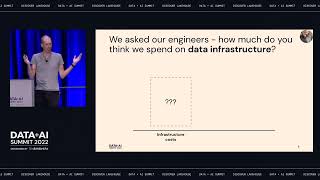
Data Lineage is key for managing change, ensuring data quality and implementing Data Governance in an organization. There are a few use cases for Data Lineage: Data Governance: For compliance and regulatory purposes our customers are required to prove the data/reports they are submitting came from a trusted and verified source.
This typically means identifying the tables and data sets used in a report or dashboard and tracing the source of these tables and fields. Another use case for the Governance scenario is to understand the spread of sensitive data within the lakehouse. Data Discovery: Data analysts looking to self-serve and build their own analytics and models typically spend time exploring and understanding the data in their lakehouse.
Lineage is a key piece of information which enhances the understanding and trustworthiness of the data the analyst plans to use. Problem Identification: Data teams are often called to solve errors in analysts dashboards and reports (“Why is the total number of widgets different in this report than the one I have built?”). This usually leads to an expensive forensic exercise by the DE team to understand the sources of data and the transformations applied to it before it hits the report. Change Management : It is not uncommon for data sources to change, a new source may stop delivering data or a field in the source system changes its semantics.
In this scenario the DE team would like to understand the downstream impact of this change - to get a sense of how many datasets and users will be affected by this change. This will help them determine the impact of the change, manage user expectations and address issues ahead of time In this talk, we will talk about how we capture table and column lineage for spark / delta and unity catalog for our customers in details and how users could leverage data lineage to serve various use cases mentioned above.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/