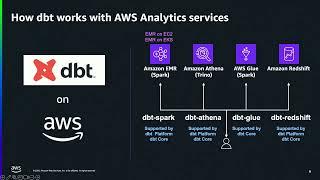
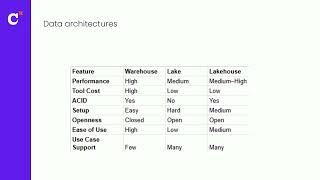
Discover advanced strategies for implementing Apache Iceberg on AWS, focusing on Amazon S3 Tables and integration of Iceberg Rest Catalog with the lakehouse in Amazon SageMaker. We'll cover performance optimization techniques for Amazon Athena and Amazon Redshift queries, real-time processing using Apache Spark, and integration with Amazon EMR, AWS Glue, and Trino. Explore practical implementations of zero-ETL, change data capture (CDC) patterns, and medallion architecture. Gain hands-on expertise in implementing enterprise-grade lakehouse solutions with Iceberg on AWS.
Learn more: More AWS events: https://go.aws/3kss9CP
Subscribe: More AWS videos: http://bit.ly/2O3zS75 More AWS events videos: http://bit.ly/316g9t4
ABOUT AWS: Amazon Web Services (AWS) hosts events, both online and in-person, bringing the cloud computing community together to connect, collaborate, and learn from AWS experts. AWS is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. Millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—are using AWS to lower costs, become more agile, and innovate faster.