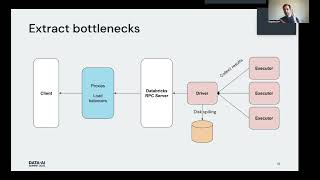
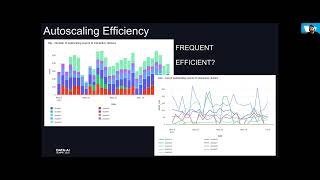
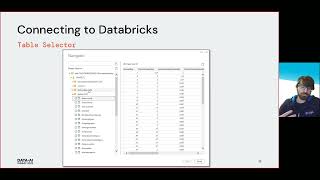
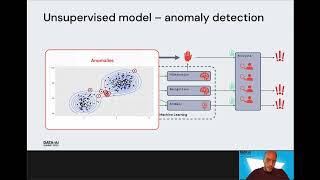
RECKON (RECommendation systems using KnOwledge Networks) is a machine learning project centred around improving the entities intelligence.
We represent the dataset of our site interactions as a heterogeneous graph. The nodes represent various entities in the underlying data (Users, Articles, Authors, etc.). Edges between nodes represent interactions between these entities (User u has read article v, Article u was written by author v, etc.)
RECKON uses a GNN based encoder-decoder architecture to learn representations for important entities in our data by leveraging both their individual features and the interactions between them through repeated graph convolutions.
Personalized Recommendations play an important role in improving our user's experience and retaining them. We would like to take this opportunity to walk through some of the techniques that we have incorporated in RECKON and an end-end building of this product on databricks along with the demo.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/