When you store data in the cloud, do you know who really controls it? In an era of increasing geopolitical tension and growth in digital sovereignty, Dutch research institutes have already begun repatriating sensitive data from US servers to Dutch-controlled storage. This talk explores the hidden risks behind common cloud choices, from legal access by foreign governments to the ethical implications of supporting politically active tech giants. We’ll look at what it means to own your data, how regional storage might not be enough, and what it takes to build an EU-hosted, open-source data platform stack. If you’re a data engineer, architect, or technology leader who cares about privacy, control, and sustainable infrastructure, this talk will equip you with the insight—and motivation—to make different choices.
 talk-data.com
talk-data.com
Topic
Cloud Computing
4055
tagged
Activity Trend
Top Events

AI-Driven Software Testing explores how Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing quality engineering (QE), making testing more intelligent, efficient, and adaptive. The book begins by examining the critical role of QE in modern software development and the paradigm shift introduced by AI/ML. It traces the evolution of software testing, from manual approaches to AI-powered automation, highlighting key innovations that enhance accuracy, speed, and scalability. Readers will gain a deep understanding of quality engineering in the age of AI, comparing traditional and AI-driven testing methodologies to uncover their advantages and challenges. Moving into practical applications, the book delves into AI-enhanced test planning, execution, and defect management. It explores AI-driven test case development, intelligent test environments, and real-time monitoring techniques that streamline the testing lifecycle. Additionally, it covers AI’s impact on continuous integration and delivery (CI/CD), predictive analytics for failure prevention, and strategies for scaling AI-driven testing across cloud platforms. Finally, it looks ahead to the future of AI in software testing, discussing emerging trends, ethical considerations, and the evolving role of QE professionals in an AI-first world. With real-world case studies and actionable insights, AI-Driven Software Testing is an essential guide for QE engineers, developers, and tech leaders looking to harness AI for smarter, faster, and more reliable software testing. What you will learn: • What are the key principles of AI/ML-driven quality engineering • What is intelligent test case generation and adaptive test automation • Explore predictive analytics for defect prevention and risk assessment • Understand integration of AI/ML tools in CI/CD pipelines Who this book is for: Quality Engineers looking to enhance software testing with AI-driven techniques. Data Scientists exploring AI applications in software quality assurance and engineering. Software Developers – Engineers seeking to integrate AI/ML into testing and automation workflows.

Unlock the full financial potential of your Snowflake environment. Learn how to cut costs, boost performance, and take control of your cloud data spend with FinOps for Snowflake—your essential guide to implementing a smart, automated, and Snowflake-optimized FinOps strategy. In today’s data-driven world, financial optimization on platforms like Snowflake is more critical than ever. Whether you're just beginning your FinOps journey or refining mature practices, this book provides a practical roadmap to align Snowflake usage with business goals, reduce costs, and improve performance—without compromising agility. Grounded in real-world case studies and packed with actionable strategies, FinOps for Snowflake shows how leading organizations are transforming their environments through automation, governance, and cost intelligence. You'll learn how to apply proven techniques for architecture tuning, workload and storage efficiency, and performance optimization—empowering you to make smarter, data-driven decisions. What You Will Learn Master FinOps principles tailored for Snowflake’s architecture and pricing model Enable collaboration across finance, engineering, and business teams Deliver real-time cost insights for smarter decision-making Optimize compute, storage, and Snowflake AI and ML services for efficiency Leverage Snowflake Cortex AI and Adoptive Warehouse/Compute for intelligent cost governance Apply proven strategies to achieve operational excellence and measurable savings Who this Book is For Data professionals, cloud engineers, FinOps practitioners, and finance teams seeking to improve cost visibility, operational efficiency, and financial accountability in Snowflake environments.
Summary In this episode Kate Shaw, Senior Product Manager for Data and SLIM at SnapLogic, talks about the hidden and compounding costs of maintaining legacy systems—and practical strategies for modernization. She unpacks how “legacy” is less about age and more about when a system becomes a risk: blocking innovation, consuming excess IT time, and creating opportunity costs. Kate explores technical debt, vendor lock-in, lost context from employee turnover, and the slippery notion of “if it ain’t broke,” especially when data correctness and lineage are unclear. Shee digs into governance, observability, and data quality as foundations for trustworthy analytics and AI, and why exit strategies for system retirement should be planned from day one. The discussion covers composable architectures to avoid monoliths and big-bang migrations, how to bridge valuable systems into AI initiatives without lock-in, and why clear success criteria matter for AI projects. Kate shares lessons from the field on discovery, documentation gaps, parallel run strategies, and using integration as the connective tissue to unlock data for modern, cloud-native and AI-enabled use cases. She closes with guidance on planning migrations, defining measurable outcomes, ensuring lineage and compliance, and building for swap-ability so teams can evolve systems incrementally instead of living with a “bowl of spaghetti.”
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data managementData teams everywhere face the same problem: they're forcing ML models, streaming data, and real-time processing through orchestration tools built for simple ETL. The result? Inflexible infrastructure that can't adapt to different workloads. That's why Cash App and Cisco rely on Prefect. Cash App's fraud detection team got what they needed - flexible compute options, isolated environments for custom packages, and seamless data exchange between workflows. Each model runs on the right infrastructure, whether that's high-memory machines or distributed compute. Orchestration is the foundation that determines whether your data team ships or struggles. ETL, ML model training, AI Engineering, Streaming - Prefect runs it all from ingestion to activation in one platform. Whoop and 1Password also trust Prefect for their data operations. If these industry leaders use Prefect for critical workflows, see what it can do for you at dataengineeringpodcast.com/prefect.Data migrations are brutal. They drag on for months—sometimes years—burning through resources and crushing team morale. Datafold's AI-powered Migration Agent changes all that. Their unique combination of AI code translation and automated data validation has helped companies complete migrations up to 10 times faster than manual approaches. And they're so confident in their solution, they'll actually guarantee your timeline in writing. Ready to turn your year-long migration into weeks? Visit dataengineeringpodcast.com/datafold today for the details.Your host is Tobias Macey and today I'm interviewing Kate Shaw about the true costs of maintaining legacy systemsInterview IntroductionHow did you get involved in the area of data management?What are your crtieria for when a given system or service transitions to being "legacy"?In order for any service to survive long enough to become "legacy" it must be serving its purpose and providing value. What are the common factors that prompt teams to deprecate or migrate systems?What are the sources of monetary cost related to maintaining legacy systems while they remain operational?Beyond monetary cost, economics also have a concept of "opportunity cost". What are some of the ways that manifests in data teams who are maintaining or migrating from legacy systems?How does that loss of productivity impact the broader organization?How does the process of migration contribute to issues around data accuracy, reliability, etc. as well as contributing to potential compromises of security and compliance?Once a system has been replaced, it needs to be retired. What are some of the costs associated with removing a system from service?What are the most interesting, innovative, or unexpected ways that you have seen teams address the costs of legacy systems and their retirement?What are the most interesting, unexpected, or challenging lessons that you have learned while working on legacy systems migration?When is deprecation/migration the wrong choice?How have evolutionary architecture patterns helped to mitigate the costs of system retirement?Contact Info LinkedInParting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.init covers the Python language, its community, and the innovative ways it is being used. The AI Engineering Podcast is your guide to the fast-moving world of building AI systems.Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.If you've learned something or tried out a project from the show then tell us about it! Email [email protected] with your story.Links SnapLogicSLIM == SnapLogic Intelligent ModernizerOpportunity CostSunk Cost FallacyData GovernanceEvolutionary ArchitectureThe intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA
Hear how EF (Education First) modernized its data stack from a legacy SQL Server-based environment to a modern Snowflake and dbt-based data stack. Find out what challenges and key decisions were handled during the process, and learn how to incorporate some of their key takeaways into your work.

Fifth Third Bank transformed its MLOps using a feature store built with dbt Cloud. The result? Improved model governance, reduced risk and faster product innovation. In this session, learn how they defined features, automated pipelines and delivered real-time and historical feature views.

Platform engineers from global pharmaceutical company invites you to explore our journey in creating a Cloud native, Federated Data Platform using dbt Cloud, Snowflake, and Data Mesh. Discover how we established foundational tools, standards, and developed automation and self-service capabilities.
Brought to You By: • Statsig — The unified platform for flags, analytics, experiments, and more. Something interesting is happening with the latest generation of tech giants. Rather than building advanced experimentation tools themselves, companies like Anthropic, Figma, Notion and a bunch of others… are just using Statsig. Statsig has rebuilt this entire suite of data tools that was available at maybe 10 or 15 giants until now. Check out Statsig. • Linear – The system for modern product development. Linear is just so fast to use – and it enables velocity in product workflows. Companies like Perplexity and OpenAI have already switched over, because simplicity scales. Go ahead and check out Linear and see why it feels like a breeze to use. — What is it really like to be an engineer at Google? In this special deep dive episode, we unpack how engineering at Google actually works. We spent months researching the engineering culture of the search giant, and talked with 20+ current and former Googlers to bring you this deepdive with Elin Nilsson, tech industry researcher for The Pragmatic Engineer and a former Google intern. Google has always been an engineering-driven organization. We talk about its custom stack and tools, the design-doc culture, and the performance and promotion systems that define career growth. We also explore the culture that feels built for engineers: generous perks, a surprisingly light on-call setup often considered the best in the industry, and a deep focus on solving technical problems at scale. If you are thinking about applying to Google or are curious about how the company’s engineering culture has evolved, this episode takes a clear look at what it was like to work at Google in the past versus today, and who is a good fit for today’s Google. Jump to interesting parts: (13:50) Tech stack (1:05:08) Performance reviews (GRAD) (2:07:03) The culture of continuously rewriting things — Timestamps (00:00) Intro (01:44) Stats about Google (11:41) The shared culture across Google (13:50) Tech stack (34:33) Internal developer tools and monorepo (43:17) The downsides of having so many internal tools at Google (45:29) Perks (55:37) Engineering roles (1:02:32) Levels at Google (1:05:08) Performance reviews (GRAD) (1:13:05) Readability (1:16:18) Promotions (1:25:46) Design docs (1:32:30) OKRs (1:44:43) Googlers, Nooglers, ReGooglers (1:57:27) Google Cloud (2:03:49) Internal transfers (2:07:03) Rewrites (2:10:19) Open source (2:14:57) Culture shift (2:31:10) Making the most of Google, as an engineer (2:39:25) Landing a job at Google — The Pragmatic Engineer deepdives relevant for this episode: • Inside Google’s engineering culture • Oncall at Google • Performance calibrations at tech companies • Promotions and tooling at Google • How Kubernetes is built • The man behind the Big Tech comics: Google cartoonist Manu Cornet — Production and marketing by https://penname.co/. For inquiries about sponsoring the podcast, email [email protected].
Get full access to The Pragmatic Engineer at newsletter.pragmaticengineer.com/subscribe

CHG Healthcare migrated 2000+ legacy MySQL jobs to dbt Cloud and Snowflake in record time. We'll share how Datafold used their AI-powered Migration Agent to migrate and refactor convoluted legacy code into dbt Cloud and Snowflake with full automatic validation, dramatically accelerating our modernization.

The data world has long been divided, with data engineers and data scientists working in silos. This fragmentation creates a long, difficult journey from raw data to machine learning models. We've unified these worlds through the Google Cloud and dbt partnership. In this session, we'll show you an end-to-end workflow that simplifies data to AI journey. The availability of dbt Cloud on Google Cloud Marketplace streamlines getting started, and its integration with BigQuery's new Apache Iceberg tables creates an open foundation. We'll also highlight how BigQuery DataFrames' integration with dbt Python models lets you perform complex data science at scale, all within a single, streamlined process. Join us to learn how to build a unified data and AI platform with dbt on Google Cloud.
How AI can help maintain compliance and resilience in cloud security on AWS.
Discussion on predicting security threats in AWS cloud environments using AI insights.

Unveil the data platform of the future with SQL Server 2025—guided by one of its key architects . With built-in AI for application development and advanced analytics powered by Microsoft Fabric, SQL Server 2025 empowers you to innovate—securely and confidently. This book shows you how. Author Bob Ward, Principal Architect for the Microsoft Azure Data team, shares exclusive insights drawn from over three decades at Microsoft. Having worked on every version of SQL Server since OS/2 1.1, Ward brings unmatched expertise and practical guidance to help you navigate this transformative release. Ward covers everything from setup and upgrades to advanced features in performance, high availability, and security. He also highlights what makes this the most developer-friendly release in a decade: support for JSON, RegEx, REST APIs, and event streaming. Most critically, Ward explores SQL Server 2025’s advanced, scalable AI integrations, showing you how to build AI-powered applications deeply integrated with the SQL engine—and elevate your analytics to the next level. But innovation doesn’t come at the cost of safety: this release is built on a foundation of enterprise-grade security, helping you adopt AI safely and responsibly. You control which models to use, how they interact with your data, and where they run—from ground to cloud, or integrated with Microsoft Fabric. With built-in features like Row-Level Security (RLS), Transparent Data Encryption (TDE), Dynamic Data Masking, and SQL Server Auditing, your data remains protected at every layer. The AI age is here. Make sure your SQL Server databases are ready—and built for secure, scalable innovation . What You Will Learn [if !supportLists] · [endif]Grasp the fundamentals of AI to leverage AI with your data, using the industry-proven security and scale of SQL Server [if !supportLists] · [endif]Utilize AI models of your choice, services, and frameworks to build new AI applications [if !supportLists] · [endif]Explore new developer features such as JSON, Regular Expressions, REST API, and Change Event Streaming [if !supportLists] · [endif]Discover SQL Server 2025's powerful new engine capabilities to increase application concurrency [if !supportLists] · [endif]Examine new high availability features to enhance uptime and diagnose complex HADR configurations [if !supportLists] · Use new query processing capabilities to extend the performance of your application [if !supportLists] · [endif]Connect SQL Server to Azure with Arc for advanced management and security capabilities [if !supportLists] · [endif]Secure and govern your data using Microsoft Entra [if !supportLists] · [endif]Achieve near-real-time analytics with the unified data platform Microsoft Fabric [if !supportLists] · [endif]Integrate AI capabilities with SQL Server for enterprise AI [if !supportLists] · [endif]Leverage new tools such as SQL Server Management Studio and Copilot experiences to assist your SQL Server journey Who This Book Is For The SQL Server community, including DBAs, architects, and developers eager to stay ahead with the latest advancements in SQL Server 2025, and those interested in the intersection of AI and data, particularly how artificial intelligence (AI) can be seamlessly integrated with SQL Server to unlock deeper insights and smarter solutions

Generative AI has the potential to innovate and evolve business processes, but workers are still figuring out how to build with, optimize, and prompt GenAI tools to fit their needs. And of course, there are pitfalls to avoid, like security risks and hallucinations. Getting it right requires an intuitive understanding of the technology’s capabilities and limitations. This approachable guidebook helps learners of all levels navigate GenAI—and have fun while doing it. Loaded with insightful diagrams and illustrations, Visualizing Generative AI is the perfect entry point for curious IT professionals, business leaders who want to stay on top of the latest technologies, students exploring careers in cloud computing and AI, and anyone else interested in getting started with GenAI. You’ll traverse the generative AI landscape, exploring everything from how this technology works to the ways organizations are already leveraging it to great success. Understand how generative AI has evolved, with a focus on major breakthroughs Get acquainted with the available tools and platforms for GenAI workloads Examine real-world applications, such as chatbots and workflow automation Learn fundamentals that you can build upon as you continue your GenAI journey
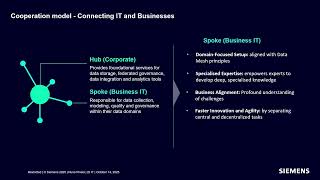
Siemens Data Cloud runs over 1500 dbt Platform projects across teams and domains. But more projects can mean more silos and less visibility. Because dbt is designed to be project-scoped, getting a birds-eye view isn’t easy. That’s where the dbt Platform Admin API comes in. We’ll show how we used it to extract metadata and build a unified monitoring dashboard. You’ll learn how to track deployments, spot anomalies, and compare project health across your dbt landscape.
From a toddler discovering WiFi to century-old train tracks to the cloud revolution, an engineer with art and philosophy background traces the invisible infrastructure that shapes everything. A philosophical journey into why the work we do matters more than we think.
Cloud automation is powerful but tricky. This talk explores its evolution—from scripts and policies to AI-driven agents—and reveals a three-phase framework for practical adoption. Attendees will learn what to automate, how AI changes the game, and which risks, standards, and strategies shape the next generation of CloudOps
Cloud automation is powerful but tricky. This talk explores its evolution—from scripts and policies to AI-driven agents—and reveals a three-phase framework for practical adoption. Attendees will learn what to automate, how AI changes the game, and which risks, standards, and strategies shape the next generation of CloudOps
In the last few months, I’ve been working hard to onboard new data and analytics engineers. Along the way, I’ve learned which parts of dbt and dbt Cloud are hard to teach, what confuses people, and where tools or training fall short. I’d like to swap ideas and hear how others are handling this.
In this course, learn how to manage and monitor data platform costs using dbt's built-in tools. We’ll cover how to surface warehouse usage data, set up basic monitoring, and apply rule-based recommendations to optimize performance. You’ll also explore how cost insights fit naturally into the developer workflow—equipping you to make smarter decisions without leaving dbt. This course is for analytics engineers, data analysts, and data platform owners who have a foundational understanding of dbt and want to build more cost-effective data pipelines. Using these cost management and orchestration strategies, the internal dbt Labs Analytics team achieved significant savings: Our cloud compute bill was reduced by 9% by simply implementing dbt Fusion and state-aware orchestration. By understanding the impact of models on platform costs, the team reduced the number of models built in scheduled jobs by 35% and shaved 20% off of job execution times. After this course, you will be able to: Articulate how dbt development patterns impact data platform costs. Configure dbt Cloud to monitor warehouse compute spend. Use the dbt Cost Management dashboard to identify high-cost models and jobs. Apply specific optimization techniques, from materializations to advanced data modeling patterns, to reduce warehouse costs. Implement proactive strategies like dbt Fusion and state-aware orchestration to prevent future cost overruns. Prerequisites for this course include: dbt fundamentals What to bring: You will need to bring your own laptop to complete the hands-on exercises. We will provide all the other sandbox environments for dbt and data platform. Duration: 2 hours Fee: $200 Trainings and certifications are not offered separately and must be purchased with a Coalesce pass Trainings and certifications are not available for Coalesce Online passes