
 talk-data.com
talk-data.com
Topic
Arrow
Apache Arrow
data_processing
columnar_memory_format
big_data
46
tagged
Activity Trend
6
peak/qtr
2020-Q1
2026-Q2
Top Events
Data Engineering Podcast
10
Data Council Austin 2024 - Day 1
5
Databricks DATA + AI Summit 2023
4
PyConDE & PyData Berlin 2023
3
PyData Paris 2025
3
The Analytics Engineering Podcast
2
Data Council 2023
2
O'Reilly Data Engineering Books
2
PyData Paris 2024
2
Data + AI Summit 2025
2
Data Skeptic
1
Making Data Simple
1


Summary
Building a database engine requires a substantial amount of engineering effort and time investment. Over the decades of research and development into building these software systems there are a number of common components that are shared across implementations. When Paul Dix decided to re-write the InfluxDB engine he found the Apache Arrow ecosystem ready and waiting with useful building blocks to accelerate the process. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. It is an open-source, cloud-native orchestrator for the whole development lifecycle, with integrated lineage and observability, a declarative programming model, and best-in-class testability. Your team can get up and running in minutes thanks to Dagster Cloud, an enterprise-class hosted solution that offers serverless and hybrid deployments, enhanced security, and on-demand ephemeral test deployments. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Join us at the top event for the global data community, Data Council Austin. From March 26-28th 2024, we'll play host to hundreds of attendees, 100 top speakers and dozens of startups that are advancing data science, engineering and AI. Data Council attendees are amazing founders, data scientists, lead engineers, CTOs, heads of data, investors and community organizers who are all working together to build the future of data and sharing their insights and learnings through deeply technical talks. As a listener to the Data Engineering Podcast you can get a special discount off regular priced and late bird tickets by using the promo code dataengpod20. Don't miss out on our only event this year! Visit dataengineeringpodcast.com/data-council and use code dataengpod20 to register today! Your host is Tobias Macey and today I'm interviewing Paul Dix about his investment in the Apache Arrow ecosystem and how it led him to create the latest PFAD in database design
Interview
Introduction How did you get involved in the area of data management? Can you start by describing the FDAP stack and how the components combine to provide a foundational architecture for database engines?
This was the core of your recent re-write of the InfluxDB engine. What were the design goals and constraints that led you to this architecture?
Each of the architectural components are well engineered for their particular scope. What is the engineering work that is involved in building a cohesive platform from those components? One of the major benefits of using open source components is the network effect of ecosystem integrations. That can also be a risk when the community vision for the project doesn't align with your own goals. How have you worked to mitigate that risk in your specific platform? Can you describe the

Join Jay Alexander Clifford in a deep dive into Time Series Analytics with Apache Arrow, Pandas, and Parquet. 📈🐍 Explore the power of columnar databases, and learn how to build efficient and scalable analytics applications for time series data using open-source tools. 🚀 #TimeSeries #analytics
✨ H I G H L I G H T S ✨
🙌 A huge shoutout to all the incredible participants who made Big Data Conference Europe 2023 in Vilnius, Lithuania, from November 21-24, an absolute triumph! 🎉 Your attendance and active participation were instrumental in making this event so special. 🌍
Don't forget to check out the session recordings from the conference to relive the valuable insights and knowledge shared! 📽️
Once again, THANK YOU for playing a pivotal role in the success of Big Data Conference Europe 2023. 🚀 See you next year for another unforgettable conference! 📅 #BigDataConference #SeeYouNextYear
Rust is a unique language whose traits make it very appealing for data engineering. In this session, we'll walk through the different aspects of the language that make it such a good fit for big data processing including: how it improves performance and how it provides greater safety guarantees and compatibility with a wide range of existing tools that make it well positioned to become a major building block for the future of analytics.
We will also take a hands-on look through real code examples at a few emerging technologies built on top of Rust that utilize these capabilities, and learn how to apply them to our modern lakehouse architecture.
Talk by: Oz Katz
Here’s more to explore: Why the Data Lakehouse Is Your next Data Warehouse: https://dbricks.co/3Pt5unq Lakehouse Fundamentals Training: https://dbricks.co/44ancQs
Connect with us: Website: https://databricks.com Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/databricks Instagram: https://www.instagram.com/databricksinc Facebook: https://www.facebook.com/databricksinc

ABOUT THE TALK: Over the last decade I have been lucky enough to contribute a few successful open source projects to the data ecosystem. In this talk
Julien Le Dem shares the story of his contribution to successful open source projects to the data ecosystem and what made their success possible. From the ideation process and early growth of the Apache Parquet columnar format and how this led to the creation of its in-memory alter-ego Apache Arrow. Julian will end with showing how this experience enabled the success of OpenLineage, an LFAI & Data project that brings observability to the data ecosystem.
ABOUT THE SPEAKER: Julien Le Dem is the Chief Architect of Astronomer and Co-Founder of Datakin. He co-created Apache Parquet and is involved in several open source projects including OpenLineage, Marquez (LFAI&Data), Apache Arrow, Apache Iceberg and a few others. Previously, he was a senior principal at Wework; principal architect at Dremio; and tech lead for Twitter’s data processing tools and principal engineer working on content platforms at Yahoo, where he received his Hadoop initiation.
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/

ABOUT THE TALK: In this talk, we'll dive into one of the newest Apache Arrow subprojects, Arrow Database Connectivity (ADBC), an API specification for Arrow-based database access.
Over the course of this session, you’ll get a crash course in ADBC and learn how it communicates with different data APIs (like Arrow Flight SQL and Postgres) using Arrow-native in-memory data. By the end, you’ll understand the use cases it can conquer and know where to access the resources you need to get started.
This talk will cover goals, use-cases, and examples of using ADBC to communicate with different Data APIs (such as Flight SQL or postgres) with Arrow Native in-memory data.
ABOUT THE SPEAKER: Matthew Topol is a committer for the Apache Arrow project, frequently enhancing the Golang Arrow and Parquet libraries among other enhancements and helping to grow the Arrow Community. Recently, Matt has joined Voltron Data in order to work on the Apache Arrow libraries full time and grow the Arrow Golang community. In June 2022, Matt's first book was published, which is the first (and currently only) book on Apache Arrow titled "In-Memory Analytics with Apache Arrow".
ABOUT DATA COUNCIL: Data Council (https://www.datacouncil.ai/) is a community and conference series that provides data professionals with the learning and networking opportunities they need to grow their careers.
Make sure to subscribe to our channel for the most up-to-date talks from technical professionals on data related topics including data infrastructure, data engineering, ML systems, analytics and AI from top startups and tech companies.
FOLLOW DATA COUNCIL: Twitter: https://twitter.com/DataCouncilAI LinkedIn: https://www.linkedin.com/company/datacouncil-ai/
Apache Arrow is a multi-language toolbox for accelerated data interchange and in-memory processing, and is becoming the de facto standard for tabular data. This talk will give an overview of the recent developments both in Apache Arrow itself as how it is being adopted in the PyData ecosystem (and beyond) and can improve your day-to-day data analytics workflows.
In this talk, we will report on our experiences switching from Pandas to Polars in a real-world ML project. Polars is a new high-performance dataframe library for Python based on Apache Arrow and written in Rust. We will compare the performance of polars with the popular pandas library, and show how polars can provide significant speed improvements for data manipulation and analysis tasks. We will also discuss the unique features of polars, such as its ability to handle large datasets that do not fit into memory, and how it feels in practice to make the switch from Pandas. This talk is aimed at data scientists, analysts, and anyone interested in fast and efficient data processing in Python.
Pandas is the de-facto standard for data manipulation in python, which I personally love for its flexible syntax and interoperability. But Pandas has well-known drawbacks such as memory in-efficiency, inconsistent missing data handling and lacking multicore-support. Multiple open-source projects aim to solve those issues, the most interesting is Polars.
Polars uses Rust and Apache Arrow to win in all kinds of performance-benchmarks and evolves fast. But is it already stable enough to migrate an existing Pandas' codebase? And does it meet the high-expectations on query language flexibility of long-time Pandas-lovers?
In this talk, I will explain, how Polars can be that fast, and present my insights on where Polars shines and in which scenarios I stay with pandas (at least for now!)
Summary
Business intelligence has gone through many generational shifts, but each generation has largely maintained the same workflow. Data analysts create reports that are used by the business to understand and direct the business, but the process is very labor and time intensive. The team at Omni have taken a new approach by automatically building models based on the queries that are executed. In this episode Chris Merrick shares how they manage integration and automation around the modeling layer and how it improves the organizational experience of business intelligence.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management Truly leveraging and benefiting from streaming data is hard - the data stack is costly, difficult to use and still has limitations. Materialize breaks down those barriers with a true cloud-native streaming database - not simply a database that connects to streaming systems. With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started. If you like what you see and want to help make it better, they're hiring across all functions! Your host is Tobias Macey and today I'm interviewing Chris Merrick about the Omni Analytics platform and how they are adding automatic data modeling to your business intelligence
Interview
Introduction How did you get involved in the area of data management? Can you describe what Omni Analytics is and the story behind it?
What are the core goals that you are trying to achieve with building Omni?
Business intelligence has gone through many evolutions. What are the unique capabilities that Omni Analytics offers over other players in the market?
What are the technical and organizational anti-patterns that typically grow up around BI systems?
What are the elements that contribute to BI being such a difficult product to use effectively in an organization?
Can you describe how you have implemented the Omni platform?
How have the design/scope/goals of the product changed since you first started working on it?
What does the workflow for a team using Omni look like?
What are some of the developments in the broader ecosystem that have made your work possible?
What are some of the positive and negative inspirations that you have drawn from the experience that you and your team-mates have gained in previous businesses?
What are the most interesting, innovative, or unexpected ways that you have seen Omni used?
What are the most interesting, unexpected, or challenging lessons that you have learned while working on Omni?
When is Omni the wrong choice?
What do you have planned for the future of Omni?
Contact Info
LinkedIn @cmerrick on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Omni Analytics Stitch RJ Metrics Looker
Podcast Episode
Singer dbt
Podcast Episode
Teradata Fivetran Apache Arrow
Podcast Episode
DuckDB
Podcast Episode
BigQuery Snowflake
Podcast Episode
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Materialize: 
Looking for the simplest way to get the freshest data possible to your teams? Because let's face it: if real-time were easy, everyone would be using it. Look no further than Materialize, the streaming database you already know how to use.
Materialize’s PostgreSQL-compatible interface lets users leverage the tools they already use, with unsurpassed simplicity enabled by full ANSI SQL support. Delivered as a single platform with the separation of storage and compute, strict-serializability, active replication, horizontal scalability and workload isolation — Materialize is now the fastest way to build products with streaming data, drastically reducing the time, expertise, cost and maintenance traditionally associated with implementation of real-time features.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud data warehouses.
Go to materialize.comSupport Data Engineering Podcast
Wes McKinney is the creator of pandas, co-creator of Apache Arrow, and now Co-founder/CTO at Voltron Data. In this conversation with Tristan and Julia, Wes takes us on a tour of the underlying guts, from hardware to data formats, of the data ecosystem. What innovations, down to the hardware level, will stack to lead to significantly better performance for analytics workloads in the coming years? To dig deeper on the Apache Arrow ecosystem, check out replays from their recent conference at https://thedatathread.com. For full show notes and to read 7+ years of back issues of the podcast's companion newsletter, head to https://roundup.getdbt.com. The Analytics Engineering Podcast is sponsored by dbt Labs.
Summary The data ecosystem has been growing rapidly, with new communities joining and bringing their preferred programming languages to the mix. This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. The Arrow project is designed to eliminate wasted effort in translating between languages, and Voltron Data was created to help grow and support its technology and community. In this episode Wes McKinney shares the ways that Arrow and its related projects are improving the efficiency of data systems and driving their next stage of evolution.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Push information about data freshness and quality to your business intelligence, automatically scale up and down your warehouse based on usage patterns, and let the bots answer those questions in Slack so that the humans can focus on delivering real value. Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Struggling with broken pipelines? Stale dashboards? Missing data? If this resonates with you, you’re not alone. Data engineers struggling with unreliable data need look no further than Monte Carlo, the leading end-to-end Data Observability Platform! Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo monitors and alerts for data issues across your data warehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. Start trusting your data with Monte Carlo today! Visit dataengineeringpodcast.com/montecarlo to learn more. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., are already available as plug-and-play connectors with reliable, intuitive SaaS solutions. Hevo Data is a highly reliable and intuitive data pipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance. Boasting more than 150 out-of-the-box connectors that can be set up in minutes, Hevo also allows you to monitor and control your pipelines. You get: real-time data flow visibility, fail-safe mechanisms, and alerts if anything breaks; preload transformations and auto-schema mapping precisely control how data lands in your destination; models and workflows to transform data for analytics; and reverse-ETL capability to move the transformed data back to your business software to inspire timely action. All of this, plus its transparent pricing and 24*7 live support, makes it consistently voted by users as the Leader in the Data Pipeline category on review platforms like G2. Go to dataengineeringpodcast.com/hevodata and sign up for a free 14-day trial that also comes with 24×7 support. Your host is Tobias Macey and today I’m interviewing Wes McKinney about his work at Voltron Data and on the Arrow ecosystem
Interview
Introduction How did you get involved in the area of data management? Can you describe what you are building at Voltron Data and the story behind it? What is the vision for the broader data ecosystem that you are trying to realize through your investment in Arrow and related projects?
How does your work at Voltron Data contribute to the realization of that vision?
What is the impact on engineer productivity and compute efficiency that gets introduced by the impedance mismatches between language and framework representations of data? The scope and capabilities of the Arrow project have grown substantially since it was first introduced. Can you give an overview of the current features and extensions to the project? What are some of the ways that ArrowVe and its related projects can be integrated with or replace the different elements of a data platform? Can you describe how Arrow is implemented?
What are the most complex/challenging aspects of the engineering needed to support interoperable data interchange between language runtimes?
How are you balancing the desire to move quickly and improve the Arrow protocol and implementations, with the need to wait for other players in the ecosystem (e.g. database engines, compute frameworks, etc.) to add support? With the growing application of data formats such as graphs and vectors, what do you see as the role of Arrow and its ideas in those use cases? For workflows that rely on integrating structured and unstructured data, what are the options for interaction with non-tabular data? (e.g. images, documents, etc.) With your support-focused business model, how are you approaching marketing and customer education to make it viable and scalable? What are the most interesting, innovative, or unexpected ways that you have seen Arrow used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Arrow and its ecosystem? When is Arrow the wrong choice? What do you have planned for the future of Arrow?
Contact Info
Website wesm on GitHub @wesmckinn on Twitter
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don’t forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast helps you go from idea to production with machine learning. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you’ve learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers
Links
Voltron Data Pandas
Podcast Episode
Apache Arrow Partial Differential Equation FPGA == Field-Programmable Gate Array GPU == Graphics Processing Unit Ursa Labs Voltron (cartoon) Feature Engineering PySpark Substrait Arrow Flight Acero Arrow Datafusion Velox Ibis SIMD == Single Instruction, Multiple Data Lance DuckDB
Podcast Episode
Data Threads Conference Nano-Arrow Arrow ADBC Protocol Apache Iceberg
Podcast Episode
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By:
Atlan: 
Have you ever woken up to a crisis because a number on a dashboard is broken and no one knows why? Or sent out frustrating slack messages trying to find the right data set? Or tried to understand what a column name means?
Our friends at Atlan started out as a data team themselves and faced all this collaboration chaos themselves, and started building Atlan as an internal tool for themselves. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. By acting as a virtual hub for data assets ranging from tables and dashboards to SQL snippets & code, Atlan enables teams to create a single source of truth for all their data assets, and collaborate across the modern data stack through deep integrations with tools like Snowflake, Slack, Looker and more.
Go to dataengineeringpodcast.com/atlan and sign up for a free trial. If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription.a href="https://dataengineeringpodcast.com/montecarlo"…
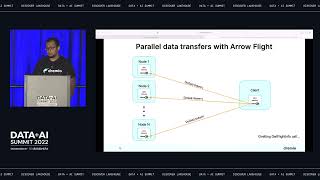
Network protocols for transferring data generally have one of two problems: they’re slow for large data transfers but have simple APIs (e.g. JDBC) or they’re fast for large data transfers but have complex APIs specific to the system. Apache Arrow Flight addresses the former by providing high performance data transfers and half of the latter by having a standard API independent of systems. However, while the Arrow Flight API is performant and an open standard, it can be more complex to use than simpler APIs like JDBC.
Arrow Flight SQL rounds out the solution, providing both great performance and a simple universal API.
In this talk, we’ll show the performance benefits of Arrow Flight, the client difference between interacting with Arrow Flight and Arrow Flight SQL, and an overview of a JDBC driver built on Arrow Flight SQL, enabling clients to take advantage of this increased performance with zero application changes.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Learn how Rust, the Apache Arrow project, and the Data Fusion Query Engine are increasingly being used to accelerate the creation of modern data stacks.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

This talk will introduce Polars a blazingly fast DataFrame library written in Rust on top of Apache Arrow. Its a DataFrame library that brings exploratory data analysis closer to the lessons learned in database research.
CPU's today's come with many cores and with their superscalar designs and SIMD registers allow for even more parallelism. Polars is written from the ground up to fully utilize the CPU's of this generation.
Besides blazingly fast algorithms, cache efficient memory layout and multi-threading, it consist of a lazy query engine, allowing Polars to do several optimizations that may improve query time and memory usage.
Read more:
https://github.com/pola-rs/polars https://www.ritchievink.com/blog/2021/02/28/i-wrote-one-of-the-fastest-dataframe-libraries/
Join the talk to learn more.
Connect with us: Website: https://databricks.com Facebook: https://www.facebook.com/databricksinc Twitter: https://twitter.com/databricks LinkedIn: https://www.linkedin.com/company/data... Instagram: https://www.instagram.com/databricksinc/

Discover the power of in-memory data analytics with "In-Memory Analytics with Apache Arrow." This book delves into Apache Arrow's unique capabilities, enabling you to handle vast amounts of data efficiently and effectively. Learn how Arrow improves performance, offers seamless integration, and simplifies data analysis in diverse computing environments. What this Book will help me do Gain proficiency with the datastore facilities and data types defined by Apache Arrow. Master the Arrow Flight APIs to efficiently transfer data between systems. Learn to leverage in-memory processing advantages offered by Arrow for state-of-the-art analytics. Understand how Arrow interoperates with popular tools like Pandas, Parquet, and Spark. Develop and deploy high-performance data analysis pipelines with Apache Arrow. Author(s) Matthew Topol, the author of the book, is an experienced practitioner in data analytics and Apache Arrow technology. Having contributed to the development and implementation of Arrow-powered systems, he brings a wealth of knowledge to readers. His ability to delve deep into technical concepts while keeping explanations practical makes this book an excellent guide for learners of the subject. Who is it for? This book is ideal for professionals in the data domain including developers, data analysts, and data scientists aiming to enhance their data manipulation capabilities. Beginners with some familiarity with data analysis concepts will find it beneficial, as well as engineers designing analytics utilities. Programming examples accommodate users of C, Go, and Python, making it broadly accessible.
Summary Machine learning has become a meaningful target for data applications, bringing with it an increase in the complexity of orchestrating the entire data flow. Flyte is a project that was started at Lyft to address their internal needs for machine learning and integrated closely with Kubernetes as the execution manager. In this episode Ketan Umare and Haytham Abuelfutuh share the story of the Flyte project and how their work at Union is focused on supporting and scaling the code and community that has made Flyte successful.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their managed Kubernetes platform it’s now even easier to deploy and scale your workflows, or try out the latest Helm charts from tools like Pulsar and Pachyderm. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform. Go to dataengineeringpodcast.com/linode today and get a $100 credit to try out a Kubernetes cluster of your own. And don’t forget to thank them for their continued support of this show! This episode is brought to you by Acryl Data, the company behind DataHub, the leading developer-friendly data catalog for the modern data stack. Open Source DataHub is running in production at several companies like Peloton, Optum, Udemy, Zynga and others. Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or data lake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. Data lake architectures provide the best combination of massive scalability and cost reduction, but they aren’t always the most performant option. That’s why Kyligence has built on top of the leading open source OLAP engine for data lakes, Apache Kylin. With their AI augmented engine they detect patterns from your critical queries, automatically build data marts with optimized table structures, and provide a unified SQL interface across your lake, cubes, and indexes. Their cost-based query router will give you interactive speeds across petabyte scale data sets for BI dashboards and ad-hoc data exploration. Stop struggling to speed up your data lake. Get started with Kyligence today at dataengineeringpodcast.com/kyligence Your host is Tobias Macey and today I’m interviewing Ketan Umare and Haytham Abuelfutuh about Flyte, the open source and kubernetes-native orchestration engine for your data systems
Interview
Introduction How did you get involved in the area of data management? Can you describe what Flyte is and the story behind it? What was missing in the ecosystem of available tools that made it necessary/worthwhile to create Flyte? Workflow orchestrators have been around for several years and have gone through a number of generational shifts. How would you characterize Flyte’s position in the ecosystem?
What do you see as the closest alternatives? What are the core differentiators that might lead someone to choose Flyte over e.g. Airflow/Prefect/Dagster?
What are the core primitives that Flyte exposes for building up complex workflows?
Machine learning use cases have been a core focus since the project’s inception. What are some of the ways that that manifests in the design and feature set?
Can you describe the architecture of Flyte?
How have the design and goals of the platform changed/evolved since you first started working on it?
What are the changes in the data ecosystem that have had the most substantial impact on the Flyte project? (e.g. roadmap, integrations, pushing people toward adoption, etc.) What is the process for setting up a Flyte deployment? What are the user personas that you prioritize in the design and feature development for Flyte? What is the workflow for someone building a new pipeline in Flyte?
What are the patterns that you and the community have established to encourage discovery and reuse of granular task definitions? Beyond code reuse, how can teams scale usage of Flyte at the company/organization level?
What are the affordances that you have created to facilitate local development and testing of workflows while ensuring a smooth transition to production?
What are the patterns that are available for CI/CD of workflows using Flyte?
How have you approached the design of data contracts/type definitions to provide a consistent/portable API for defining inter-task dependencies across languages? What are the available interfaces for extending Flyte and building integrations with other components across the data ecosystem? Data orchestration engines are a natural point for generating and taking advantage of rich metadata. How do you manage creation and propagation of metadata within and across the framework boundaries? Last year you founded Union to offer a managed version of Flyte. What are the features that you are offering beyond what is available in the open source?
What are the opportunities that you see for the Flyte ecosystem with a corporate entity to invest in expanding adoption?
What are the most interesting, innovative, or unexpected ways that you have seen Flyte used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Flyte? When is Flyte the wrong choice? What do you have planned for the future of Flyte?
Contact Info
Ketan Umare Haytham Abuelfutuh
Parting Question
From your perspective, what is the biggest gap in the tooling or technology for data management today?
Closing Announcements
Thank you for listening! Don’t forget to check out our other show, Podcast.init to learn about the Python language, its community, and the innovative ways it is being used. Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes. If you’ve learned something or tried out a project from the show then tell us about it! Email [email protected]) with your story. To help other people find the show please leave a review on iTunes and tell your friends and co-workers
Links
Flyte
Slack Channel
Union.ai Kubeflow Airflow AWS Step Functions Protocol Buffers XGBoost MLFlow Dagster
Podcast Episode
Prefect
Podcast Episode
Arrow Parquet Metaflow Pytorch
Podcast.init Episode
dbt FastAPI
Podcast.init Interview
Python Type Annotations Modin
Podcast.init Interview
Monad Datahub
Podcast Episode
OpenMetadata
Podcast Episode
Hudi
Podcast Episode
Iceberg
Podcast Episode
Great Expectations
Podcast Episode
Pandera Union ML Weights and Biases Whylogs
Podcast Episode
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Sponsored By: a…
Summary Pandas is a powerful tool for cleaning, transforming, manipulating, or enriching data, among many other potential uses. As a result it has become a standard tool for data engineers for a wide range of applications. Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. He recently wrote a book on effective patterns for Pandas code, and in this episode he shares advice on how to write efficient data processing routines that will scale with your data volumes, while being understandable and maintainable.
Announcements
Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. With their managed Kubernetes platform it’s now even easier to deploy and scale your workflows, or try out the latest Helm charts from tools like Pulsar and Pachyderm. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform. Go to dataengineeringpodcast.com/linode today and get a $100 credit to try out a Kubernetes cluster of your own. And don’t forget to thank them for their continued support of this show! Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud. Prophecy provides an easy-to-use visual interface to design & deploy data pipelines on Apache Spark & Apache Airflow. Now all the data users can use software engineering best practices – git, tests and continuous deployment with a simple to use visual designer. How does it work? – You visually design the pipelines, and Prophecy generates clean Spark code with tests on git; then you visually schedule these pipelines on Airflow. You can observe your pipelines with built in metadata search and column level lineage. Finally, if you have existing workflows in AbInitio, Informatica or other ETL formats that you want to move to the cloud, you can import them automatically into Prophecy making them run productively on Spark. Create your free account today at dataengineeringpodcast.com/prophecy. The only thing worse than having bad data is not knowing that you have it. With Bigeye’s data observability platform, if there is an issue with your data or data pipelines you’ll know right away and can get it fixed before the business is impacted. Bigeye let’s data teams measure, improve, and communicate the quality of your data to company stakeholders. With complete API access, a user-friendly interface, and automated yet flexible alerting, you’ve got everything you need to establish and maintain trust in your data. Go to dataengineeringpodcast.com/bigeye today to sign up and start trusting your analyses. Your host is Tobias Macey and today I’m interviewing Matt Harrison about useful tips for using Pandas for data engineering projects
Interview
Introduction How did you get involved in the area of data management? What are the main tasks that you have seen Pandas used for in a data engineering context? What are some of the common mistakes that can lead to poor performance when scaling to large data sets? What are some of the utility features that you have found most helpful for data processing? One of the interesting add-ons to Pandas is its integration with Arrow. What are some of the considerations for how and when to use the Arrow capabilities vs. out-of-the-box Pandas? Pandas is a tool that spans data processing and data science. What are some of the ways that data engineers should think about writing their code to make it accessible to data scientists for supporting collaboration across data workflows? Pandas is often used for transformation logic. What are some of the ways that engineers should approach the design of their code to make it understandable and maint