickly and how you innovate and so
7:41
those two things of like running you know running a really good solid production line that has very low errors
7:47
um and then second changing that production line at at very very often they're kind of opposite right um and so
7:55
how do you how do you as a manager how do you technically approach that and
8:00
then um 10 years ago when we started data kitchen um we've always been a profitable company and so we started off
8:07
uh with some customers we started building some software and realized that we couldn't work any other way and that
8:13
the way we work wasn't understood by a lot of people so we had to write a book and a Manifesto to kind of share our our
8:21
methods and then so yeah we've been in so we've been in business now about a little over 10
8:28
years oh that's cool and uh like what
8:33
uh so let's talk about dat offs and you mentioned devops and how you were inspired by that and by the way like do
8:41
you remember roughly when devops as I think started to appear like when did people start calling these principles
8:49
and like tools around them as de yeah so agile Manifesto well first of all the I
8:57
mean I had a boss in 1990 at Nasa who had this idea build a
9:03
little test a little learn a lot right that was his Mantra and then which made
9:09
made a lot of sense um and so and then the sort of agile software Manifesto
9:14
came out which is very similar in 2001 and then um the sort of first real
9:22
devops was a guy at Twitter started to do automat automated deployment you know
9:27
push a button and that was like 200 Nish and so the first I think devops
9:33
Meetup was around then so it's it's it's been 15 years I guess 6 like I was
9:39
trying to so I started my career in 2010 so I my first job was a Java
9:44
developer and like I remember for some things like we would just uh SFTP to the
9:52
machine and then put the jar archive there and then like keep our fingers crossed that it doesn't break uh uh like
10:00
it was not really the I wouldn't call it this way right you were deploying you
10:06
had a Dey process I put it yeah
10:11
right was that so that was documented too it was like put the jar on production cross your
10:17
fingers I think there was uh like a page on uh some internal Viki uh yeah that
10:25
describes like with passwords and don't like what you should do yeah that was and and I think what's interesting is
10:33
why that changed right and and we laugh at it now but that was why didn't you
10:38
invest in automating deployment or a whole bunch of automated regression
10:44
tests right that would run because I think in software now that would be rare
10:49
that people wouldn't use C CD they wouldn't have some automated tests you know functional
10:56
regression tests that would be the
John Grubb is the Sr. Director of FinOps and Cost Modeling at Platform.sh. With experience as a former Data Platform Director, Director of BI & Analytics, and Director of Customer Care, John brings a sharp perspective on why cloud costs matter. He knows how to align financial and engineering teams and believes that FinOps is about maximizing the value of every cloud dollar rather than just cutting costs.Follow John on Linkedin- https://www.linkedin.com/in/johnnygrubb/John's blog - https://www.thefinoperator.com/
Dive into this AWS session with Rick Sears, General Manager of Amazon Athena, EMR, and Lake Formation at AWS, and Martin Holste, CTO Cloud and AI at Trellix. Explore how Trellix uses Amazon Bedrock and AWS EMR to revolutionize security operations. Learn how generative AI and comprehensive data strategies enhance threat detection and automate security processes, driving a new era of efficiency and protection. Discover practical AI applications and real-world examples, and get ready to accelerate your AI journey with AWS.
Speakers: Martin Holste, CTO Cloud and AI, Trellix Rick Sears, General Manager of Amazon Athena, EMR, and Lake Formation, Amazon Web Services
Learn more: https://go.aws/3x2mha0 Learn more about AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world’s most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSEvents #awsaidataconference #awsgenai
Summary Data contracts are both an enforcement mechanism for data quality, and a promise to downstream consumers. In this episode Tom Baeyens returns to discuss the purpose and scope of data contracts, emphasizing their importance in achieving reliable analytical data and preventing issues before they arise. He explains how data contracts can be used to enforce guarantees and requirements, and how they fit into the broader context of data observability and quality monitoring. The discussion also covers the challenges and benefits of implementing data contracts, the organizational impact, and the potential for standardization in the field.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino.At Outshift, the incubation engine from Cisco, they are driving innovation in AI, cloud, and quantum technologies with the powerful combination of enterprise strength and startup agility. Their latest innovation for the AI ecosystem is Motific, addressing a critical gap in going from prototype to production with generative AI. Motific is your vendor and model-agnostic platform for building safe, trustworthy, and cost-effective generative AI solutions in days instead of months. Motific provides easy integration with your organizational data, combined with advanced, customizable policy controls and observability to help ensure compliance throughout the entire process. Move beyond the constraints of traditional AI implementation and ensure your projects are launched quickly and with a firm foundation of trust and efficiency. Go to motific.ai today to learn more!Your host is Tobias Macey and today I'm interviewing Tom Baeyens about using data contracts to build a clearer API for your dataInterview IntroductionHow did you get involved in the area of data management?Can you describe the scope and purpose of data contracts in the context of this conversation?In what way(s) do they differ from data quality/data observability?Data contracts are also known as the API for data, can you elaborate on this?What are the types of guarantees and requirements that you can enforce with these data contracts?What are some examples of constraints or guarantees that cannot be represented in these contracts?Are data contracts related to the shift-left?Data contracts are also known as the API for data, can you elaborate on this?The obvious application of data contracts are in the context of pipeline execution flows to prevent failing checks from propagating further in the data flow. What are some of the other ways that these contracts can be integrated into an organization's data ecosystem?How did you approach the design of the syntax and implementation for Soda's data contracts?Guarantees and constraints around data in different contexts have been implemented in numerous tools and systems. What are the areas of overlap in e.g. dbt, great expectations?Are there any emerging standards or design patterns around data contracts/guarantees that will help encourage portability and integration across tooling/platform contexts?What are the most interesting, innovative, or unexpected ways that you have seen data contracts used?What are the most interesting, unexpected, or challenging lessons that you have learned while working on data contracts at Soda?When are data contracts the wrong choice?What do you have planned for the future of data contracts?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links SodaPodcast EpisodeJBossData ContractAirflowUnit TestingIntegration TestingOpenAPIGraphQLCircuit Breaker PatternSodaCLSoda Data ContractsData MeshGreat Expectationsdbt Unit TestsOpen Data ContractsODCS == Open Data Contract StandardODPS == Open Data Product SpecificationThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
In this DCAC Europe Special Episode, Kirk and Cathal reveal the story behind their transatlantic partnership, the exciting journey of DCAC Europe’s inception, the reason behind bringing it to Dublin, Ireland, and their motivations and challenges faced in organizing an industry leading conference in a new country. For more information visit- https://europe.dcac-live.com. For sponsorship inquires email [email protected]
Thank you to our Title Sponsor MCIS - Mission Critical Interior Solutions, Inc. provides interior architectural solutions for data, cloud, and mission critical centers across North America. We offer everything from polished, epoxy, and sealed concrete to raised flooring, hot/cold aisle containment, and high-density ceiling grid. We also install raised access flooring in office spaces and provide underfloor air distribution testing to commission spaces - https://mcis-inc.com
For more about us: https://linktr.ee/overwatchmissioncritical
Trigger warning: This episode includes discussions of suicidal ideations. Listener discretion is advised. If you or someone you know is struggling with thoughts of suicide, please reach out for help or conact- 988 Suicide and Crisis Lifeline
Join Kirk And Cathal Quinn, as they share deeply personal stories and experiences. They emphasize the value of educational podcasts aiming to inspire and inform their audience about complex subjects within data centers and industry advancements. Cathal reflects on his upbringing, which shaped his strong work ethic and resilience, highlighting its impact on his perspective and advocacy for mental health and veteran support. Kirk shares his journey in the data center sector, stressing the role of individuals in driving innovation. They explore personal struggles such as addiction and mental health challenges. They stress the importance of balance, self-care, and open communication in leadership and personal life, underscoring the power of storytelling in fostering empathy and understanding.
Thank you to our Title Sponsor MCIS - Mission Critical Interior Solutions, Inc. provides interior architectural solutions for data, cloud, and mission critical centers across North America. We offer everything from polished, epoxy, and sealed concrete to raised flooring, hot/cold aisle containment, and high-density ceiling grid. We also install raised access flooring in office spaces and provide underfloor air distribution testing to commission spaces - https://mcis-inc.com
For more about us: https://linktr.ee/overwatchmissioncritical
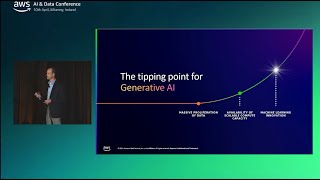
In this session, Rick Sears, General Manager of Amazon Athena, EMR, and Lake Formation at AWS, explores how generative AI is revolutionizing businesses and the critical role data plays in this transformation. He discusses the evolution of AI models and the importance of a comprehensive data management strategy encompassing availability, quality, and protection of data.
Mark Greville, Vice President of Architecture at Workhuman, shares insights from Workhuman's journey in building a robust cloud-based data strategy, emphasizing the significance of storytelling, demonstrating value, and gaining executive support.
Kamal Sampathkumar, Senior Manager of Data Architecture at Workhuman, delves into the technical aspects, detailing the architecture of Workhuman's data platform and showcasing solutions like Data API and self-service reporting that deliver substantial value to customers.
Learn more at: https://go.aws/3x2mha0
Learn more about AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world’s most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.
AWSEvents #awsaianddataconference #generativeaiconference #genaiconference #genaievent #AWSgenerativeai #AWSgenai
This project explores how Equivariant Graph Neural Networks (EGNNs) enhance predictive accuracy in point cloud data analysis. The results aim to advance the processing of unstructured 3D data for autonomous vehicle perception and forecasting.