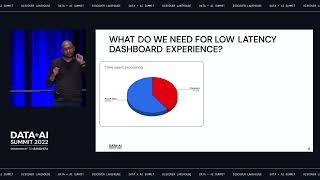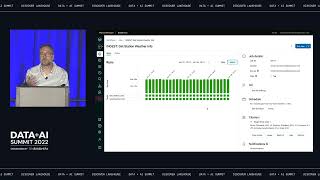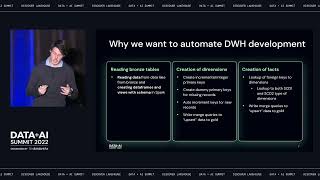
With serverless SQL compute and built-in governance, Databricks SQL lets every analyst and analytics engineer easily ingest, transform, and query the freshest data directly on your data lake, using their tools of choice like Fivetran, dbt, PowerBI or Tableau, and standard SQL. There is no need to move data to another system. All this takes place at virtually any scale, at a fraction of the cost of traditional cloud data warehouses. Join this session for a deep dive into how Databricks SQL works under the hood, and see a live end-to-end demo of the data and analytics on Databricks from data ingestion, transformation, and consumption, using the modern data stack along with Databricks SQL.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/