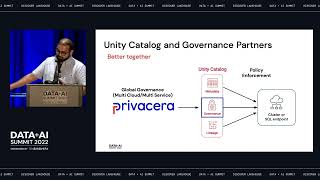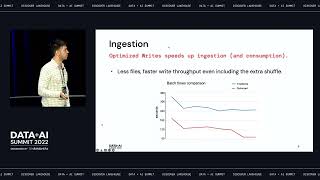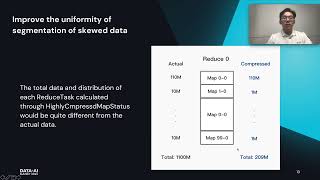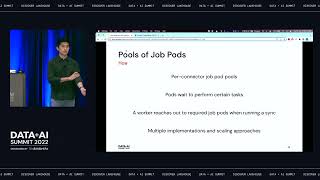
Nearly every developer is familiar with creating a CLI. Containerized CLIs provide a flexible, cross-language standard with a low barrier to entry for open-source contributors. The ETL process can be reduced to two CLIs: one that reads data and one that writes data. While this interface is simple enough to implement from the contributor’s side, Kubernetes’ distributed nature means orchestrating data transfer between the CLIs on Kubernetes presents an unsolved problem.
This talk describes a novel approach to reliably orchestrate CLIs on Kubernetes for data integration. Through this lens, we go through the evaluation of strategies and describe the pros and cons of each architecture for horizontally scaling containerised data integration workflows on Kubernetes. We also cover the journey of implementing a TCP-based “process” abstraction over CLIs using socat and UNIX pipes. This same approach powers all of Airbyte’s Kubernetes deployments and helps sync TBs of data daily.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/